文章目录
- 一、JDK的安装
- 二、Hadoop 安装
- 三、Hadoop 配置
- 四、启动与测试
资源获取:https://download.csdn.net/download/qq_45797116/15869560
一、JDK的安装
解压至home目录:tar -zxvf jdk-8u281-linux-x64.tar.gz -C /home/

重命名:mv jdk1.8.0_161/ java

配置环境变量:vi /etc/profile
export JAVA_HOME=/home/java
export PATH=$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$PATH
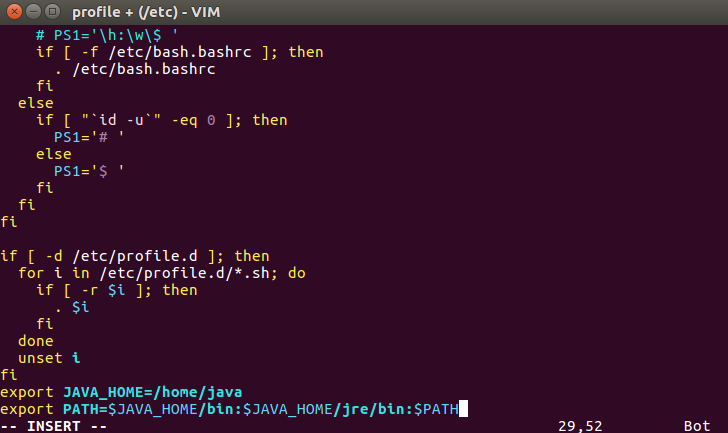
使环境变量生效 source /etc/profile
测试是否安装成功:java -version

返回顶部
二、Hadoop 安装
将hadoop安装包解压至指定目录 tar -zxvf hadoop-2.7.6.tar.gz -C /home/

重命名:mv hadoop-2.7.6/ hadoop

配置环境变量
export HADOOP_HOME=/home/hadoop
export PATH=.:$HADOOP_HOME/bin:$JAVA_HOME/bin:$PATH
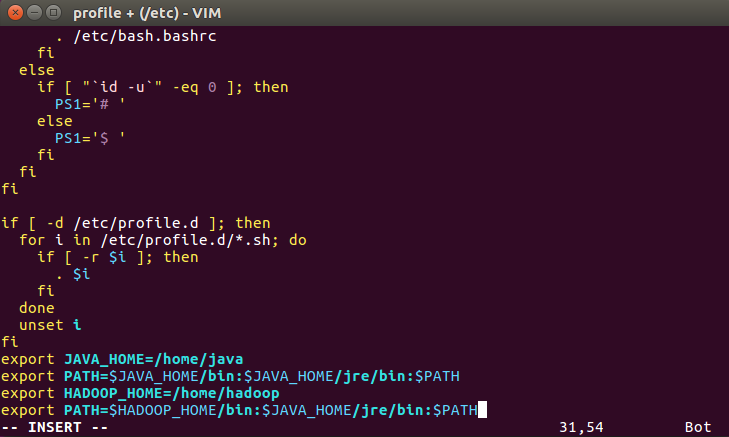
使环境变量生效 source /etc/profile
测试是否安装成功:hadoop version
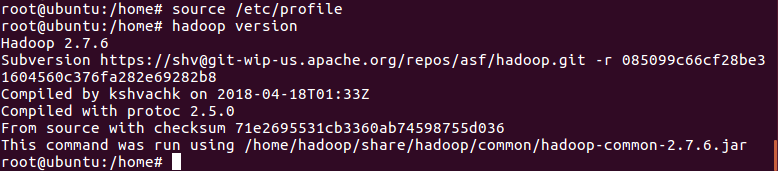
返回顶部
三、Hadoop 配置
在hadoop根目录下创建几个文件夹
mkdir tmp 用来指定使用hadoop时产生文件的存放目录
mkdir -p hdfs/name 指定hdfs中namenode的存储位置
mkdir hdfs/data 指定hdfs中datanode的存储位置
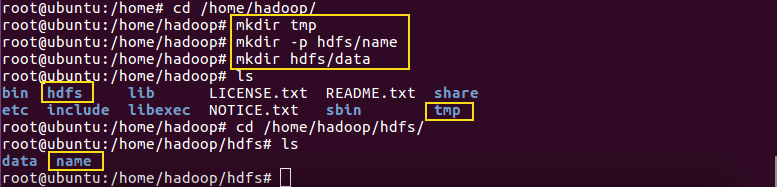
然后进入/home/hadoop/ets/hadoop/目录下进行配置文件的修改:
hadoop运行需要jre环境,可以直接在/etc/profile中配置,也可以在hadoop-env.sh和yarn-env.sh文件中进行单独配置配置,在hadoop-env.sh和yarn-env.sh中可以对JVM虚拟机相关参数进行设置:
-
修改hadoop-env.sh

