Linux(ubuntu-16.04.2)上hadoop(hadoop-2.7.1)的安装与配置
关于hadoop的安装,网上有七七八八的教程,十个教程九个坑,还有一个特别坑。这使得很多新手在安装hadoop时,按照网上所谓的教程,一步一步,走到了某一步出错了,又搜不到解救之法,不得不放弃。安装过程蹦出的各种问题,让小白们吃吃了不少苦头。下面给出一个Hadoop安装教程(单机/伪分布式配置、hadoop-2.7.1/ubuntu-16.04.2)。
傻瓜式安装虚拟机和ubuntu系统
安装虚拟机VMware,在虚拟机上安装Ubuntu系统。这一步不容易出问题,就略过了。
下载hadoop2.x版本的安装包
我选择的是hadoop-2.7.1,为了减少问题的发生,建议各个工具的版本都同我选成一样,然后一步一步跟着走。下载地址,网上随便一搜就有。可以先下载到windows上,再拷贝到Ubuntu上。下载地址,最好下载编译过的压缩包(tar.gz结尾)。
给Linux创建hadoop新账户,并设置密码
终端输入 sudo useradd -m hadoop -s /bin/bash创建一个名为hadoop的用户,使用 /bin/bash 作为shell。
终端输入sudo passwd hadoop设置密码为hadoop。
友情提示:可以直接上述代码拷贝过去运行,Ubuntu复制粘贴命名同window多加一个shift,如黏贴为
Ctrl+Shift+V。
登录hadoop账户,更新apt
- 点击Ubuntu右上角的齿轮一样的东西,可以选择切换登录用户,这和Window差不多。
- 打开终端输入
sudo apt-get update进行更新。
安装SSH、并授权其无密码登录
- 首先安装SSH server
sudo apt-get install openssh-server- SSH登录本机
ssh localhost- 配置无密码登录,即利用 ssh-keygen 生成密钥,并将密钥加入到授权中
exit # 退出刚才的 ssh localhost
cd ~/.ssh/ # 若没有该目录,请先执行一次ssh localhost
ssh-keygen -t rsa # 会有提示,都按回车就可以
cat ./id_rsa.pub >> ./authorized_keys此时,可用ssh localhost直接登录了。

安装Java环境
- 安装default-jre default-jdk
sudo apt-get install default-jre default-jdk- 打开账户主目录下的bash.bashrc文件,配置环境变量
vim ~/.bashrc文本前添加export JAVA_HOME=/usr/lib/jvm/default-java。
- 让bash文件生效
source ~/.bashrc- 查看版本,测试安装是否成功
java -version安装hadoop2并单机测试
安装hadoop2
- 解压压缩包
我选择解压到/usr/local/路径下
sudo tar -zxf 你的hadoop压缩包所在路径 -C /usr/local # 解压到/usr/local中- 重命名
cd /usr/local/
sudo mv ./hadoop-2.x/ ./hadoop # 将文件夹名改为hadoop- 修改文件权限
sudo chown -R hadoop ./hadoop # 修改文件权限- 查看是否安装成功
切换到安装目录的bin(通过cd命令),执行
./hadoop version
显示hadoop版本信息即为成功。
Hadoop的单机测试
