声明:本文来自于微信公众号 新智元(ID:AI_era),作者:新智元,授权热心网友转载发布。
【新智元导读】近日,《连线》杂志联合ProofNews联合发表一篇调查文章,指责苹果、Anthropic等科技巨头未经许可使用YouTube视频训练AI模型。但训练数据的使用边界究竟在哪里?创作者、大公司和开发者正在陷入知识产权的罗生门……
AI科技巨头的「数据荒」到底该拿什么拯救?
为了训练生成式AI,尤其是在scalling law的支配之下,互联网上现存的内容早已不能满足LLM越来越大的胃口,It's soooo hungry for data!
「数据荒」的直接结果,就是科技巨头对GenAI的训练数据越来越「饥不择食」。
不仅仅是书籍、文章,甚至Instagram、X、Fackbook等各种社交平台上的内容也是来者不拒。
前段时间和OpenAI签合作协议,而且坑了谷歌搜索、导致Gemini教唆网友给披萨加胶水的Reddit也是其中之一。
为了规避潜在的法律纠纷,GPT、Gemini、Claude等商业模型在发布时往往选择对训练数据「三缄其口」,绝口不提及其来源、构成、使用许可等信息。
然而,这个问题早就引起了创作者和各种媒体平台越来越强烈的不满。
近日,Anthropic、英伟达、苹果和Salesforce等公司再次身陷「数据门」,遭受到《连线》杂志和非营利新闻工作室ProofNews的猛烈攻击。
两家媒体联合进行了一项调查,发现这些科技巨头们大量窃取了Youtube上的视频字幕用于训练,使用了共计超过4.8万个频道的17.4万个视频。
ProofNews甚至制作了一个在线搜索工具,对这种行为进行持续的「公开处刑」。哪些创作者和视频被偷偷纳入数据库,一搜就知道。

网页地址:https://www.proofnews.org/youtube-ai-search/
追根溯源,这些数据指向一个共同来源——Eleuther AI在2020年发布的数据集Pile。
作为非营利组织,Eleuther AI建立Pile项目的初衷本是为了帮助小型组织和研究人员,促进AI研究的民主化,没想到最后也成为了大公司的囊中之物。
这正是事情的吊诡之处——本来是为反巨头而生的「Pile」反而让巨头用得不亦乐乎。
一边是怨声载道的创作者,不满科技巨头又用数据、又抢饭碗的粗暴行径;另一边是宣扬着伟大AGI愿景的科技巨头。
像EleutherAI这样辛辛苦苦爬数据还开源的NPO,怀抱着促进数据共享和技术公平的初衷,结果只落得被大公司利用、被创作者批判的境地。
Pile:有罪的开源?
ProofNews和《连线》杂志将主要矛头对准了Eleuther AI在2020年发布的大型开源文本数据集Pile。
文章愤怒地指出,Pile不仅包括YouTube字幕,还有来自欧洲议会、英语维基百科的语料,甚至还有安然(Enron)公司员工的大量电子邮件。
然而,Pile数据集的论文本身却给我们呈现出完全不一样的图景。

