声明:本文来自于微信公众号 新智元,作者:新智元,授权热心网友转载发布。
最近,提升多模态大模型处理高分辨率图像的能力越来越引起这个领域的关注。
绝大多数方法致力于通过对图像进行切分再融合的策略,来提升多模态大模型对图像细节的理解能力。
然而,由于对图像的切分操作,不可避免会对目标、联通区域带来割裂,导致MLMMs对于微小或形状不规则的目标的辨识能力。这个现象在文档理解任务中,表现极为明显,由于文字端经常被中断。
针对这一挑战,华中科技大学和华南理工大学最近联合发布一个多模态大模型Mini-Monkey,使用了可插拔的多尺度自适应策略(MSAC)的轻量化多模态大模型。
Mini-Monkey自适应生成多尺度表示,允许模型从各种尺度中选择未分割的对象,其性能达到了2B多模态大模型的新SOTA。

论文地址:https://arxiv.org/pdf/2408.02034
项目地址:https://github.com/Yuliang-Liu/Monkey
为了减轻MSAC带来的计算开销,我们提出了一种有效压缩图像令牌的尺度压缩机制(SCM)。
Mini-Monkey不仅在文档智能的多个任务上取得了领先的性能,在通用多模态模型理解任务上也取得了一致的性能的提升,取得了2B的SOTA性能。
在OCRBench上,Mini-Monkey获得了802分,优于GLM-4v-9B等更大参数量的模型。
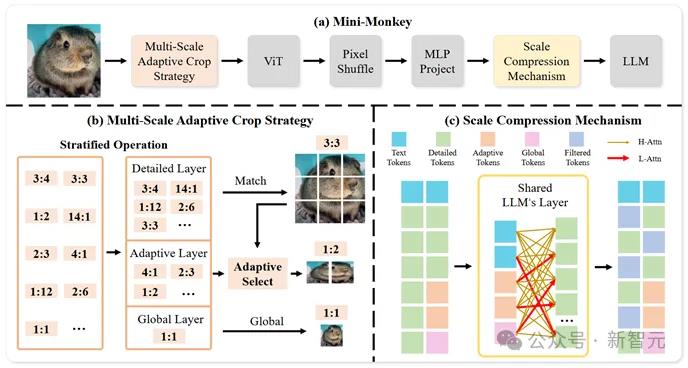
图3方法框图:H-Attn代表高注意力权;L-Attn代表低注意权重;注意权重较低的令牌将被过滤;共享LLM层表示在SCM中使用LLM的块层
研究背景
多模态大型语言模型(MLMM)在近年了引起了很大的关注。研究人员正在积极探索将视觉编码器与LLM集成的有效方法。
一些方法,如Flamingo、BLIP-2、MiniGPT4和Qwen-VL和LLaVA等已经取得了这些成就,但由于处理分辨率有限,以前的多模态大语言模型并没有很好地实现详细的场景理解。

图1切分在通用物体上引起的锯齿效应:(a)输入图像;(b)切分扩大分辨率策略;(c)有重叠的切分扩大分辨率策略;(d)多尺度适应性切分策略
研究者开始通过扩大图像的输入分辨率来解决这个问题。切分策略是最常用的方法之一。例如,Monkey,LLaVA1.6,InternVL1.5和LLama3-V等。
尽管多模态大型语言模型取得了重大进展,但由于切分策略,在详细场景理解方面仍然存在挑战。
对图像的切分操作不可避免地会分割物体和连接区域,从而削弱了MLLM识别小物体或不规则形状物体的能力,特别是在文档理解的背景下。
这种策略将引入两种类型的语义不连贯:
1. 如果一个对象或字符被分割,它可能无法被识别。例如,切分后的鼻子看起来非常像猴子,如图1(b)所示;
2. 如果对一个词或句子进行分词,会造成被分词的语义损害。例如,单词「Classrooms」可能被分为「Class」和「rooms」,这会对分割后的单词造成语义损害。
为简单起见,作者称这个问题为锯齿效应。一个非常直接的想法是采用重叠切分策略来解决这个问题,如图1(c)所示。
然而,作者发现重叠切分策略引入了某些幻觉,导致性能下降而不是提高。
方法思路
作者提出了Mini-Monkey,一个轻量级的多模态大型语言模型,旨在减轻切分策略引起的锯齿效应。方法框图如图2所示。

