在上一篇文章中,我们已经设置了linux的静态ip,那么下面我们需要做一些linux操作系统上的配置,之后再进行伪分布式安装。
1.首先,在大家上网的过程中,比如当大家想进行搜索时,一般可能会选择百度或者google,此时我们会打开浏览器,输入域名,然后进行搜索,而不是输入ip地址,同理,在linux上,我们可以设置linux的hostname来代替ip地址,使人们更加容易记忆。下面打开终端,看当前hostname是什么,执行命令hostname,如图:
当前主机名为localhost.localdomain。下面进行修改,修改为有意义的主机名,可以使用命令
hostname hadoop
此时输入hostname进行验证是否更改,发现此时主机名已经改为hadoop,但是此次修改仅对此次回话有效,当重启机器后,会恢复之前主机名。下面我们看一下如何永久的修改主机名。在终端中我们输入如下命令:
vi /etc/sysconfig/network
该命令对network文件进行编辑,将其中的HOSTNAME=后的值设置为hadoop,然后保存退出,重启虚拟机。此时主机名就永久设置完成。
2.下面我们把ip地址和主机名绑定,先验证一下,主机名和ip地址是否绑定。下面我们来ping一下主机名:
ping hadoop,结果出现如下图所示: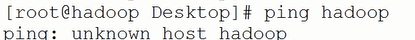
结果显示当前没有进行绑定,我们来绑定一下:
vi /etc/hosts
在最后添加一行,ip+主机名,如图: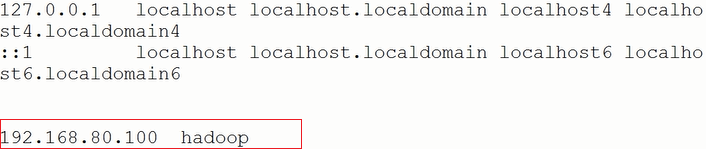
然后保存退出,此时再ping hadoop则可以ping通。
3.下面我们关闭防火墙,避免在我们之后的操作中会出现一些网络不通的问题。
首先查看一下防火墙的状态:
service iptables status
结果如图所示: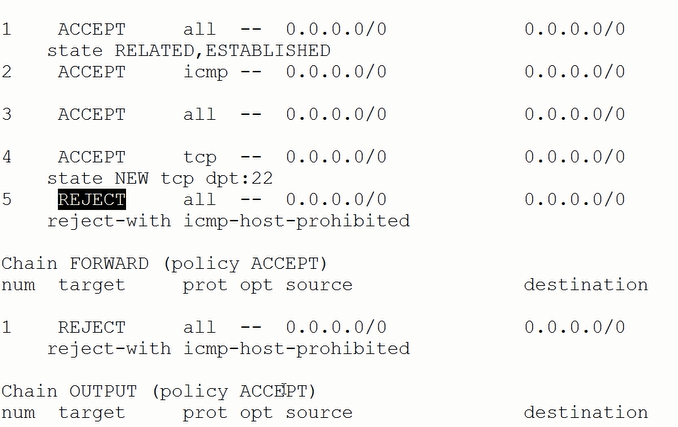
下面我们来关闭防火墙:
service iptables stop
然后我们再次通过service iptabls status来验证是否关闭。在此虽然我们已经关闭了防火墙,但是防火墙有时会在电脑启动时自动启动,下面我们来查看一下防火墙的自动启动设置:
chkconfig --list | grep iptables
我们发现,在防火墙的各种状态中,还有on的状态,这表示在某种级别下防火墙会自动启动,下面我们来彻底关闭防火墙:
chkconfig iptables off
再通过上面命令验证:
chkconfig --list | grep iptables
发现所有状态都为off,则防火墙已经彻底关闭。
4.配置SSH免密码登陆
在后续我们使用hadoop过程中,如果不配置ssh免密码登陆的话,会经常提示输入密码,给我们造成不必要的麻烦,因此我们在这里配置ssh免密码登陆。
首先,我们查看~/目录下有什么文件夹,配置SSH需要先产生密钥,密钥会存储在~/.ssh文件夹中,执行如下命令:
ls -a
有如下文件夹及文件: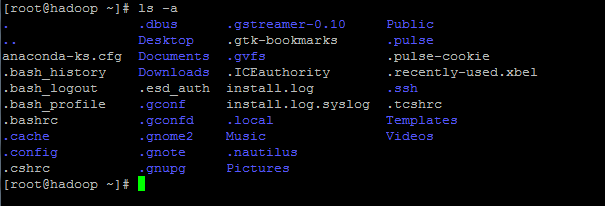
下面生成密钥,执行如下命令:
ssh-keygen -t rsa产生密钥,密钥位置~/.ssh文件夹中。在执行命令过程中,会提示输入东西,直接按下回车键三次即成功,出现如下画面: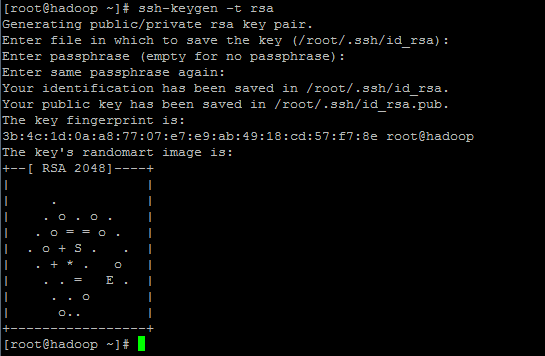
下面把密钥复制一份,名字叫做authorized_keys。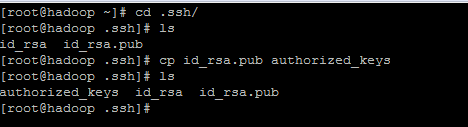
此时,ssh免密码登陆配置完成,试验一下,执行ssh localhost,提示是否连接,输入yes,之后连接成功,再次执行ssh localhost则不需要密码登陆,验证结果如下图: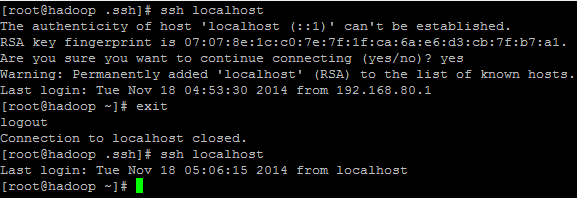
5.安装jdk
hadoop是由java开发的,凡是可以运行java的机器上都可以运行hadoop,所以我们先来安装jdk。
首先拷贝jdk安装文件到linux系统,我使用jdk-6u33-linux-i586.bin。
下面安装jdk:
jdk随便安装到什么位置,我把jdk安装到/usr/java下,创建文件夹/usr/java:
