1:项目背景
搜索、推荐是一个app内容分发的灵魂,关系着能不能把一些优质的内容精准的推送给目标用户。这里面涉及到分词、同义词、停用词、多平台、相关相似度算法、精排等。接下来我综合从多个方向讲讲我对搜索的一些理解。
2:搜索分词
elasticsearch 生态中有很多分词的组件。主要看业务诉求,公司业务的发展。最常用的中分分词器elasticsearch-analysis-ik、elasticsearch-jieba-plugin,一般建议 ik。如果公司的业务发展比较快需要支持多国语言建议了解一下Stanford CoreNLP,支持阿拉伯语,中文,英文,法语,德语,西班牙语。Stanford CoreNLP没有接入elaticsearch 的plugin ,需要自己开发兼容。另外它也支持词性分析、情感分析。相关对比如下:
| 组件介绍 | 使用范围 | 安装方式 |
| elasticsearch-analysis-ik | 支持中文,英文分词,对于中文分词、 停用词可以热更新 | |
| elasticsearch-analysis-dynamic-synonym | 同义词可支持动态更新,支持热更新。 | |
| elasticsearch-jieba-plugin | 暂时没有支持7.2.0版本,先不做发散。详细见:https://github.com/sing1ee/elasticsearch-jieba-plugin | |
| Stanford CoreNLP | 在推荐系统用了stanrdNLP,没有很深入的了解。暂时不支持分词热更新。 https://github.com/godlockin/esStanfordNLPAnalyzer 看到比较好的文件介绍详细见:https://elasticsearch.cn/article/6341 |
综上所述,一般的场景建议用analysis-ik 和 analysis-dynamic-synonym。如果涉及多国语言建议用 Stanford CoreNLP。
3:可插拔的相似度算法
elasticsearch 5.0 版本之前的 TF-IDF 以及 5.0 版本之后的 BM25。TF-IDF 通过衡量一个单词在局部的常见性以及在全局的罕见程度来确定查询的相关性。BM25 是基于 TF-IDF 的,它解决了 TF-IDF 的缺陷,使函数结果与用户的查询更相关。
图来自官网 (点击左边链接可以看官网介绍)
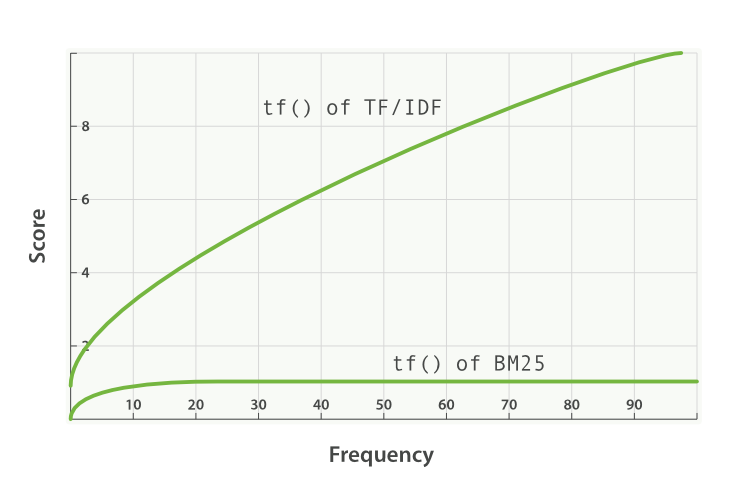
整体的意思:BM25 相对与TF-IDF 更稳定,BM25 还有一个比较好的特性就是它提供了两个可调参数:
| k1 | b |
| 这个参数控制着词频结果在词频饱和度中的上升速度。默认值为 1.2 。值越小饱和度变化越快,值越大饱和度变化越慢。 | 这个参数控制着字段长归一值所起的作用, 0.0 会禁用归一化, 1.0 会启用完全归一化。默认值为 0.75 |
整体建议用bm25做相似度计算,相关的es设置如下:
PUT /bm25_test
{
"settings": {
"number_of_shards" : 1,
"number_of_replicas" : 1,
"index": {
"analysis": {
"filter": {
"cn_synonyms": {
"type": "dynamic_synonym",
"synonyms_path":"http://ip:port/cn_synonyms.txt",
"interval": 30
},
"en_synonyms": {
"type": "dynamic_synonym",
"synonyms_path":"http://ip:port/en_synonyms.txt",
"interval": 30
},
"en_stopwords": {
"type": "stop",
"stopwords_path": "/etc/elasticsearch/en_stopwords.txt"
}
},
"analyzer": {
"cn_fenci": {
"filter": [
"cn_synonyms",
"lowercase"
],
"char_filter": [
"html_strip",
"&_to_and"
],
"type": "custom",
"tokenizer": "ik_max_word"
},
"en_fenci": {
"filter": [
"en_synonyms",
"lowercase",
"en_stopwords"
],
"char_filter": [
"html_strip",
"&_to_and"
],
"type": "custom",
"tokenizer": "standard"
}
},
"char_filter": {
"&_to_and": {
"type": "mapping",
"mappings": [
"&=>and"
]
}
}
}
}
},
"mappings": {
"properties": {
"en_word": {
"type": "text",
"similarity": "BM25",
"analyzer": "en_fenci"