-
修改 yarn-env.sh

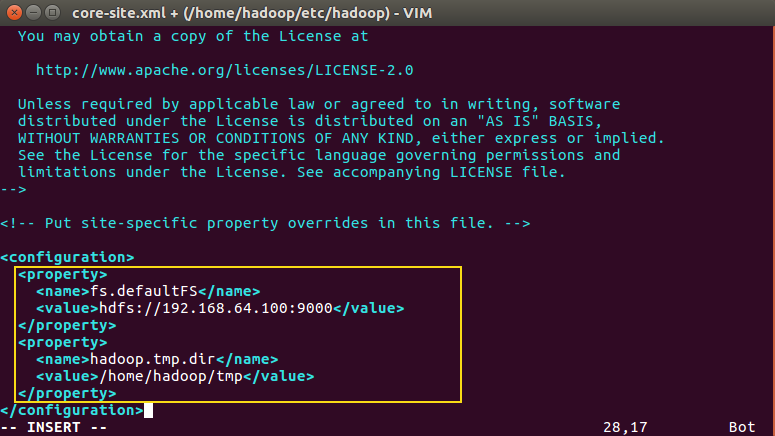
- 修改core-site.xml
<!--指定namenode的地址-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value> // master改成虚拟机系统的ip
</property>
<!--用来指定使用hadoop时产生文件的存放目录-->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/tmp</value>
</property>
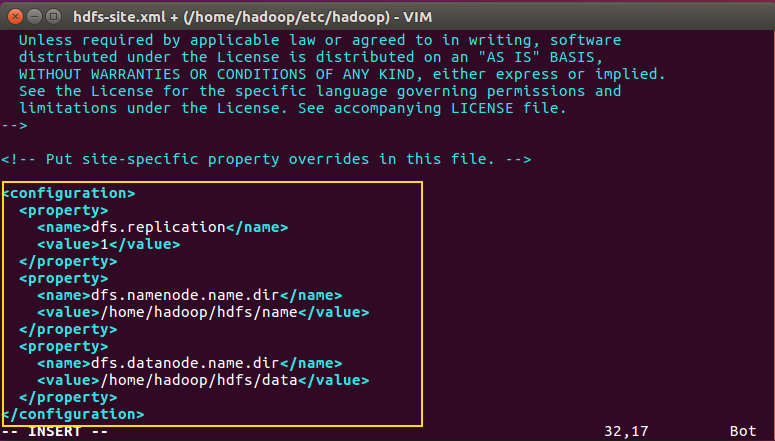
- 修改hdfs-site.xml
<!--指定hdfs保存数据的副本数量-->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<!--指定hdfs中namenode的存储位置-->
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/hadoop/hdfs/name</value>
</property>
<!--指定hdfs中datanode的存储位置-->
<property>
<name>dfs.datanode.name.dir</name>
<value>/home/hadoop/hdfs/data</value>
</property>
