计算棒二代(Neural Compute Stick 2),是2018年因特尔推出的一款用于深度计算的工具,通过使用英特尔®OpenVINO™工具包可以加速运行模型,可以应用在深度学习中。
我采用Pytorch框架编写模型,模型名称为:model.pt,pt文件需要转换为计算棒识别的IR文件,基本思路是pt–》onnx–》IR。然后在onnx–》IR这一步出现了如下问题,在此记录:
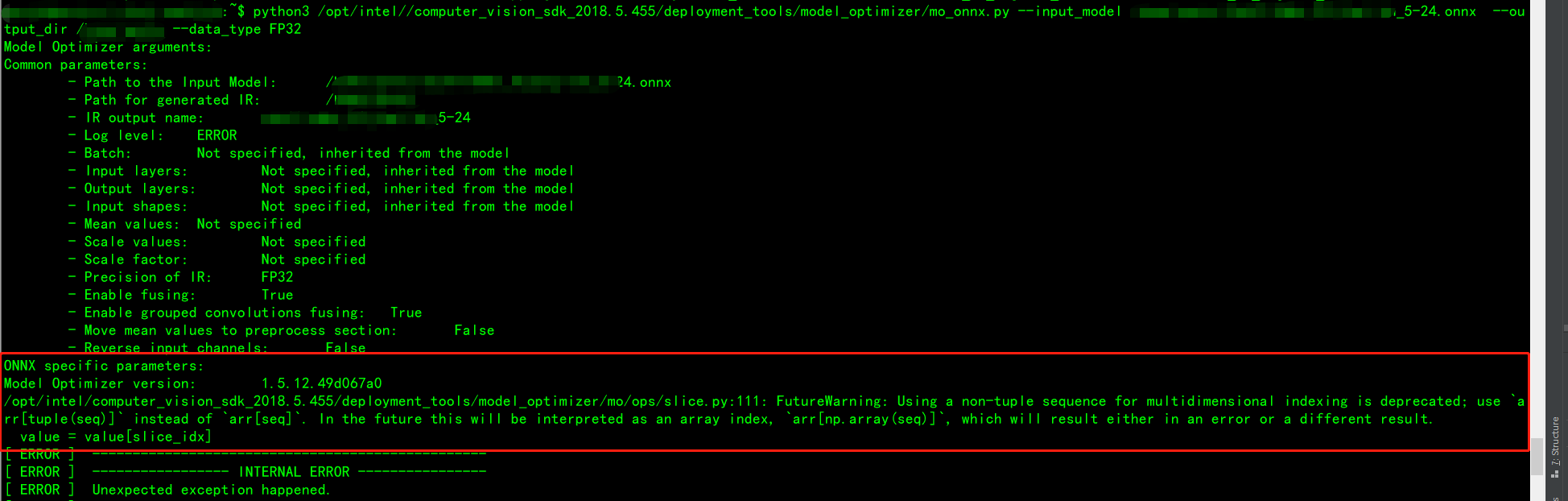
报错1: 在进行多维索引时,使用非元组序列是被弃用。 意思是在多维索引操作时要考虑到数据结构之间的关系。
/opt/intel/computer_vision_sdk_2018.5.455/deployment_tools/model_optimizer/mo/ops/slice.py:111: FutureWarning: Using a non-tuple sequence for multidimensional indexing is deprecated; use arr[tuple(seq)] instead of arr[seq]. In the future this will be interpreted as an array index, arr[np.array(seq)], which will result either in an error or a different result.