论文地址:https://arxiv.org/abs/2101.00027
这篇将近40页的论文不仅详细披露了共825GB文本数据的全部22个来源,还详细讨论了数据收集应当遵循的原则和广泛影响。
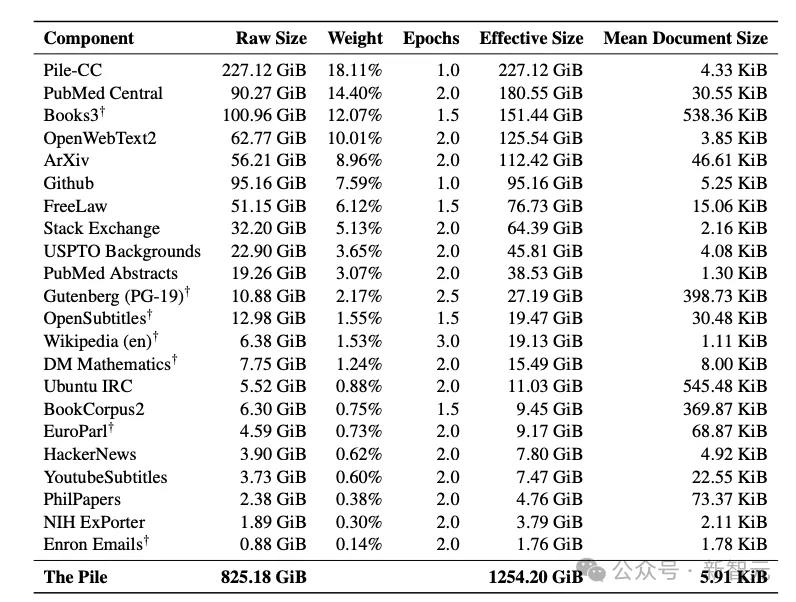
从上图中可以看到,处于争议焦点的两个数据集——YoutubeSubtitles和Enron Emails被公开列了出来。
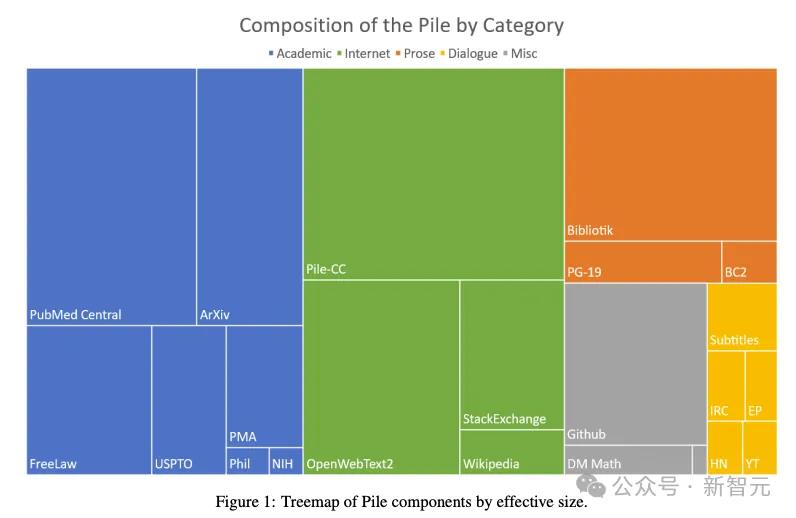
下面的树状图中,也没有避讳「字幕」类数据的使用,反而是在佐证数据集内容的多样性。
为什么Eleuther AI的研究团队能这么毫不心虚?
首先,Enron Emails是美国联邦政府对该公司进行调查期间发布到网上的,已经作为公开数据集被使用多年,因此不存在我们想象中的隐私泄露问题。
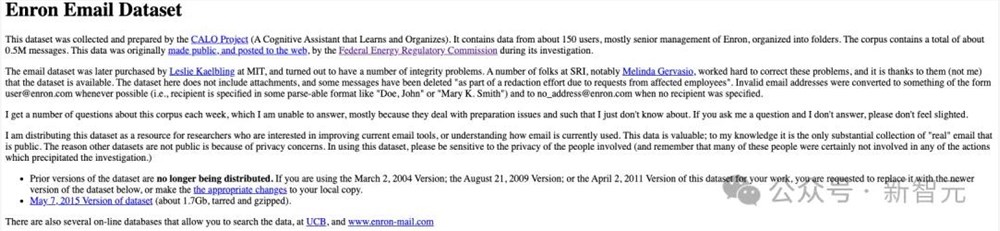
https://www.cs.cmu.edu/~enron/
其次,作者团队对Youtube字幕数据的使用也做出了充分的说明和讨论。
所有数据集的可用性被分为三类:
- 公开数据:网络上完全免费、公开的数据,没有任何访问障碍
- 符合服务条款(ToS)的数据:数据的获得和使用符合服务条款的相关要求
- 得到作者许可的数据:原作者已经同意对数据的使用
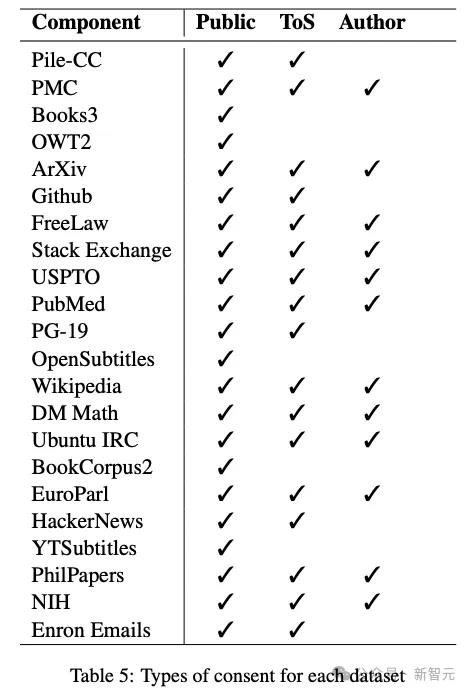
如表5所示,22个数据集中,仅有5个数据集没有得到ToS许可,但在NLP社区中,除了YoutubeSubtitles外的其他4个都已经被广泛传播并使用。
对于YoutubeSubtitles本身,作者在抓取数据时使用了一个非官方API,并进行了大量数据处理工作。而且,这个AP工具在Pip、Conda、GitHub等平台上都很流行且能极易取得。
「API流行且极易取得」,意味着相关数据的广泛传播和使用也许已经是既成事实。
「大量处理工作」似乎是暗示,这个数据集并非只包含视频创作者的心血,同时也凝结了论文作者的技术知识和劳动。
因此,论文中有这样一句总结性陈述:
Given the processing applied and the difficulty of identifying particular files in the Pile, we feel that our use of these datasets does not constitute significantly increased harm beyond that which has already been done by the widespread publication of these datasets.
考虑到所采用的处理方法,以及在Pile中识别特定文件的难度,我们认为,基于这些数据集目前的大范围公布,我们的使用并不会显著增加其危害。
除了可用性讨论,作者也用了不少篇幅指出Pile中包含的有害内容,比如性别、种族、宗教等方面的偏见,以及亵渎或贬损类话语。
此外,研究团队还公开了数据集全部内容,以及预训练所用的代码。