},
"cn_word": {
"type": "text",
"similarity": "BM25",
"analyzer": "cn_fenci"
}
}
}
}4:flink 如何实时更新
1:初始化 elaticsearch sink,批量更新通过bluk load 方式。
public static HttpHost[] loadHostArray(String nodes) {
if (httpHostArray == null) {
String[] split = nodes.split(",");
httpHostArray = new HttpHost[split.length];
for(int i = 0; i < split.length; ++i) {
String item = split[i];
httpHostArray[i] = new HttpHost(item.split(":")[0], Integer.parseInt(item.split(":")[1]), "http");
}
}
return httpHostArray;
}
HttpHost[] httpHosts = this.loadHostArray(esNodes);
ElasticsearchSink.Builder<Doc> esSinkBuilder = new ElasticsearchSink.Builder<>(Arrays.asList(httpHosts), new DocSinkES());
esSinkBuilder.setFailureHandler(new ActionRequestFailureHandler() {
@Override
public void onFailure(ActionRequest action, Throwable failure, int restStatusCode, RequestIndexer indexer) {
if (ExceptionUtils.findThrowable(failure, EsRejectedExecutionException.class).isPresent()) {
// full queue; re-add document for indexing
indexer.add(action);
} else if (ExceptionUtils.findThrowable(failure, ElasticsearchParseException.class).isPresent()) {
// malformed document; simply drop request without failing sink
} else {
// for all other failures, fail the sink
// here the failure is simply rethrown, but users can also choose to throw custom exceptions
LOG.error(failure.getMessage());
}
}
});
esSinkBuilder.setBulkFlushInterval(3000);
esSinkBuilder.setBulkFlushMaxSizeMb(10);
esSinkBuilder.setBulkFlushBackoff(true);
esSinkBuilder.setBulkFlushBackoffRetries(2);
esSink = esSinkBuilder.build();
esSink.disableFlushOnCheckpoint();2:我们目前的场景仅支持单表同步或多个分库分表数据同步。可以设计相关的配置成通用型表,比如es表名、doc_id, dbname, tablename, 同步的数据库字段,过滤的字段等。
SingleOutputStreamOperator<Tuple2<String, Binlog>> filterStream = binlogDataStream.process(new BinlogFilterProcessFunction(new HashSet<>(searchSyncInfos.keySet())));
SingleOutputStreamOperator<Doc> docStream = filterStream.process(new BinlogToDocProcessFunction(searchSyncInfos));
docStream.addSink(esSink);5:总结
elaticsearch 对于中小型公司做搜索完全可以cover所有的场景。如果场景比较复杂的时候,建议先从业务角度思考这样做的意义以及价值。不要急于帮助业务实现,而是要反推业务思考投入产出比。在技术与业务场景上找平衡点。
最后
以上就是顺利酒窝最近收集整理的关于elasticsearch 搜索体系搭建1:项目背景2:搜索分词3:可插拔的相似度算法4:flink 如何实时更新5:总结的全部内容,更多相关elasticsearch内容请搜索靠谱客的其他文章。








发表评论 取消回复