注:本文来源于 Hortonworks 的 Adam Muise 在 July 23 2013 日的 Toronto Hadoop User Group 大会上的一次演讲,
本文只是稍作增删、整理,以备忘。
原文请见:http://www.slideshare.net/adammuise/2013-jul-23thughivetuningdeepdive
1、Hive – SQL 分析任意大小的数据集

2、Hive 关注的焦点
• Scalable SQL processing over data in Hadoop
• Scales to 100PB+
• Structured and Unstructured data
3、hive 与 传统的关系型数据库比较
| Hive | RDBMS |
| SQL Interface. | SQL Interface. |
| Focus on analytics. | May focus on online or analytics. |
| No transactions. | Transactions usually supported. |
| Partition adds, no random INSERTs. In-Place updates not natively supported (but are possible). | Random INSERT and UPDATE supported. |
| Distributed processing via map/reduce. | Distributed processing varies by vendor (if available). |
| Scales to hundreds of nodes. | Seldom scale beyond 20 nodes. |
| Built for commodity hardware. | OQen built on proprietary hardware (especially when scaling out). |
| Low cost per petabyte. | What’s a petabyte? ( ←_← 作者又调皮了 ‾◡◝) |
4、Hive: 一个基于 hadoop 的 SQL 接口
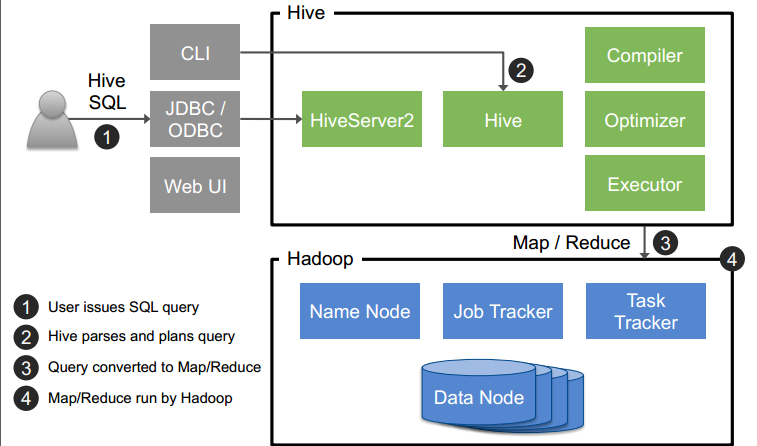
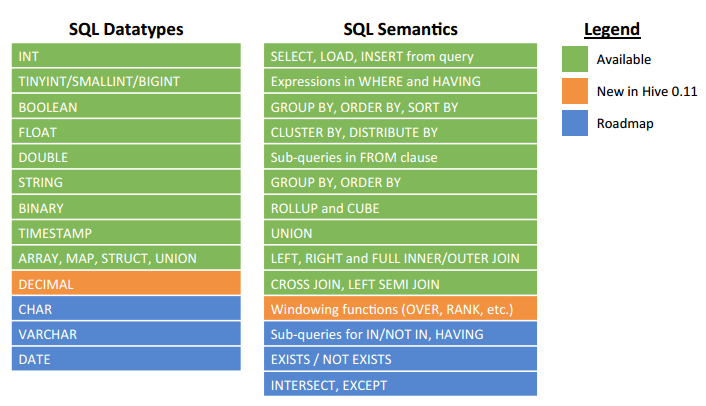
5、SQL 覆盖范围: SQL 92 with Extensions
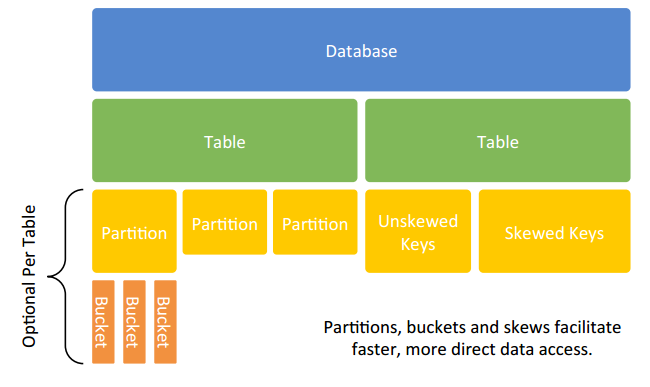
6、Hive 中的数据抽象
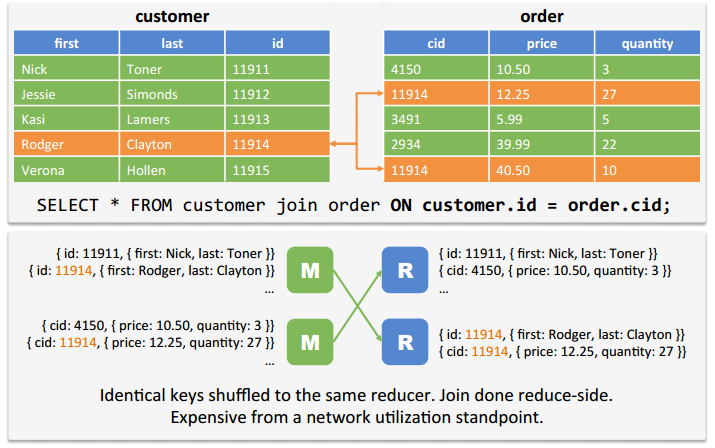
7、Join:“I heard you should avoid joins…”
• “Joins are evil” – Cal Henderson
– Joins should be avoided in online systems.
• Joins are unavoidable in analytics.
– Making joins fast is the key design point.
8、Hive 中的 Join 策略
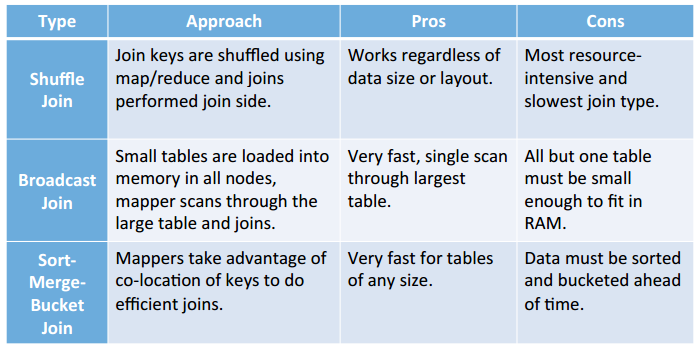
8.1 reduce-side join:Shuffle Joins in Map Reduce
8.2 map-side join:Broadcast Join
• Star schemas use dimension tables small enough to fit in RAM.
• Small tables held in memory by all nodes.
• Single pass through the large table.
• Used for star-schema type joins common in DW.
8.3 SMB join:When both are too large for memory
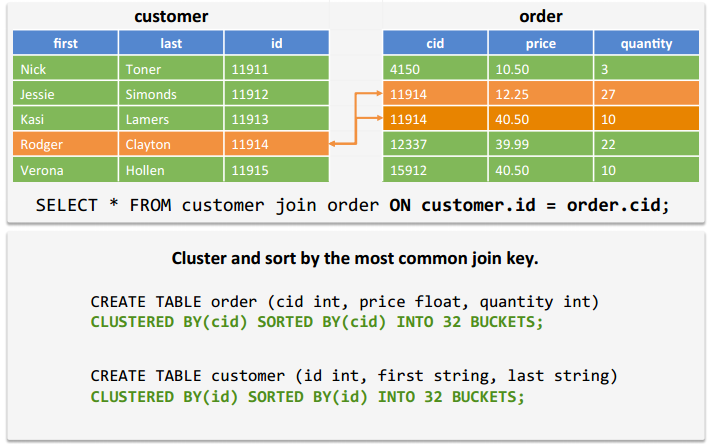
Observa1on 1:
Sor1ng by the join key makes joins easy.
All possible matches reside in the same area on disk.