1、安装路径/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.1.jar含有大量的示例,我们可以切换目录到/usr/local/hadoop,然后执行:
./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.1.jar 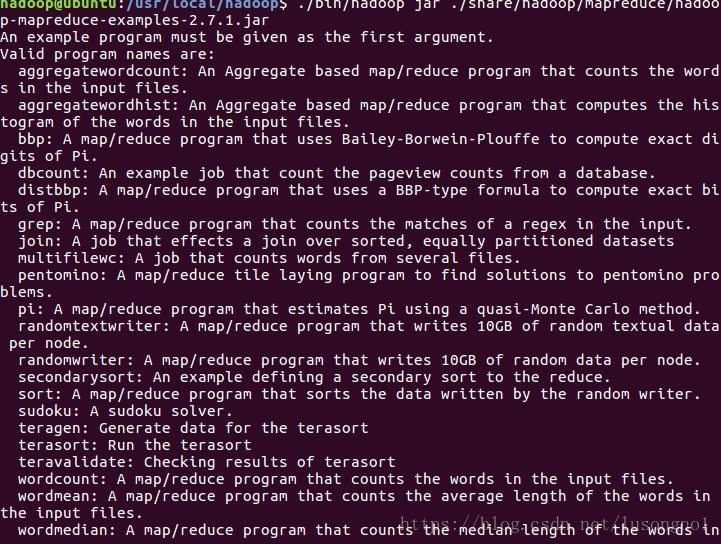
目录树的不同层次、相同层次都有很多同名的文件夹,记得别搞混了,导致进错文件夹,导致找不到文件。
2、hadoop一个使用例子:grep
cd /usr/local/hadoop
mkdir ./input
cp ./etc/hadoop/*.xml ./input # 将配置文件作为输入文件
./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar grep ./input ./output 'dfs[a-z.]+'
cat ./output/* 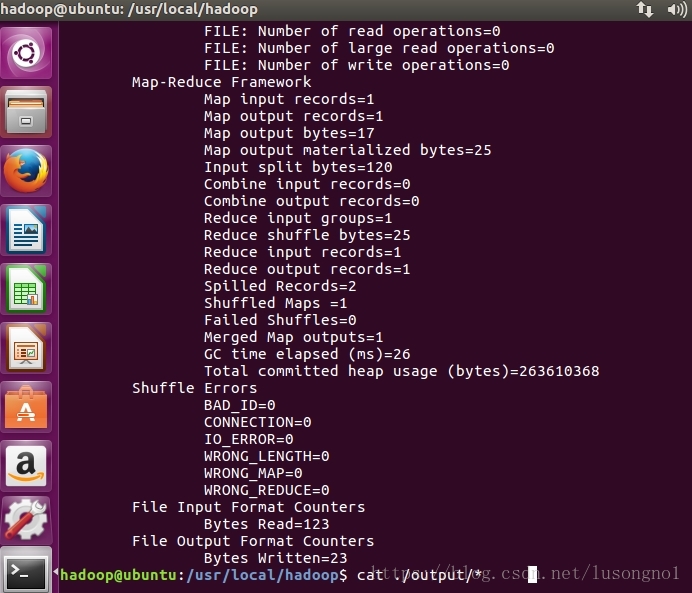
运行后得到结果 符合正则表达式dfs[a-z.]+出现了1次(dfsadmin)。
Hadoop伪分布式配置和测试
Hadoop伪分布式配置
- 打开
/usr/local/hadoop/etc/hadoop/目录下的core-site.xml 文件,修改
<configuration>
</configuration>为:
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>- 同理,打开
hdfs-site.xml文件,同样的配置部分修改为
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
</configuration>配置文件内容说明:若没有配置 hadoop.tmp.dir 参数,则默认使用的临时目录为 /tmp/hadoo-hadoop,而这个目录在重启时有可能被系统清理掉,导致必须重新执行 format 才行。
- NameNode 的格式化
./bin/hdfs namenode -format#这里的“.”表示的当前目录是hadoop安装目录下的hadoop文件夹,如我的是/usr/local/hadoop,下同,不再重述看到 “successfully formatted” 表示成功。
- 开启数据节点和名称节点的守护进程
./sbin/start-dfs.sh #start-dfs.sh是个完整的可执行文件,中间没有空格启动完成后,可以通过命令 jps 来判断是否成功启动。成功启动则会列出如下进程:
“NameNode”、
”DataNode”
“SecondaryNameNode”
- 成功启动后,可以访问 Web 界面 http://localhost:50070 查看 NameNode 和 Datanode 信息,还可以在线查看 HDFS 中的文件。
Hadoop伪分布式的实例测试
- 要使用 HDFS,首先需要在 HDFS 中创建用户目录,这里创建
/user/hadoop目录,接着在创建的hadoop下创建input文件夹,将本机配置文件拷贝进去。
./bin/hdfs dfs -mkdir -p /user/hadoop
./bin/hdfs dfs -mkdir input#input表示相对路径,即 /user/hadoop/input
./bin/hdfs dfs -put ./etc/hadoop/*.xml input- 查看文件列表