value = value[slice_idx]
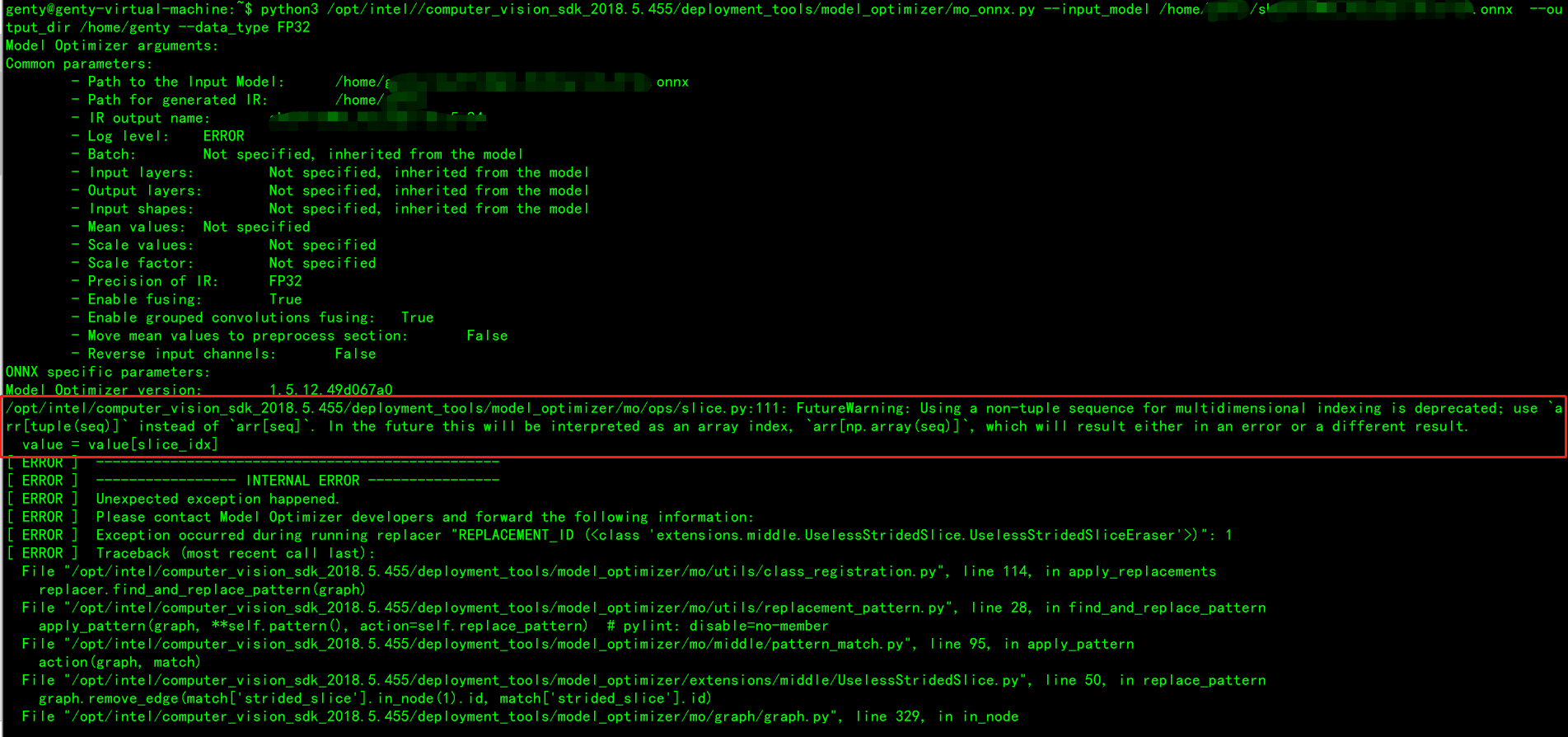
报错2 优化器构建图像时报错,数据流控制出错。其实这跟上面的报错都是说onnx模型数据结构问题。
File “/opt/intel/computer_vision_sdk_2018.5.455/deployment_tools/model_optimizer/mo/graph/graph.py”, line 329, in in_node
return self.in_nodes(control_flow=control_flow)[key]
KeyError: 1
根据上面两个报错,重新查看pt–》onnx这一步。
发现出现如下警告:
TracerWarning: Converting a tensor to a Python index might cause the trace to be incorrect. We can’t record the data flow of Python values, so this value will be treated as a constant in the future. This means that the trace might not generalize to other inputs!
x1 = x[:, :(x.shape[1]//2), :, :]
将张量转换为Python索引可能会导致跟踪不正确。我们不能记录Python值的数据流,所以这个值将来会被当作常量处理。这意味着跟踪可能不适用于其他输入! 意思是索引操作导致张量内部数据流和结构被破坏了,只能作为输入出值,不能再拿来使用了。!!!问题就是这行代码
x1 = x[:, :(x.shape[1]//2), :, :] # 输出x的一半
x是张量,但是对张量的操作是python方法,而不是用torch自带的工具,因此破坏了张量的结构,对于numpy和tensor的处理首先考虑其自带的工具,再考虑其他。
改进:
x1 = torch.chunk(x, 2, 1)[0]
问题解决。
后续还会记录计算棒在Ubuntu16.04和raspberry 3B+ 环境中搭建的文章,以及如何使用计算棒运行模型。
最后
以上就是害怕白云最近收集整理的关于错误记录:FutureWarning: Using a non-tuple sequence for multidimensional indexing is deprecate的全部内容,更多相关错误记录:FutureWarning:内容请搜索靠谱客的其他文章。








发表评论 取消回复