Observa1on 2:
Hash bucke1ng a join key ensures all matching values reside on the same node.
Equi-joins can then run with no shuffle.
注:在 mapreduce 中,几种常见的 join 方式以及示例代码:
http://my.oschina.net/leejun2005/blog/82523
http://my.oschina.net/leejun2005/blog/111963
http://my.oschina.net/leejun2005/blog/95186
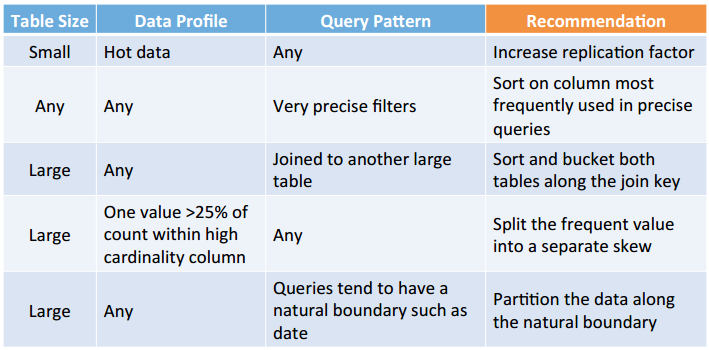
9、控制 hive 中的数据位置
• Bucketing:
– Hash partition values into a configurable number of buckets.
– Usually coupled with sorting.
• Skews:
– Split values out into separate files.
– Used when certain values are frequently seen.
• Replication Factor:
– Increase replication factor to accelerate reads.
– Controlled at the HDFS layer.
• Sorting:
– Sort the values within given columns.
– Greatly accelerates query when used with ORCFilefilter
pushdown.
注:hive 本地化 mr,请参考:
http://superlxw1234.iteye.com/blog/1703546
10、hive 数据架构指南
11、Hive 数据持久化的几种格式
• Built-in Formats:
– ORCFile
– RCFile
– Avro
– Delimited Text
– Regular Expression
– S3 Logfile
– Typed Bytes
• 3rd
-Party Addons:
– JSON
– XML
PS:Hive allows mixed format.
• Use Case:
– Ingest data in a write-optimized format like JSON or delimited.
– Every night, run a batch job to convert to read-optimized ORCFile.
12、ORCFile– Efficient Columnar Layout
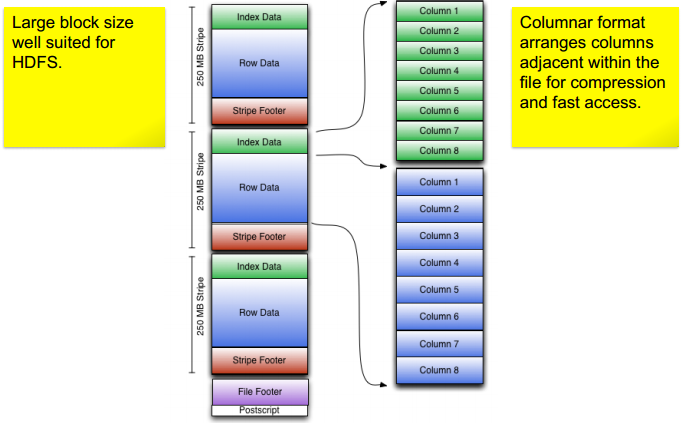
12.1 ORCFile Advantages
• High Compression
– Many tricks used out-of-the-box to ensure high compression rates.
– RLE, dictionary encoding, etc.
• High Performance
– Inline indexes record value ranges within blocks of ORCFiledata.
– Filter pushdown allows efficient scanning during precise queries.
• Flexible Data Model
– All Hive types including maps, structsand unions.