图2裁切在文字图像上引起的锯齿效应。
与直接切分输入图像的现有方法不同,Mini-Monkey采用了一种即插即用的方法称为多尺度自适应切分策略(MSAC)。
MSAC可以在不同尺度的特征之间进行有效的互补,如图1(d)所示。
多尺度自适应切分策略(MSAC)
MSAC先对这些网格进行分层操作,根据它们的纵横比将它们分成三组。作者将为每个图层选择一个宽高比。不同的分层为模型提供不同的信息。
详细层负责提供详细信息。它既限制了最大图像分辨率和最小图像分辨率,使图像尽可能大,使图像中的物体更清晰。由于使用了切分策略来剪裁图像,该层生成的图像可能存在语义不一致。
因此,作者利用自适应层与细节层协同,使模型能够从各种尺度中选择未分割的对象。自适应层将根据细节层自适应生成纵横比,确保细节层上的切分线与自适应层上的切分线不重叠,进而避免了同一个物体在不同层上被切分两次。这个过程确保了细节层和自适应层为模型提供了不同的语义信息和视觉特征。
尺度压缩机制
MSAC可能会引入一些额外的计算开销。因此,作者提出了一种尺度压缩机制(SCM),用于有计算开销限制的情况。SCM是一个不用训练并且无参数的机制,以减少计算开销。
作者选择自适应层的视觉Tokens、全局层的视觉Tokens和文本Tokens来关注细节层的视觉标记,进而生成注意力图,然后将注意力图Top K的视觉特征提取出来。
一个训练好的LLM可以根据输入问题有效地选择必要的视觉特征。因此,SCM利用LLM的第一层和第二层来选择视觉Tokens,而不生成任何额外的参数。
Mini-Monkey最强2B多模态大模型
作者在通用多模态理解和文档理解上测试了他们的方法,实验结果表明,Mini-Monkey在2B参数量的情况下,同时在通用多模态理解和文档理解上取得了最好的性能。
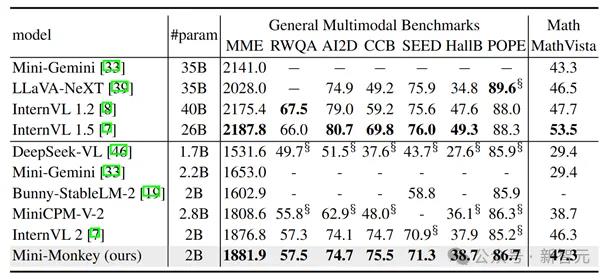
表1通用多模态理解上的结果
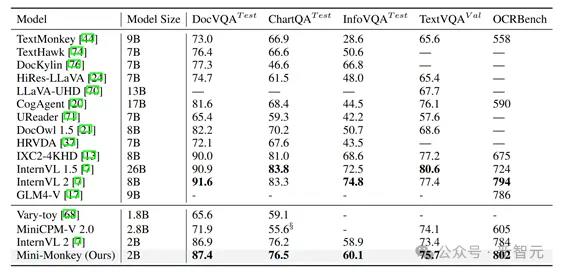
表2文档理解上的结果
作者将提出的MSAC和现有的方法对比,第一行是动态切分的方法,第二行是固定分辨率切分的方法,第三行是有重叠的切分,第四行是多尺度策略S2。

表3与不同的切分策略进行对比
MSAC可以应用到不同的多模态架构上,稳定提点
同时作者也将MSAC应用到其他的方法进行对比,可以看到同时在通用多模态理解和文档理解任务上都有一致的提升。