将jdk安装文件复制到该文件夹下,然后执行./jdk-6u33-linux-i586.bin会报如下错误:
-bash: ./jdk-6u33-linux-i586.bin: Permission denied
此错误是因为权限不够,执行如下命令为jdk安装文件修改权限:
chmod u+x jdk-6u33-linux-i586.bin此命令为jdk-6u33-linux-i586.bin赋予执行权限,然后再执行./jdk-6u33-linux-i586.bin进行解压。
知道出现如下图情况,解压结束:
此时jdk安装完成,为了之后配置环境变量不使用jdk1.6.0_33这样的长字符,为jdk重命名: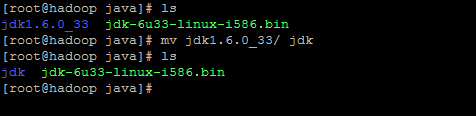
下面配置环境变量。修改/etc/profile文件,添加如下内容:
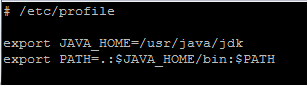
然后保存退出,执行命令:source /etc/profile使设置立即生效,然后使用java -version验证jdk安装是否成功。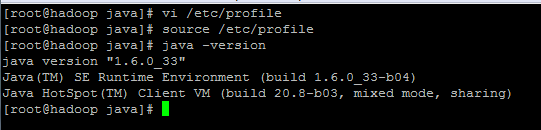
至此jdk安装完成。
6.安装hadoop。
将hadoop-1.1.2.tar.gz复制到liux系统上,我们将hadoop安装在/usr/hadoop下,将hadoop-1.1.2.tar.gz复制到/usr/hadoop下。
下面来进行解压hadoop-1.1.2.tar.gz。
执行命令:tar -zxvf hadoop-1.1.2.tar.gz
解压完成之后,hadoop下会出现一个hadoop-1.1.2的文件夹。将文件夹改名为hadoop以便于后面使用。
mv hadoop-1.1.2 hadoop
设置环境变量,vi /etc/profile,修改上面jdk环境变量处如下: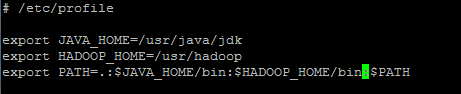
然后source /etc/profile使设置立即生效。此时单机版的hadoop安装配置完成,但是我们在配置伪分布式,需要修改几个配置文件,配置文件位置在hadoop安装文件下的conf文件夹下,分别为:hadoop-env.sh,core-site.xml,hdfs-site.xml,mapred-site.xml。
(1)hadoop-env.sh
export JAVA_HOME=/usr/java/jdk/
(2)core-site.xml
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://hadoop:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/hadoop/tmp</value>
</property>
</configuration>
(3)hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
(4)mapred-site.xml
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>hadoop:9001</value>
</property>
</configuration>
其中hadoop的位置是linux的主机名,相应的位置要做相应替换。
此时hadoop伪分布式安装完成。
下面进行hadoop启动。启动之前要先格式化hadoop。执行如下命令:
hadoop namenode -format
格式化之后,执行start-all.sh启动,出现如下画面证明启动成功,hadoop伪分布式至此彻底完成。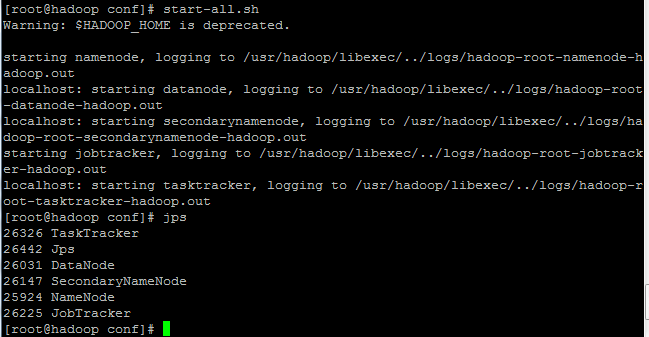
我们还可以通过浏览器,使用hadoop:50070和hadoop:50030分别查看hdfs和mapreduce的情况。
















- 查看图片附件
最后
以上就是清秀星月最近收集整理的关于Hadoop学习笔记_伪分布式安装的全部内容,更多相关Hadoop学习笔记_伪分布式安装内容请搜索靠谱客的其他文章。








发表评论 取消回复