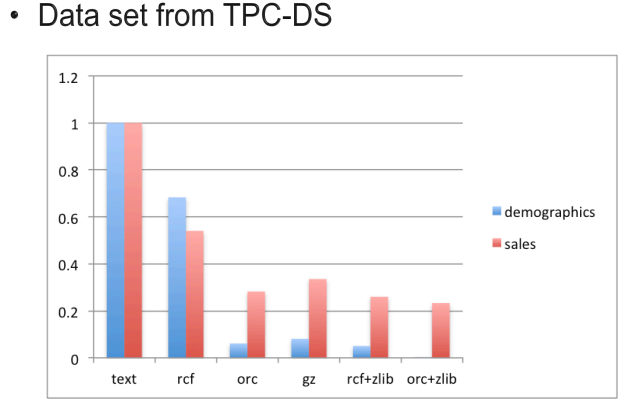
12.2 High Compression with ORCFile
12.3 Some ORCFile Samples
CREATE TABLE sale ( id int, timestamp timestamp, productsk int, storesk int, amount decimal, state string ) STORED AS orc;
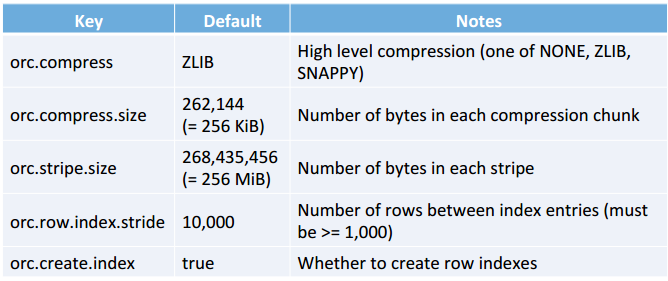
12.4 ORCFile Options and Defaults
12.5 No Compression: Faster but Larger
CREATE TABLE sale (
id int, timestamp timestamp,
productsk int, storesk int,
amount decimal, state string
) STORED AS orc tblproperties ("orc.compress"="NONE");
12.6 Column Sorting to Facilitate Skipping
CREATE TABLE sale (
id int, timestamp timestamp,
productsk int, storesk int,
amount decimal, state string
) STORED AS orc;
INSERT INTO sale AS SELECT * FROM staging SORT BY productsk;
ORCFile skipping speeds queries like
WHERE productsk = X, productsk IN (Y, Z);
12.7 索引:Not Your Traditional Database
• Traditional solution to all RDBMS problems:
– Put an index on it!

• Doing this in Hadoop == #fail
索引可以加快GROUP BY查询语句的执行速度。
Hive从0.80开始,提供了一个Bitmap位图索引,它主要适用于在一个给定的列中只有几个值的场景。详情见:
http://flyingdutchman.iteye.com/blog/1869876
http://www.gemini5201314.net/big-data/hadoop-%E4%B8%AD%E7%9A%84%E6%95%B0%E6%8D%AE%E5%80%BE%E6%96%9C.html
13、Going Fast in Hadoop
• Hadoop:
– Really good at coordinated sequential scans.
– No random I/O. Traditional index pretty much useless.
• Keys to speed in Hadoop:
– Sorting and skipping take the place of indexing.
– Minimizing data shuffle the other key consideration.
• Skipping data:
– Divide data among different files which can be pruned out.
– Partitions, buckets and skews.
– Skip records during scans using small embedded indexes.
– Automatic when you use ORCFileformat.
– Sort data ahead of time.
– Simplifies joins and skipping becomes more effective.
13.1 Data Layout Considerations for Fast Hive

13.2 Partitioning and Virtual Columns
• Partitioning makes queries go fast.
• You will almost always use some sort of partitioning.
• When partitioning you will use 1 or more virtual
columns.
# Notice how xdate and state are not “real” column names.
CREATE TABLE sale ( id int, amount decimal, ... ) partitioned by (xdate string, state string);
• Virtual columns cause directories to be created in
HDFS.
– Files for that partition are stored within that subdirectory.
列裁剪、分区裁剪请参考:
http://my.oschina.net/leejun2005/blog/82529
http://my.oschina.net/leejun2005/blog/82065
13.3 Loading Data with Virtual Columns
• By default at least one virtual column must be hardcoded.
