前提
- 先将自己的IP地址设置为静态地址
- 用root用户进行
步骤一:修改主机名
注意下面这个文件是不存在的,这样会自己建立
vi /etc/sysconfig/network
在文件中添加以下内容
NETWORKING=yes
HOSTNAME=你自己想中设置的主机名
保存退出,在命令行输入以下内容
source /etc/sysconfig/network //使文件生效
测试:输入以下命令,观察是否出现自己设置的主机名。若出现,则说明已经成功了。
hostname
步骤二:将主机名与IP地址进行映射
在/etc目录下:修改其中hosts文件,也有可能是hostname文件。即/etc/hosts或/etc/hostname。
这两个文件有一个存在,看自己的系统存在哪一个文件。文件内的内容如下:(注意第三行是自己加的)
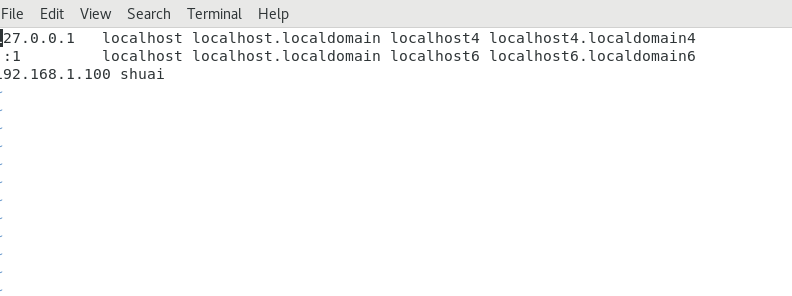
在这个文件中将自己的ip地址与主机名映射写入其中。格式:
IP地址 主机名 //注意:IP地址与主机名之间有一个空格
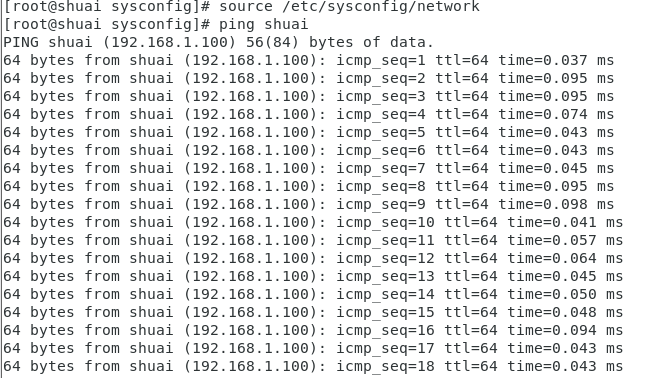
测试:输入以下命令观察是否可以ping通:
ping 用户名
ping通的标志是出现如下图的情况:
步骤三:关闭防火墙
注意:各个版本关闭防火墙的方式不一定相同,本人这里使用的是Centos7。根据自己系统的情况关闭防火墙
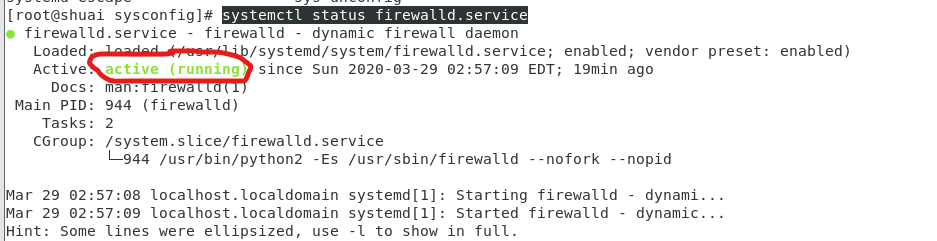
查看防火墙状态:
systemctl status firewalld.service
出现以下图:说明防火墙是开启的(红圈圈圈出来的地方)
 关闭防火墙:
关闭防火墙:
systemctl stop firewalld.service
将防火墙永久关闭
systemctl disable firewalld.service
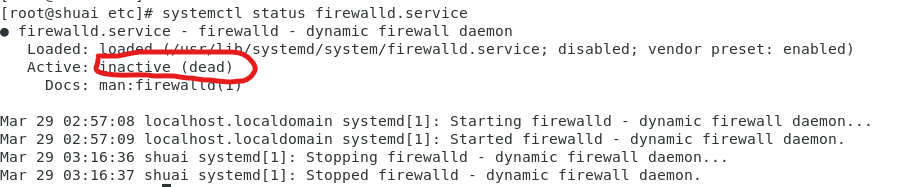
测试:输入查看防火墙状态的命令(systemctl status firewalld.service),出现下图。说明防火墙已关闭:
步骤四:配置免密登录
注意:有些系统中是没有ssh这个命令的,需要自己安装
以下步骤可以不执行:
~~ssh 用户名~~ //观察自己是否可以免密登录
以下步骤才是真正的配置免密登录
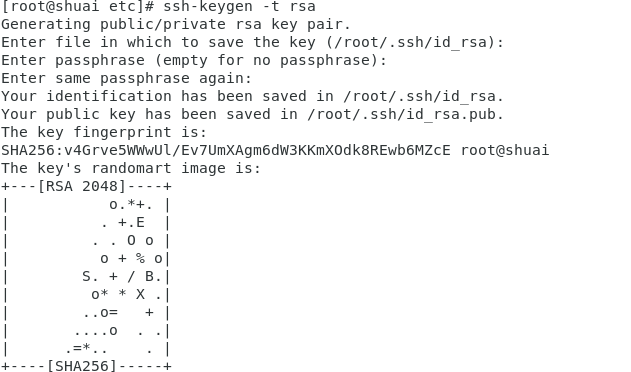
生成公钥和私钥:
ssh-keygen -t rsa
输入之后一直按回车,直到再次出现命令行
结果图:
将公钥进行重定义以实现免密登录:
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
测试:输入以下命令:
ssh 主机名
出现下图说明成功:

步骤五:安装jdk
直接去官网下载即可:此处本人下载的是jdk1.8。将下载的文件传到虚拟机当中(这一步可以利用的途径有共享文件夹和ssh)。还要注意共享文件夹是将文件放在/mnt/hgfs的目录下面(默认),你需要自己去移动文件到你需要的目录下。本文以下安装在/data/soft这个自己新建的目录下。
前提:本人在root用户的目录下新建了一个data/soft目录:使用命令如下:
mkdir -r /data/soft
将文件传到soft目录下之后,使用tar命令对压缩包进行解压
tar -zxvf jdk的压缩包名
解压之后修改环境变量
vi /etc/profile
在profile文件的最后面添加以下内容:
export JAVA_HOME=解压之后的包路径
export PATH=.:$JAVA_HOME/bin:$PATH
保存退出。
使用命令,使环境变量生效:
source /etc/profile
测试:使用以下命令。若出现java的版本信息则说明成功了
java -version
步骤六:安装hadoop
注意:同样的需要将hadoop文件上传到linux虚拟机中,本文使用的使hadoop3.2.1版本。文件自己去官网进行下载即可。也在/data/soft这个目录下执行
首先,解压hadoop:
tar -zxvf hadoop压缩包名称
解压之后对Hadoop进行配置。所有的配置都在你们刚刚解压之后的hadoop-3.2.1/etc/hadoop中(hadoop-3.2.1可能每个人不一样,因为版本可能不同)。
配置hadoop-env.sh(hadoop环境变量配置文件)
注意:这里的路径根据自己的路径进行配置
export JAVA_HOME=/data/soft/jdk1.8
export HADOOP_LOG_DIR=/data/hadoop_tmp/logs/hadoop
修改core-cite.xml(hadoop的核心配置文件)
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/data/hadoop_tmp</value>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://shuai:9000</value>
</property>
</configuration>
解读:
hadoop.tmp.dir:hadoop的临时工作路径
fs.defaultFS:访问hadoop的路径。value是你自己的主机名。
配置hdfs-site.xml(hdfs的相关配置文件)
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
解读:
dfs.replication:副本数
配置mapred-site.xml(mapreduce的相关配置文件)
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
解读:指定mapreduce的执行引擎
配置yarn-cite.xml(yarn的相关配置文件)
<configuration>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
解读:
yarn.nodemanager.aux-services:yarn中运行的计算引擎
yarn.nodemanager.env-whitelist:执行环境的白名单
以上配置文件都配置好之后会到hadoop-3.2.1目录下
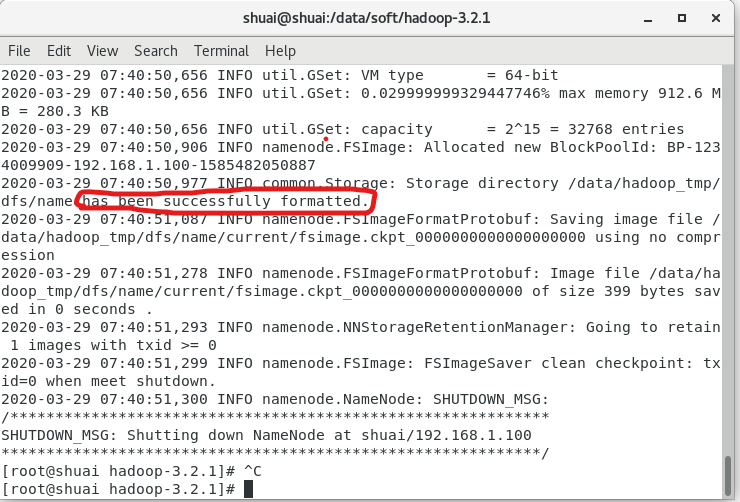
为了使我们的hdfs文件可以使用,需要进行格式化。注意:此操作只能执行一次,格式化命令如下:
bin/hdfs namenode -format
如果格式化失败了,需要将错误的问题解决(一般问题是自己的内容写错了),然后将core-cite.xml中的那个文件夹删除掉,再重新进行格式化。成功之后你会看到下图:
最后配置/sbin目录下的一些文件
start-hdfs.sh脚本文件
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
stop-hdfs.sh脚本文件
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
start-yarn.sh脚本文件
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
stop-yarn.sh脚本文件
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
配置完成之后就可以会到hadoop-3.2.1,执行以下命令启动hadoop即可
sbin/start-all.sh
测试:输入以下命令
jps
出现下图说明你hadoop搭建成功了。注意一个进程都不能缺少

到此:伪分布式安装结束
补充:关闭集群
sbin/stop-all.sh
当然以上的启动和关闭可以更加容易。留给读者自己去探索。QAQ!
最后
以上就是霸气毛巾最近收集整理的关于Hadoop的伪分布式安装前提步骤一:修改主机名步骤二:将主机名与IP地址进行映射步骤三:关闭防火墙步骤四:配置免密登录步骤五:安装jdk步骤六:安装hadoop的全部内容,更多相关Hadoop内容请搜索靠谱客的其他文章。








发表评论 取消回复