Purpose
本篇介绍了如何设置和配置单节点Hadoop安装,一个简单的伪分布式环境,可以使用HadoopMapReduce和Hadoop分布式文件系统(HDFS)快速执行简单的操作。操作详细,和一些异常的解决方法。
Prerequisites
1.支持的平台
- 支持GNU/Linux作为一个开发和生产平台。Hadoop已经在具有2000个节点的GNU/Linux集群上进行了演示。
- Windows也是一个受支持的平台,但以下步骤仅适用于Linux。要在窗口上设置Hadoop,请参阅wiki页面
2.所需软件
linux所需的软件包括:
- 安装Java,jdk1.8版本 下载linux下载安装jdk对应liunx的tar包
jdk-8u281-linux-x64.tar.gz - hadoop-3.2.2 下载对应的tar包 hadoop-3.2.2.tar.gz
- VMware 和 Xshell(远程连接,方便操作)
- 如果要使用可选的启动和停止脚本,则必须安装ssh并运行sshd才能使用管理远程Hadoop守护进程的Hadoop脚本。此外,建议还应安装pdsh,以更好地进行ssh资源管理。(本文没有用脚本安装jdk)
3.安装软件
-
如果您的集群没有必要的软件,那么您就需要安装它。把 jdk-8u281-linux-x64.tar.gz hadoop-3.2.2.tar.gz 的tar包上传到搭建的集群中
(可以通过xshell或者linux命令rz)。 -
先关闭集群节点的防火墙
#查看防火状态
systemctl status firewalld
#暂时关闭防火墙
systemctl stop firewalld
#永久性关闭防火墙(用这个)
systemctl disable firewalld
- 修改yum源
#安装wget
yum install wget -y
#修改yum源
mv /etc/yum.repos.d/CentOS-Base.repo /etc/yum.repos.d/CentOS-Base-repo.backup
wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo
yum clean all
yum makecache
#安装常用软件
yum install man man-pages ntp vim lrzsz zip unzip -y
- 修改hosts的主机名和IP配置文件(根据自己的虚拟机子网地址如192.168.100. xxx,每台都不一样,也可以自己设置)
vim /etc/hosts
#在最后添加自己主机名和IP配置文件

- 设置无密码ssh
#生成密钥
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
#把密钥发放到自己本节点的ip地址(发给自己)“root@192.168.100.200”
ssh-copy-id root@192.168.100.200 ~/.ssh/id_rsa.pub
#测试
ssh root@localhost
ssh root@127.0.0.1
- 把文件上传集群,解压
ll
#解压缩到当前节点
tar -zxvf hadoop-3.2.2.tar.gz
tar -zxvf jdk-8u281-linux-x64.tar.gz

ll
#删除压缩包文件
rm -rf hadoop-3.2.2.tar.gz
rm -rf jdk-8u281-linux-x64.tar.gz

- 解压缩的文件到/opt/apps 并且修改jdk1.8.0_281的文件名为jdk , 也可以修改hadoop方便下面配置。
mv hadoop-3.2.2 /opt/apps/
mv jdk1.8.0_281 /opt/apps/ jdk
cd /opt/apps/
ll