INSERT INTO sale (xdate=‘2013-03-01’, state=‘CA’) SELECT * FROM staging_table WHERE xdate = ‘2013-03-01’ AND state = ‘CA’;
• You can load all partitions in one shot:
– set hive.exec.dynamic.partition.mode=nonstrict;
– Warning: You can easily overwhelm your cluster this way.
set hive.exec.dynamic.partition.mode=nonstrict; INSERT INTO sale (xdate, state) SELECT * FROM staging_table;
13.4 You May Need to Re-Order Columns
• Virtual columns must be last within the inserted data set.
• You can use the SELECT statement to re-order.
INSERT INTO sale (xdate, state=‘CA’) SELECT id, amount, other_stuff, xdate, state FROM staging_table WHERE state = ‘CA’;
13.5 Tune Split Size – Always
• mapred.max.split.size and mapred.min.split.size
• Hive processes data in chunks subject to these bounds.
• min too large -> Too few mappers.
• max too small -> Too many mappers.
• Tune variables un6l mappers occupy:
– All map slots if you own the cluster.
– Reasonable number of map slots if you don’t.
• Example:
– set mapred.max.split.size=100000000;
– set mapred.min.split.size=1000000;
• Manual today, automa6c in future version of Hive.
• You will need to set these for most queries.
注:控制hive任务中的map数和reduce数
http://superlxw1234.iteye.com/blog/1582880
13.6 Tune io.sort.mb – Sometimes
• Hive and Map/Reduce maintain some separate buffers.
• If Hive maps need lots of local memory you may need to
shrink map/reduce buffers.
• If your maps spill, try it out.
• Example:
– set io.sort.mb=100;
13.7 Other Settings You Need
• All the 6me:
– set hive.op1mize.mapjoin.mapreduce=true;
– set hive.op1mize.bucketmapjoin=true;
– set hive.op1mize.bucketmapjoin.sortedmerge=true;
– set hive.auto.convert.join=true;
– set hive.auto.convert.sortmerge.join=true;
– set hive.auto.convert.sortmerge.join.nocondi1onaltask=true;
• When bucke6ng data:
– set hive.enforce.bucke1ng=true;
– set hive.enforce.sor1ng=true;
• These and more are set by default in HDP 1.3.
– Check for them in hive-site.xml
– If not present, set them in your query script
• 防止 group by 数据倾斜
– hive.groupby.skewindata=true
• 增加reduce 的jvm内存,或者进行一些参数调优,如:
mapred.child.java.opts -Xmx 1024m
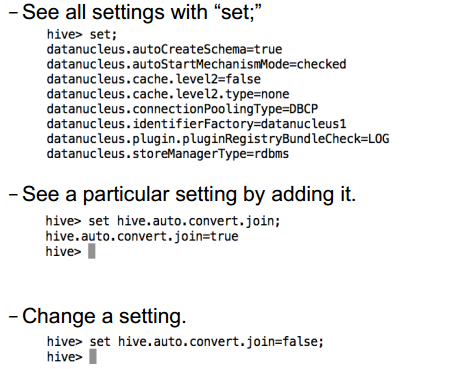
13.8 Check Your Settings
• In Hive shell:
14、流程示例
14.1 Define optimized table
CREATE TABLE fact_pos
(
txnid STRING,
txntime STRING,
givenname STRING,
lastname STRING,
postalcode STRING,
storeid STRING,
ind1 STRING,
productid STRING,
purchaseamount FLOAT,
creditcard STRING
) PARTITIONED BY (part_dt STRING)
CLUSTERED BY (txnid)
SORTED BY (txnid)
INTO 24 BUCKETS
STORED AS ORC tblproperties("orc.compress"="SNAPPY");
The part_dtfield is defined in the partition by clause and cannot be the same name as any other
fields. In this case, we will be performing a modification of txntimeto generate a partition key. The
cluster and sorted clauses contain the only key we intend to join the table on. We have stored as
ORCFilewith Snappy compression.