表4将MSAC应用到不同的框架上
有效缓解由切分增大分辨率导致的「后遗症」
同时作者也提供了一些定性的分析,如图4所示。作者对切分到的位置进行提问,比如被切分到的「classrooms」和「school」。
可以看到,Mini-Monkey通过MSAC可以有效的缓解由切分增大分辨率导致的「后遗症」。
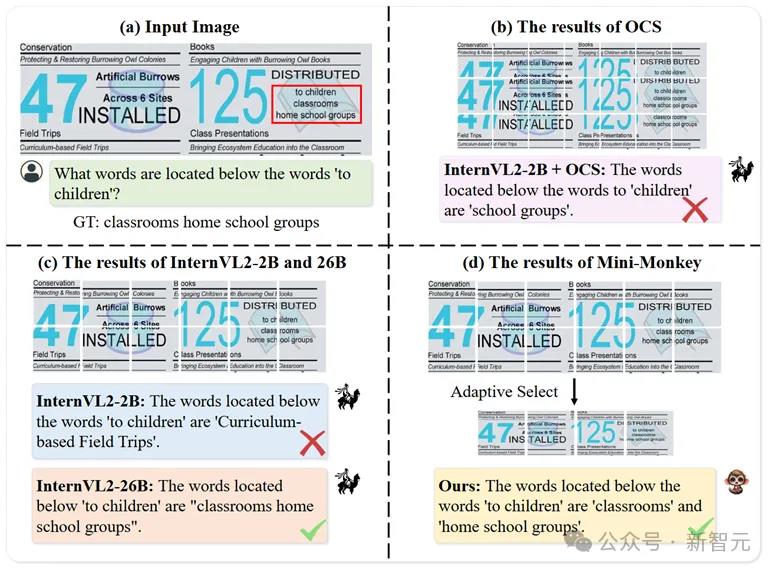
图4定性结果:(a)输入图像和Ground Truth;(b)采用重叠切分策略的结果,OSC表示重叠切分策略;(c)internv2-2b和internv2-26b的结果;(d)Mini-Monkey的结果
可视化对比
Mini-Monkey能准确的提取模糊的古籍里面的文字内容,而MiniCPM-V2.6和InternVL2-2B都漏掉了比较多的文字,GPT4-O拒绝回答:

(a)输入图片
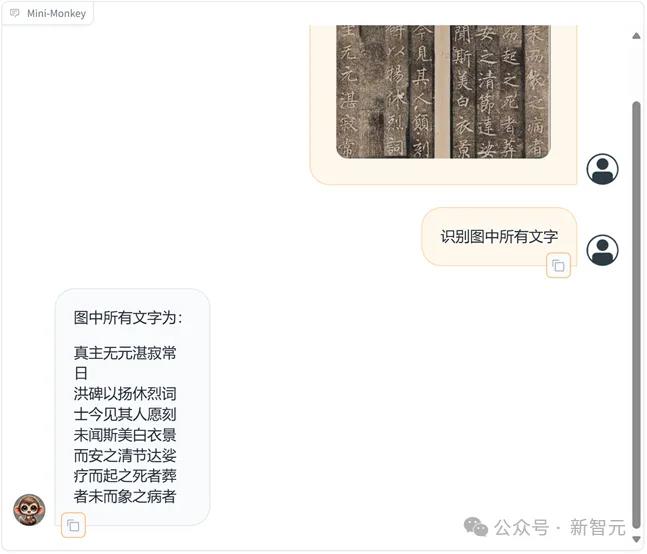
(b)Mimi-Monkey:准确识别出所有文字

(c)MiniCPM-V2.6:漏掉了很多文字。
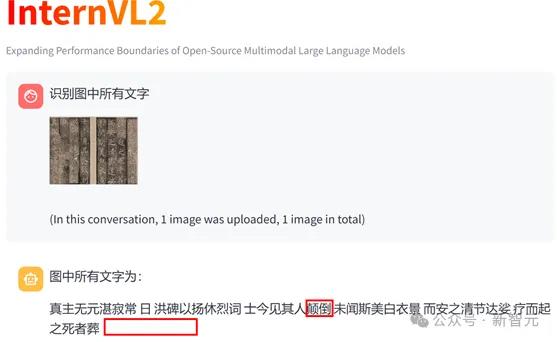
(d)InternVL2-2B:漏掉了一整句比较模糊的文字

(e)GPT-4o:拒绝回答
总结
使用切分扩大分辨率的方法经常分割对象和连接区域,这限制了对小的或不规则形状的对象和文本的识别,这个问题在轻量级的MLLM中尤为明显。
在这项研究中,作者提出了一个取得SOTA性能的2B多模态大模型Mini-Monkey,旨在解决现有切分策略的局限性,以提高MLLM处理高分辨率图像的能力。
Mini-Monkey采用了一种多尺度自适应切分策略(MSAC),生成多尺度表示,允许模型在不同尺度上选择未分割的对象,进而缓解了这个问题。
同时,作者也验证了多尺度自适应切分策略在别的架构的多模态大模型上的有效性,为缓解由切分增大分辨率导致的「后遗症」提供了一种简单有效的解决方案。
(举报)








发表评论取消回复