https://pile.eleuther.ai/
https://github.com/EleutherAI/the-pile?tab=readme-ov-file
除了建立数据集,论文也提出了将Pile作为基准测试的可能,并在对GPT-2和GPT-3的实验中,揭示了文本数据多样性对模型性能的影响。
综合上述内容,站在AI技术人的角度,Eleuther AI的这篇论文不仅无过,而且可以称得上是非常负责且有贡献的研究。
然而,Pile自从发布后就惹上了一身麻烦,各种诉讼案件接踵而来。
目前,Eleuther的官方网站已经将Pile数据集删除,但它凭借自己强大的历史影响,依旧在AI/ML社区广泛流传。

倒下了一个Pile,后来的开源数据集还会继续站起来。
上图中提到的BigCode项目如此,NLP社区广为人知的Common Crawl也是如此。
这个非营利组织从2007年开始抓取网页数据,坚持至今,收集网页数量超过2500亿。
据Hacker News网友估计,总数据量大概以每月200~300TB的速度稳定增长,可能已经累积到数十甚至数百PB。
与Pile的命运不同,CC数据集安然存活至今。这些数据都托管在亚马逊云平台上,可以通过命令行直接下载。

https://commoncrawl.org/get-started
创作者:请停止剥削
虽然在AI从业者的眼中,对Pile的指责有些过分苛责,但对于Youtube创作者而言,他们的愤怒和无奈也是真实的。
ProofNews的调查发现,被Pile搜刮的创作者中不乏粉丝千万的YouTube网红,甚至一些官方账号也未能幸免。
YouTube Subtitles数据集中,不仅包含可汗学院、哈佛、MIT等在线教育频道的视频转录字幕,还有《华尔街日报》、NPR、BBC等媒体的新闻视频,Stephen Colbert、Jimmy Kimmel等人主持的风靡全美的脱口秀节目也赫然在列。
在创作者眼中,没有经过本人同意就抓取创作内容用于训练AI,实质上是一种剽窃,甚至剥削。
David Pakman是自己同名脱口秀节目的主持人,拥有200多万订阅者,浏览量超过20亿次。
YouTube Subtitle数据集中,收录了该节目的近160个视频。但更让Pakman感到愤怒的是,他发现自己在TikTok上被「克隆」了。
Pakman自己曾经说过的台词被一字不差地挪用,甚至连语调都一样,只不过换成了一个叫作Tucker Carlson的人。更让他震惊的是,评论区居然只有一个人发现了这一点。
Pakman对此忿忿不平:「这是我的生计,我投入了时间、资源、金钱和员工的时间来制作这些内容」。
他认为,如果人工智能公司从「克隆」中盈利,那么自己也应该获得报酬。
Nebula的首席执行官Dave Wiskus则说得更加露骨:「这是盗窃行为」。
Nebula是一家流媒体公司,其内容同样也被大公司从YouTube上盗用,用于训练人工智能。
Wiskus表示,未经创作者同意就使用他们的作品是「不尊重」他们的行为,尤其是「生成式人工智能会尽可能多地取代艺术家」。
「这绝对是对艺术家的严重伤害和剥削!」
孤立无援的创作者对未来的道路感到十分迷茫,心中充满了不确定。
一些全职YouTube用户会巡查他们的作品是否被未经授权使用,定期提交删除通知,不能心无旁骛地创作。
即便如此,他们还是被焦虑笼罩,担心AI能够生成与他们制作的内容类似的内容只是时间问题。
通过YouTube可以快速学习人类说话的方式和习惯,这件事好理解,可关键是AI它什么都学啊!
ProofNews发现,AI公司使用的视频中有146个来自Einstein Parrot,这个账号有15万粉丝,但博主的身份是一只非洲灰鹦鹉。
鹦鹉模仿人类说话,然后AI再模仿鹦鹉模仿人类说话,然后人类每天跟AI聊天机器人说话,开始模仿AI……闭环了,朋友们。
大公司:用开源,我错了么
除了爬取的视频数据翻个底朝天,ProofNews还搬出了大公司使用Pile来训练人工智能的「铁证」——
苹果4月份发布了一个备受瞩目的模型OpenELM,在论文当中就提及了Pile。

论文地址:https://machinelearning.apple.com/research/openelm
可是苹果也很委屈,表示OpenELM模型的目的是为研究社区作贡献,推动开源LLM的发展。
Anthropic也是如此,其发言人Jennifer Martinez在一份声明中证实,Claude确实使用了Pile数据集,但是关于侵权问题,她表示「我们必须请教Pile的作者」。
Salesforce也确认,他们使用了Pile来构建用于「学术和研究目的」的人工智能模型,但公司人工智能研究副总裁Caiming Xiong在声明中强调,Pile是「公开」数据集,因此他们的使用无可指摘。
实际上,盯上Youtube这个「数据金矿」的科技巨头远不止这几家。
今年4月,纽约时报就披露了OpenAI、谷歌、Meta等公司「收割」Youtube数据的情况。

https://www.nytimes.com/2024/04/06/technology/tech-giants-harvest-data-artificial-intelligence.html
比如OpenAI创建了一款名为Whisper的语音识别工具,用于将Youtube视频转录为文本,用作训练数据。
拥有Youtube平台的谷歌则可以理直气壮的表示,使用平台上的视频内容进行模型训练,这是是与创作者达成的条款中所允许的。
硅谷风投公司Andreessen Horowitz的律师Sy Damle表示,「模型所需的数据如此庞大,即使是集体许可也确实行不通。」
在这个未形成共识的灰色地带,似乎所有利益相关方都在困境中,但所有人都无解。
从小型组织、研究者,到Eleuther AI这样的NPO,再到科技巨头,「数据墙」的威胁近在眼前。要想跟上技术发展的节奏,就得竭尽所能利用一切数据来源。
内容创作者们,则眼看着自己的心血创意变成反噬自己的强大力量,想要阻止却收效甚微。
我们正在踏入一种未知,或许只有未来才能给出答案。
参考资料:
https://arstechnica.com/ai/2024/07/apple-was-among-the-companies-that-trained-its-ai-on-youtube-videos/
https://www.proofnews.org/apple-nvidia-anthropic-used-thousands-of-swiped-youtube-videos-to-train-ai/
https://www.wired.com/story/youtube-training-data-apple-nvidia-anthropic/
(举报)








发表评论取消回复