14.2 Load Data Into Optimized Table
set hive.enforce.sorting=true; set hive.enforce.bucketing=true; set hive.exec.dynamic.partition=true; set hive.exec.dynamic.partition.mode=nonstrict; set mapreduce.reduce.input.limit=-1; FROM pos_staging INSERT OVERWRITE TABLE fact_pos PARTITION (part_dt) SELECT txnid, txntime, givenname, lastname, postalcode, storeid, ind1, productid, purchaseamount, creditcard, concat(year(txntime),month(txntime)) as part_dt SORT BY productid;
We use this commend to load data from our staging table into our
optimized ORCFileformat. Note that we are using dynamic partitioning with
the projection of the txntimefield. This results in a MapReduce job that will
copy the staging data into ORCFileformat Hive managed table.
14.3 Increase replication factor
hadoop fs-setrep-R –w 5 /apps/hive/warehouse/fact_pos
Increase the replication factor for the high performance table.
This increases the chance for data locality. In this case, the
increase in replication factor is not for additional resiliency.
This is a trade-off of storage for performance.
In fact, to conserve space, you may choose to reduce the
replication factor for older data sets or even delete them
altogether. With the raw data in place and untouched, you can
always recreate the ORCFilehigh performance tables. Most
users place the steps in this example workflow into an Oozie
job to automate the work.
14.4 Enabling Short Circuit Read
In hdfs-site.xml(or your custom Ambari settings for HDFS,
restart service after):
dfs.block.local-path-access.user=hdfs dfs.client.read.shortcircuit=true dfs.client.read.shortcircuit.skip.checksum=false
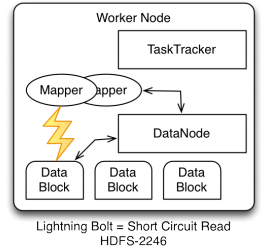
Short Circuit reads allow the mappers to bypass the overhead of opening a
port to the datanodeif the data is local. The permissions for the local
block files need to permit hdfsto read them (should be by default already)
See HDFS-2246 for more details.
14.5 Execute your query
set hive.mapred.reduce.tasks.speculative.execution=false; set io.sort.mb=300; set mapreduce.reduce.input.limit=-1; select productid, ROUND(SUM(purchaseamount),2) as total from fact_pos where part_dtbetween ‘201210’ and ‘201212’ group by productid order by total desc limit 100;
…
OK
205353026.87
390792959.69
289702869.87
455942821.15
…
156492242.05
477042241.22
81402238.61
Time taken: 40.087 seconds, Fetched: 100 row(s)
In the case above, we have a simple query executed to test out our table. We have some
example parameters set before our query. The good news is that most of the parameters
regarding join and engine optimizations are already set for you in Hive 0.11 (HDP). The
io.sort.mbis presented as an example of one of the tunable parameters you may want to
change for this particular SQL (note this value assumes 2-3GB JVMs for mappers). We are
also partition pruning for the holiday shopping season, Oct to Dec.
15、学会查看执行计划
• “explain extended” in front of your query.
• Sections:
– Abstract syntax tree – you can usually ignore this.
– Stage dependencies – dependencies and # of stages.
– Stage plans – important info on how Hive is running the job.
16、Hive Fast Query Checklist
•Par11oned data along natural query boundaries (e.g. date).
•Minimized data shuffle by co-loca1ng the most commonly joined data.
•Took advantage of skews for high-frequency values.
•Enabled short-circuit read.
•Used ORCFile.
•Sorted columns to facilitate row skipping for common targeted queries.
•Verified query plan to ensure single scan through largest table.
•Checked the query plan to ensure par11on pruning is happening.
•Used at least one ON clause in every JOIN.
一些调优方式请参考:深入学习《Programing Hive》:Tuning
http://flyingdutchman.iteye.com/blog/1871983
17、For Even More Hive Performance
•Increased replica1on factor for frequently accessed data and dimensions.
•Tuned io.sort.mb to avoid spilling.
•Tuned mapred.max.split.size, mapred.min.split.size to ensure 1 mapper wave.
•Tuned mapred.reduce.tasks to an appropriate value based on map output.