- 修改配置文件
输入i插入,把配置信息复制,按esc 并且输入冒号:wq(保存退出)
cd hadoop-3.2.2/etc/hadoop/
vim care-site.xml
#输入i插入,把配置信息复制,按esc 并且输入冒号:wq(保存退出)
<configuration>
<!-- 指定HDFS中NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://cwnode00:9000</value>
</property>
<!-- 指定Hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/apps/hadoop-3.2.2/data/tmp</value>
</property>
</configuration>
#配置 hdfs-site.xml
vim hdfs-site.xml
输入i插入,把配置信息复制,按esc 并且输入冒号:wq(保存退出)
<configuration>
<!-- 指定HDFS副本的数量 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.http.address</name>
<value>0.0.0.0:50070</value>
</property>
</configuration>
- 修改JAVA_HOME的配置信息
cd /opt/apps/hadoop-3.2.2/etc/hadoop/
vim hadoop-env.sh
vim mapred-env.sh
vim yarn-env.sh
#分别插入配置信息
export JAVA_HOME=/opt/apps/jdk #jdk对应的文件目录
- 配置环境变量
vim /etc/profile
#在文件的最下面添加
export JAVA_HOME=/opt/apps/jdk
export PATH=$JAVA_HOME/bin:$PATH
export HADOOP_HOME=/opt/apps/hadoop-3.2.2/
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
#重新读取环境变量
source /etc/profile
- 最后就是启动了,启动之前先进行格式化
hdfs namenode -format
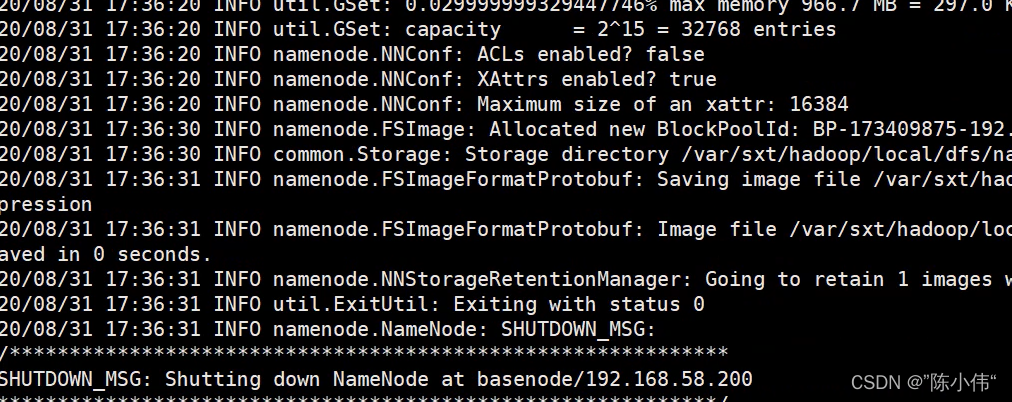
表示格式化成功
接下来就可以用命令启动集群了
start-dfs.sh
4.异常的解决办法
- 问题1
hadoop环境搭建完成后,访问hdfs网址:xx.xxx.xxx.xx:50070不能访问,试试:9870
如果不可以的话要在次查看hosts配置文件,
还有查看虚拟网络配置器中的 NAT模式下的子网。
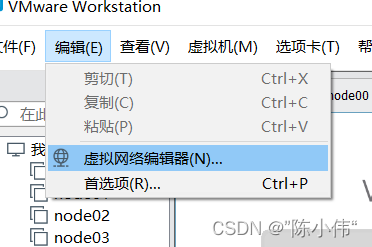
- 问题2
格式化失败
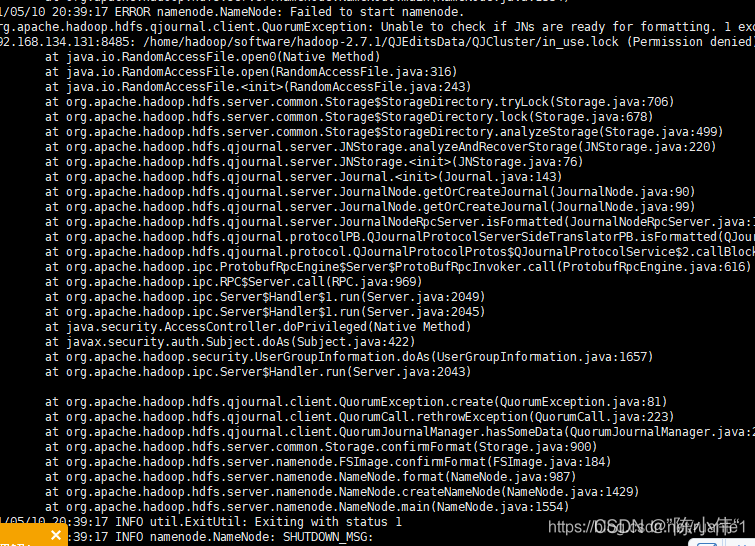
1.格式化失败解决方法
2.重新格式化需要注意的问题
最后
以上就是动听小丸子最近收集整理的关于单节点Hadoop安装(详细操作和问题处理)的全部内容,更多相关单节点Hadoop安装(详细操作和问题处理)内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复