操作内容简介
- 一、操作前的准备
- 二、Hive表操作详讲
- 1. 创建数据库
- 2. 查看所有数据库/表
- 3. 在Hive上直接操作HDFS
- 4. 在Hive上直接执行终端命令
- 5. 创建数据表/查看表的信息
- 1.托管表
- 2.分区表
- 3.桶表
- 4.外部表
- 6. 导入数据进表
- 1.托管表
- 2.分区表
- 3.桶表
- 4.外部表
- 7.复制表
- 1.仅复制表结构
- 2.复制表结构及数据
- 8. 创建视图
- 三、总结
一、操作前的准备
本演示的所有操作所用的Hive版本是apache-hive-2.1.0,大家先事先安装好Hive,详情请移步:Hive学习之路(一):Hive的基本概念与安装配置,版本因素对于以下的操作来说不大。本次所演示的操作在hive shell环境下完成,在Hive中所使用的SQL语句与MySQL等关系型数据库的基本一致,顾不作演示。
二、Hive表操作详讲
1. 创建数据库
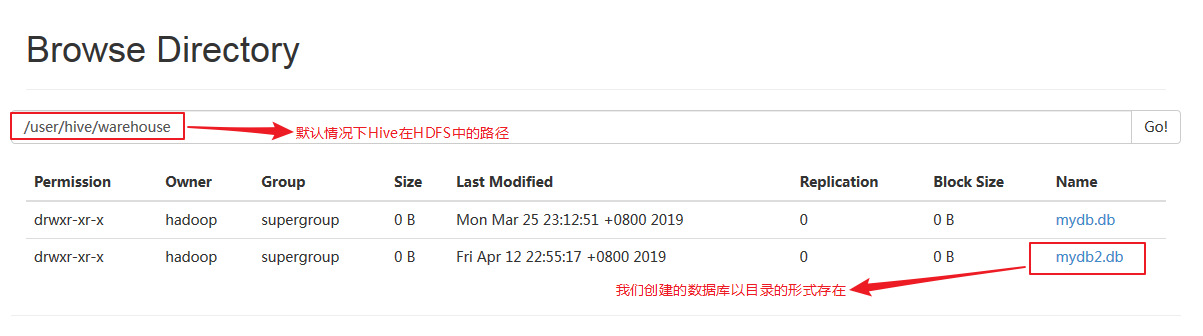
命令格式:create database 数据库名 在Hive中创建一个数据库,本质是在HDFS的Hive目录下创建一个文件夹,名字为数据库名,因而可以得知,在Hive中,一个数据库就是一个目录。使用命令:create database mydb2,创建一个名为mydb2的数据库,我们可以在HDFS的50070Web端口查看:
2. 查看所有数据库/表
命令格式:show databases/tables 查看所有数据库/当前数据库下所有的表:
使用命令:show databases,查看HiVe中所有的数据库:

命令格式:use 数据库名 进入指定数据库名的数据库下,执行命令:use mydb2,进入mydb2数据库,执行命令:show tables列出mydb2下的所有表,因为我们没有创建任何表,所以为空:

3. 在Hive上直接操作HDFS
命令格式:dfs -xx hdfs路径 可以直接操作HDFS,且效率比在终端操作HDFS要高很多,比如我想看Hive在HDFS目录下的数据库目录,执行命令:dfs -ls /user/hive/warehouse:

我们发现了我们建立的数据库mydb2.
4. 在Hive上直接执行终端命令
在hive shell中除了可以直接操作HDFS,还可以执行普通的终端命令。
命令格式:! shell命令 可以直接执行普通的终端命令。比如,我想查看当前路径,执行命令:! pwd:

5. 创建数据表/查看表的信息
在Hive中,表的创建方法有多种,一张表在HDFS中在大多数情况下是一个文件,命令格式:
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name
[(col_name data_type [COMMENT col_comment], …)]
[COMMENT table_comment]
[PARTITIONED BY(col_name data_type [COMMENT col_comment], …)]
[CLUSTERED BY (col_name, col_name, …)
[SORTED BY(col_name [ASC|DESC], …)] INTO num_buckets BUCKETS]
[ROW FORMAT row_format]
[STORED AS file_format]
上面高度概括了Hive创建表的大多数方法,下面分点演示:
1.托管表
命令格式:create table 表名(字段名1 类型,字段名2 类型,…) row format delimited fields terminated by 't’ 创建一张以制表符分隔数据的表:
执行命令:create table student(id int,name string,age int) row format delimited fields terminated by ' ' 创建一个有三个字段且以空格分隔字段的学生表:

再执行命令:show tables 查看mydb2的数据表:

发现学生表已经建立完成。
命令格式:desc [formatted] 表名 查看表的信息,参数formatted代表查看表的详细信息,执行命令:desc student:

可以简单查看到学生表的简单字段信息,执行命令:desc formatted student:
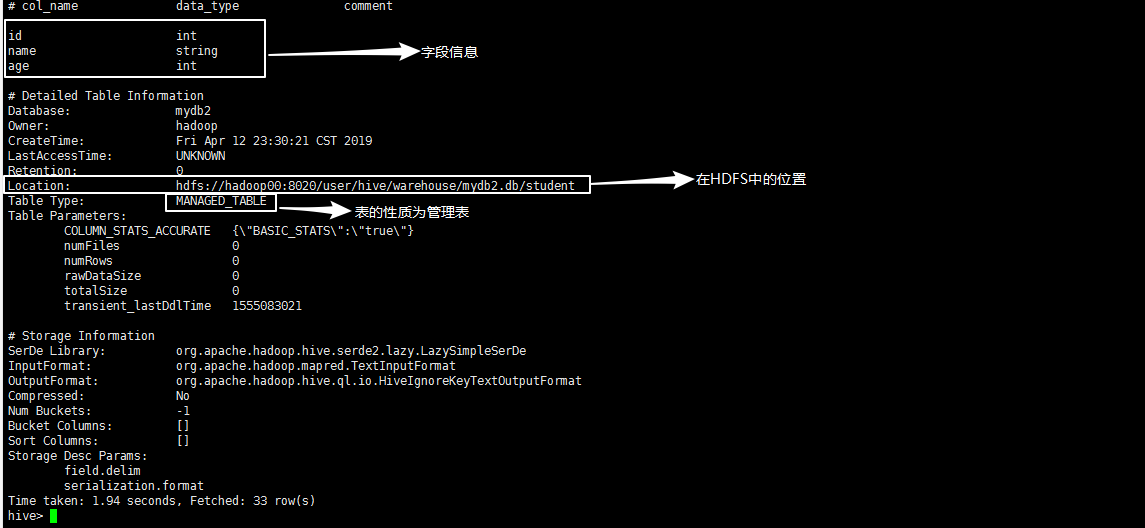
可以查看表的所有信息,包括表的字段信息,在HDFS中的存储位置,表的性质,表的分隔符等信息。
2.分区表
命令格式:create table 表名(字段名1 类型,字段名2 类型,…) partitioned by(字段x 类型,字段y,类型) row format delimited fields terminated by ‘,’ 这里还要注意的是,分区的字会成为表的字段,所以分区字段不能和括号中的字段重复。执行命令:create table users(id int,name string,age int) partitioned by (gender string) row format delimited fields terminated by ',',表示创建一张有四个字段,以性别字段作为分区依据且字段之间以逗号分隔的表:

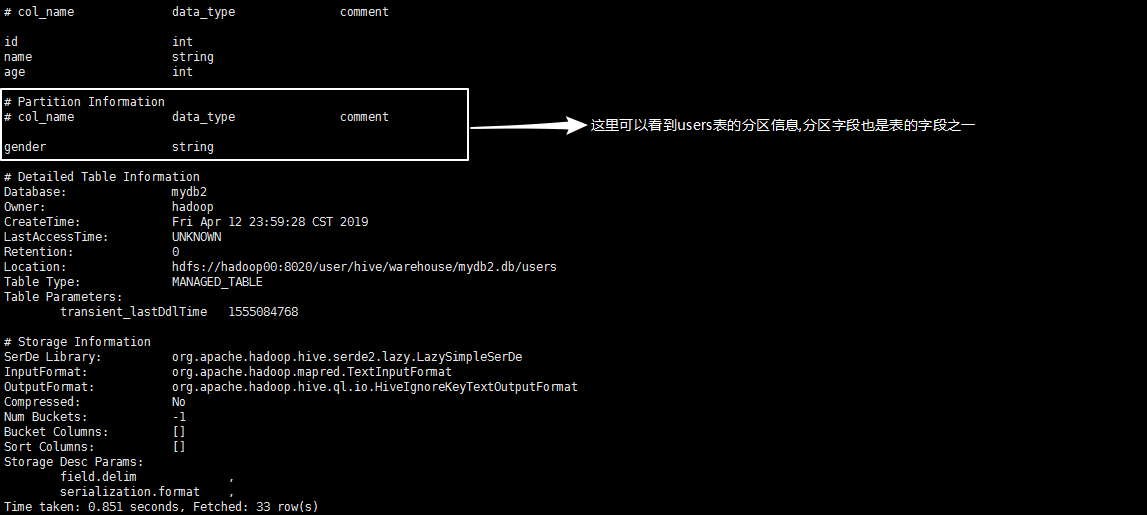
执行命令:desc formatted users查看users表的详细信息,可以看到users表的分区信息:
为users表添加/删除分区:
命令格式:alter table 表名 add/drop partition (字段 = 值),比如为users表添加两个分区,执行命令:alter table users add partition(gender = 'male),执行命令:alter table users add partition(gender = 'female):

命令格式:show partitions 表名 查看表的分区信息,执行命令:show partitions users:

可以查看到users表的分区信息,已经有两个分区。
在HDFS中,查看该表:
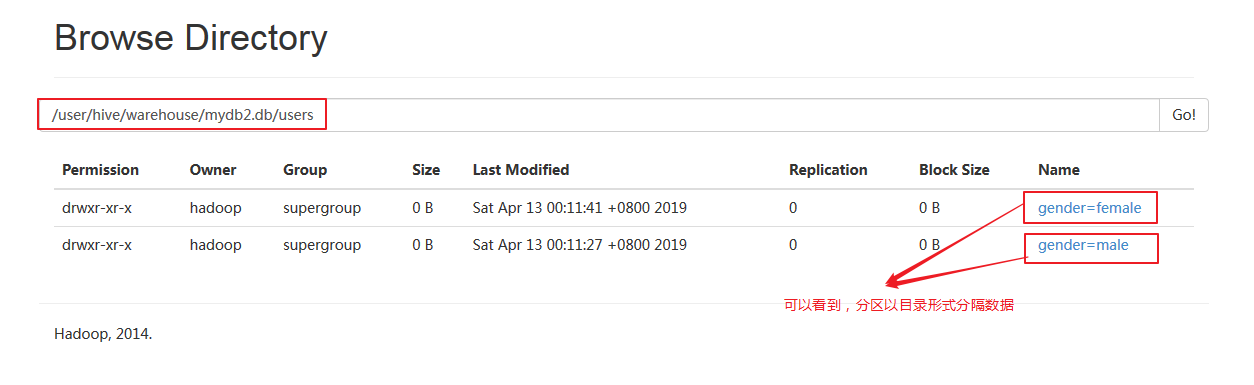
我们可以发现,一张分区表在HDFS中其实是一个目录,而分区是其子目录,分区表的数据是落实在子目录中的。
3.桶表
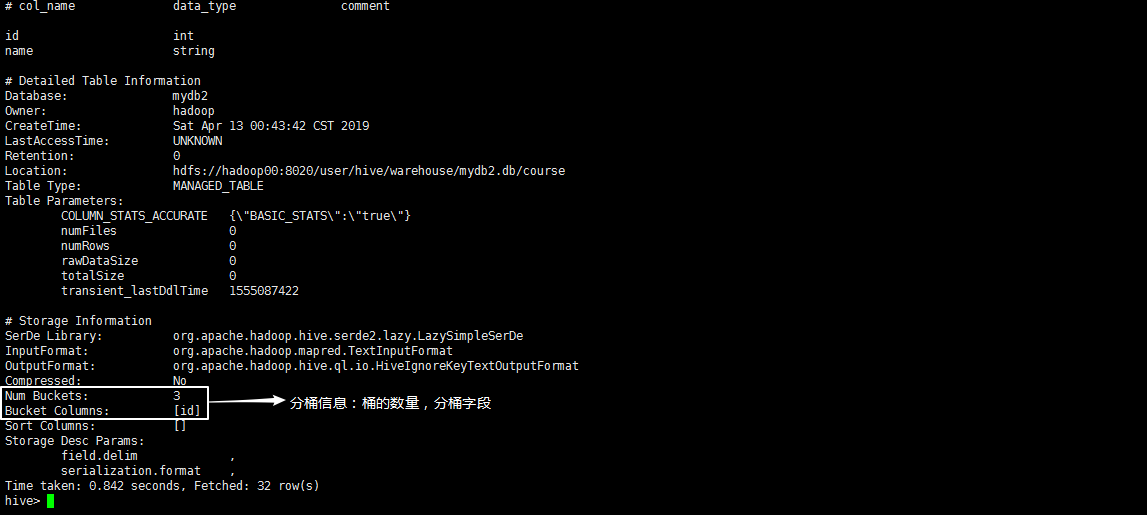
命令格式:create table 表名(字段名1 类型,字段名2 类型,…) clustered by (字段1) into 桶的数量 buckets row format delimited fields terminated by ‘,’ 这里要注意的是分桶的字段取自括号里的字段。执行命令:create table course(id int,name string) clustered by (id) into 3 buckets row format delimited fields terminated by ',' 表示创建一张两个字段的表,以id分桶且以逗号分隔字段:

执行命令:desc formatted course,查看course表的所有信息,可以看到分桶的信息:
4.外部表
以上三种表统称为内部表,其特点是,Hive对其表结构和数据一并管理,删除表时不仅删除表结构,也把表删除;外部表Hive只管理表结构,不管理数据,删除表时只删除表结构不删除数据。建立外部表的方式有多种,现演示基于HDFS建立。
命令格式:create external table 表名(字段名1 类型,字段名2 类型,…) row format delimited fields terminated by ', ’ location ‘/…/…’ location 后跟HDFS的路径,即外部数据的路径。
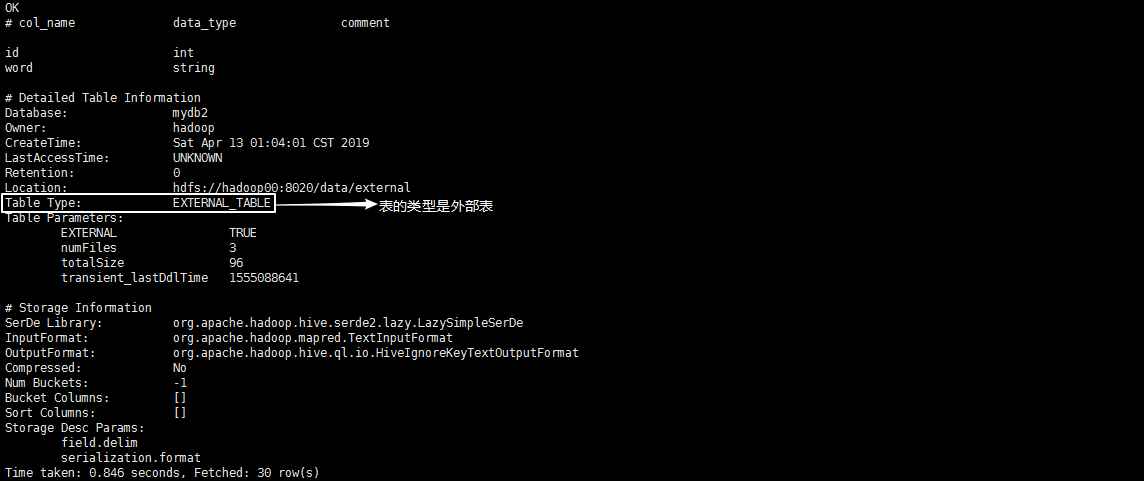
执行命令:create external table exter(id int,word string) row format delimited fields terminated by ' ' location '/data/external' 表示创建一个有两个字段,数据在HDFS的/data/external目录下,且以空格分隔字段的外部表:

执行命令:desc formatted exter 查看exter表的详细信息:
至此,Hive各种表的创建基本已经演示完毕。
6. 导入数据进表
1.托管表
命令格式:load data [local] inpath ‘/…/…/…’ [overwrite] into table 表名 加参数local代表导入本地的数据,如果不加则是导入HDFS的数据;加参数overwrite表示覆盖原来表的数据,不加则不覆盖。以student表为例,我想在本地将下面的数据导入:
1 mike 19
2 alax 23
3 amy 22
4 jon 18
5 linda 20
7 hala 21
执行命令:load data local inpath /home/hadoop/data/student.txt into table student:

执行命令:select * from student 查看结果:

2.分区表
命令格式:load data [local] inpath ‘/…/…/…’ [overwrite] into table 表名partition(字段1=值1,字段2=值2,…) 以users表为例,我想把以下数据导入gender=male分区:
1,mike,22
2,alax,23
3,amy,11
4,jon,34
5,linda,22
7,hala,21
执行命令:load data local inpath '/home/hadoop/data/users1.txt' into table users partition(gender = 'male'):

想把以下数据导入gender=female分区:
12,apple,22
13,amy,23
14,scala,11
15,jerry,34
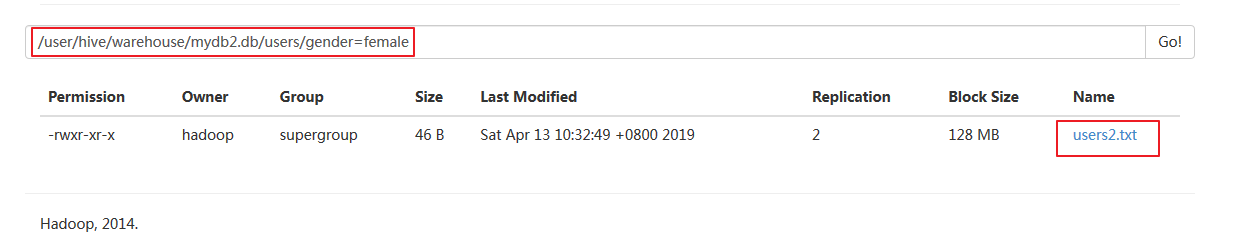
执行命令:load data local inpath '/home/hadoop/data/users2.txt' into table users partition(gender = 'female'):

执行命令:select * from users:

事实它们在不同的子目录下:

3.桶表
桶表不能通过load的方式直接加载数据,只能从另一张表中插入数据
命令格式:insert into 表名1 select 字段1,字段2, … from 表名2 ,以course表为例,现在我要给它插入student表的数据,执行命令:insert into course select id,name from student:
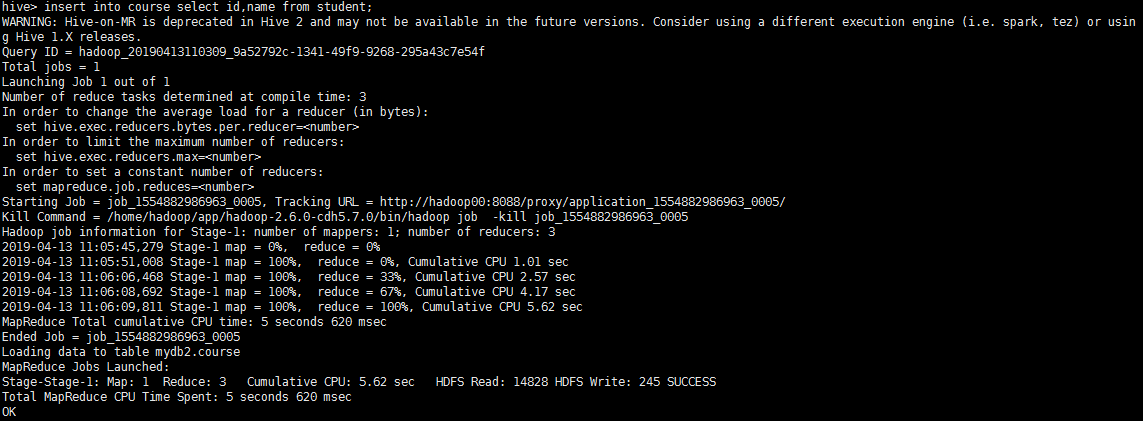
发现数据的插入过程转变成了一个MapReduce作业,执行命令:select * from course:

上HDFS的50070端口观察该表:
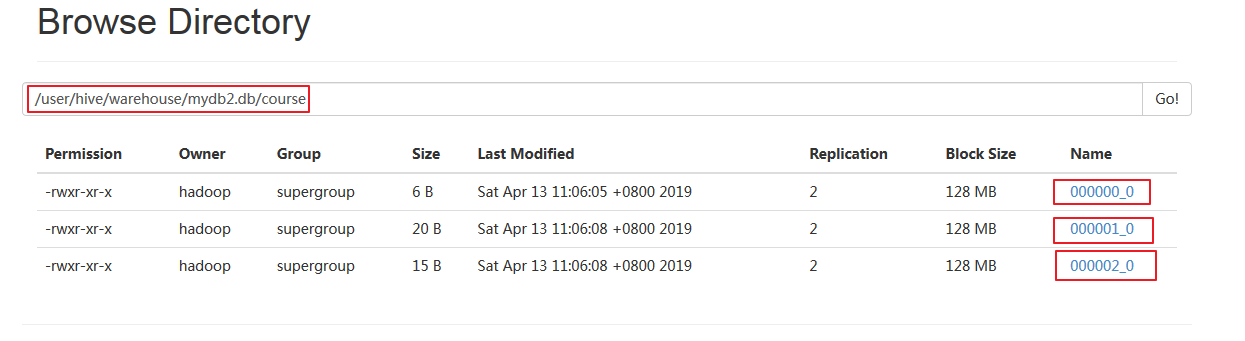
发现实际上,桶表是一个目录,桶表的每一个桶,就是一个文件。
4.外部表
外部表导入数据的方式与其建立方式相关。现演示在HDFS上建立外部表的数据导入方式,其实就在该表的位置下添加文件即可,以exter表为例,将以下三个文件上传至HDFS路径/data/external:
data1:
123 hadoop
234 spark
345 flink
data2:
456 hbase
567 hive
678 sqoop
data3:
789 kafka
890 zookeeper
098 flume
执行命令:select * from exter:

就可以看到我们刚刚上传的文件了,外部表会监控它路径下的文件夹,自动把数据加进表中,现我移除data1文件,再执行命令:select * from exter:

发现data1的数据在表中移除。
7.复制表
1.仅复制表结构
命令格式:create table 表名1 like 表名2 以student表为例,执行命令:create table student1 like student:

该表的结构和student表一样,但是没有数据:

2.复制表结构及数据
命令格式:create table 表名1 as select * from 表名2 以student表为例,执行命令:create table student2 as select * from student,Hive会将其转变为MR作业:
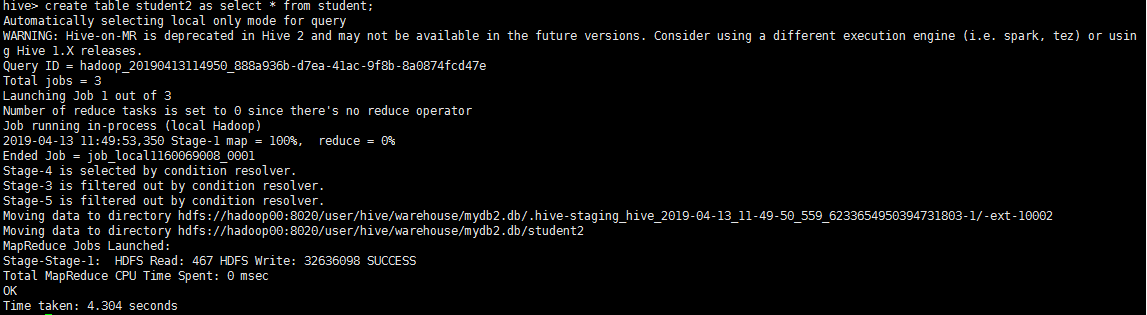
该表的结构和student表一样,且数据也一致:

8. 创建视图
Hive中,视图是一种虚表,本质上只是将复杂的查询SQL语句进行一次封装,视图是不带数据的,数据依然只落地在它本身的表中。
命令格式:create view 视图名 as SQL操作语句 比如将users表中查询所有男性用户的SQL语句封装进视图vuser,执行命令:create view vuser as select * from users where gender = 'male':

执行命令:desc formatted vuser,查看视图的详细信息:
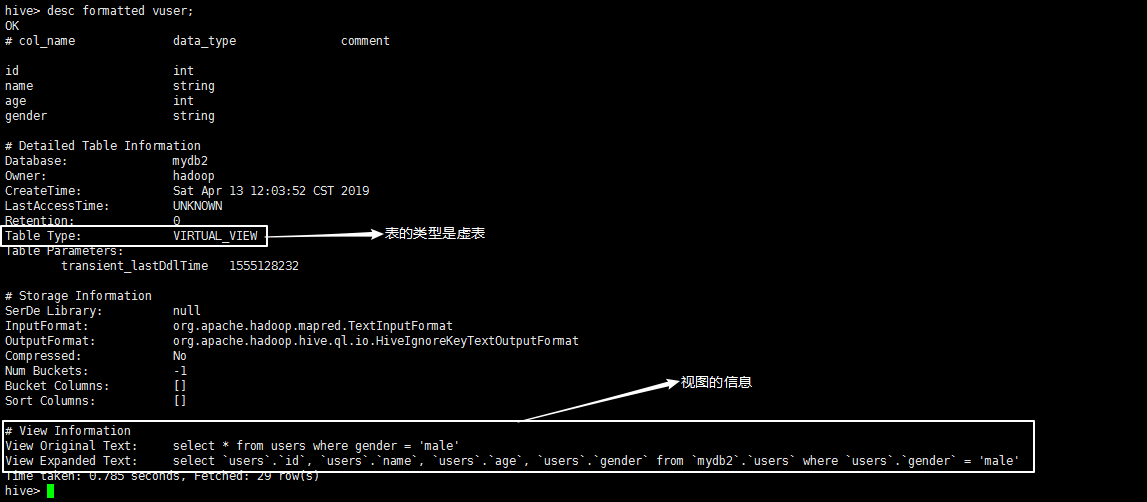
执行命令:select * from vuser,操作视图,本质就是执行视图里的SQL语句:

三、总结
在本章中对于Hive各种表的创建,以及数据的导入作了非常详细的演示,也详细演示了复制表及视图的相关操作。顺带介绍了如何在hive shell中直接操作HDFS和直接执行shell命令,希望对你的学习有所帮助,下一次将演示Hive的hiveser2服务,详情请移步 Hive学习之路(三):hiveserver2的启动与使用。感谢您的阅读,如有错误请不吝赐教!
最后
以上就是魁梧河马最近收集整理的关于Hive学习之路(二):Hive表操作详讲的全部内容,更多相关Hive学习之路(二)内容请搜索靠谱客的其他文章。








发表评论 取消回复