•Checked jobtracker to ensure “row container” spilling does not occur.
•Gave extra memory for mapjoins like broadcast joins.
•Disabled orc.compress (file size will increase) and tuned •orc.row.index.stride.
•Ensured the job ran in a single wave of mappers.
18、Loading Data in Hive
• Sqoop
– Data transfer from external RDBMS to Hive.
– Sqoop can load data directly to/from HCatalog.
• Hive LOAD
– Load files from HDFS or local filesystem.
– Format must agree with table format.
• Insert from query
– CREATE TABLE AS SELECT or INSERT INTO.
• WebHDFS+ WebHCat
– Load data via REST APIs.
19、Handling Semi-Structured Data
• Hive supports arrays, maps, structsand unions.
• SerDesmap JSON, XML and other formats natively
into Hive.
20、Hive Authorization
• Hive provides Users, Groups, Roles and Privileges
• Granular permissions on tables, DDL and DML
operations.
• Not designed for high security:
– On non-kerberizedcluster, up to the client to supply their user
name.
– Suitable for preventing accidental data loss.
21、HiveServer2
• HiveServer2 is a gateway / JDBC / ODBC endpoint Hive clients can talk to.
• Supports secure and non-secure clusters.
• DoAssupport allows Hive query to run as the requester.
• (Coming Soon) LDAP authentication.
22、Roadmap to 100x Faster
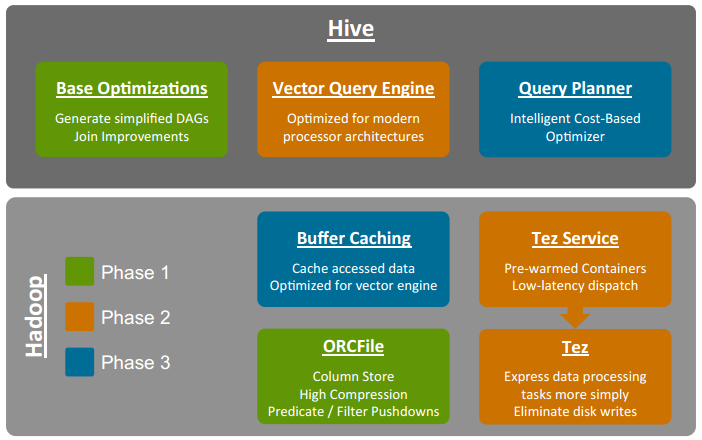
22.1 Phase 1 Improvements
Path to Making Hive 100x Faster
(1)Join Optimizations
• Performance Improvements in Hive 0.11:
• New Join Types added or improved in Hive 0.11:
– In-memory Hash Join: Fast for fact-to-dimension joins.
– Sort-Merge-Bucket Join: Scalable for large-table to large-table
joins.
• More Efficient Query Plan Generation
– Joins done in-memory when possible, saving map-reduce steps.
– Combine map/reduce jobs when GROUP BY and ORDER BY use
the same key.
• More Than 30x Performance Improvement for Star
Schema Join
(2)Star Schema Join Improvements in 0.11

23、更多请参考:
http://my.oschina.net/leejun2005/blog/140462#OSC_h3_2
浅谈SQL on Hadoop系统
http://kan.weibo.com/con/3564924249512540
摘要:
强烈推荐此文,从大数据查询处理的本质分析了当前的SQL on Hadoop系统。
想起了之前关于数据库研究者"MapReduce是历史倒退"的争论!
数据库技术四十多年的发展,其对数据处理和优化的精髓如高级索引,
物化视图,基于代价的优化,各种嵌套查询 已经有很深入的研究和经验了~
Ref: http://www.w3c.com.cn/hive-performance-%E5%AD%A6%E4%B9%A0%E7%AC%94%E8%AE%B0
最后
以上就是活泼火车最近收集整理的关于Hive & Performance 学习笔记的全部内容,更多相关Hive内容请搜索靠谱客的其他文章。








发表评论 取消回复