./bin/hdfs dfs -ls input- 伪分布式运行 MapReduce 作业的方式跟单机模式相同
./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar grep input output 'dfs[a-z.]+'- 查看测试结果
./bin/hdfs dfs -cat output/*- 结果取回本地,并进行查看
rm -r ./output # 先删除本地的 output 文件夹(如果存在)
./bin/hdfs dfs -get output ./output # 将 HDFS 上的 output 文件夹拷贝到本机
cat ./output/*运行程序时,输出目录不能存在,若存在,删除之。
- Hadoop的运行与关闭
./sbin/start-dfs.sh #运行
./sbin/stop-dfs.sh #关闭YARN的配置与启动
我们可以启动 YARN ,让 YARN 来负责资源管理与任务调度。
YARN 主要是为集群提供更好的资源管理与任务调度,然而这在单机上体现不出价值,反而会使程序跑得稍慢些。因此在这就不介绍如何开启 YARN 就了。
安装过程中遇到的一些问题
无法用apt命令安装包
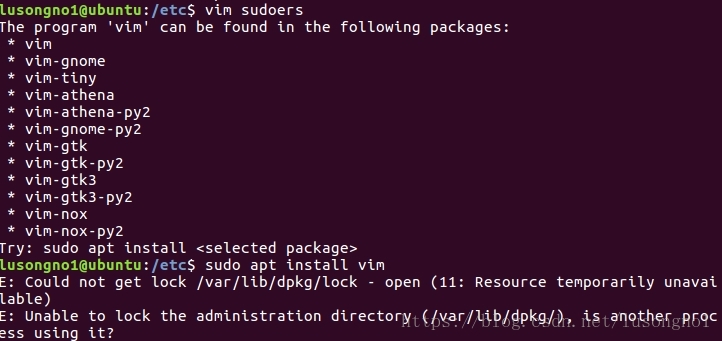
解决办法:找到并且杀掉所有的apt-get和apt进程
1、运行ps -A | grep apt命令来生成所有含有apt的进程列表
2、 运行sudo kill 进程名 processnumber杀掉进程
无法实现windows和虚拟机之间的复制黏贴
解决办法:
1、运行sudo apt-get autoremove open-vm-tools 。
2、运行sudo apt-get install open-vm-tools-desktop。
3、重新开机(Linux)。
更新apt时,普通用户执行sudo报hadoop is not in the sudoers file. This incident will be reported.
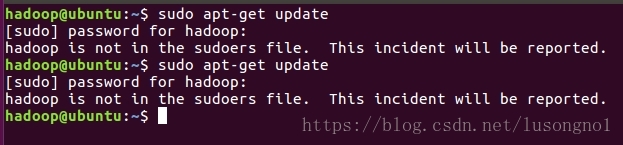
解决方法:
1、root用户登录。
2、进入到/etc目录。
3、执行sudo chmod u+w /etc/sudoers给sudoers文件增加write权限。
4、执行vim sudoers找到root ALL=(ALL) ALL这一行,在下面增加hadoop ALL=(ALL) ALL(注:hadoop为普通用户的用户名)。
5、执行命令chmod u-w sudoers,撤销write权限。
gedit在新建的账户中无法使用报错
Failed to connect to Mir: Failed to connect to server socket: No such file or directory
Unable to init server: Could not connect: Connection refused
(gedit:12224): Gtk-WARNING **: cannot open display:


这个我最后是通过重启客户端解决的。
最后
以上就是专注金鱼最近收集整理的关于Linux(ubuntu-16.04.2)上hadoop的安装与配置Linux(ubuntu-16.04.2)上hadoop(hadoop-2.7.1)的安装与配置的全部内容,更多相关Linux(ubuntu-16.04.2)上hadoop内容请搜索靠谱客的其他文章。








发表评论 取消回复