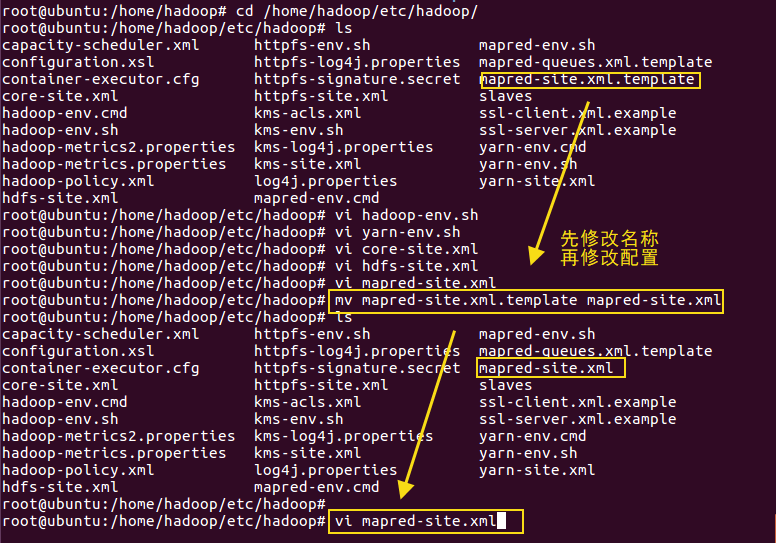
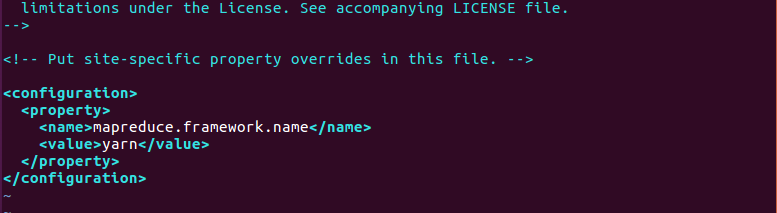
- 修改mapred-site.xml
<!--告诉hadoop以后MR(Map/Reduce)运行在YARN上-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
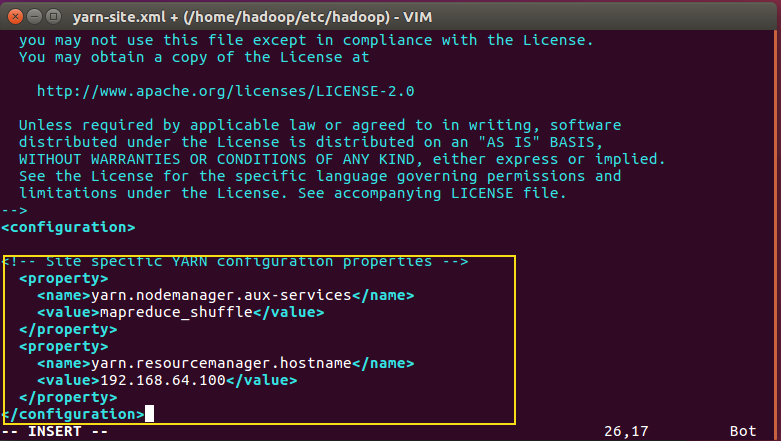
- 修改yarn-site.xml
<!--nomenodeManager获取数据的方式是shuffle-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!--指定Yarn的老大(ResourceManager)的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
返回顶部
四、启动与测试
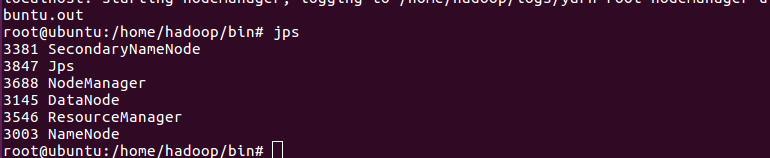
初始化 namenode:bin/hadoop namenode -format
开启节点:/home/hadoop/sbin/start-all.sh
查看进程:jps
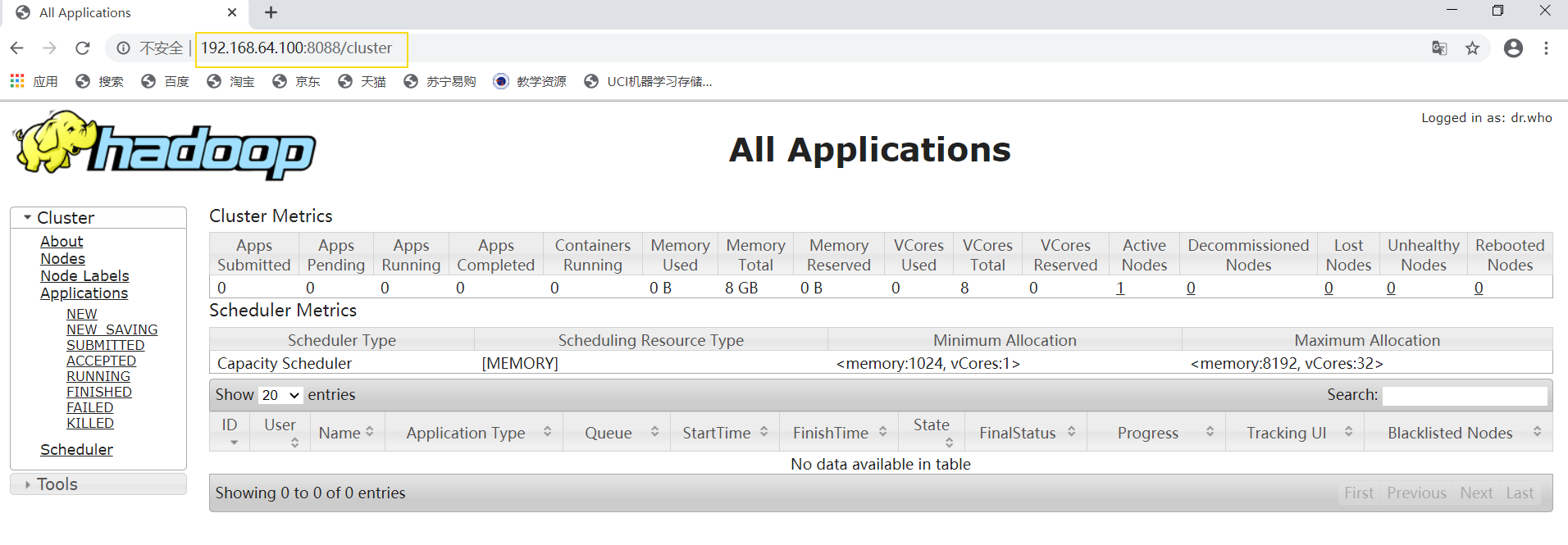
http://192.168.64.100:8088/cluster
http://192.168.64.100:50070/
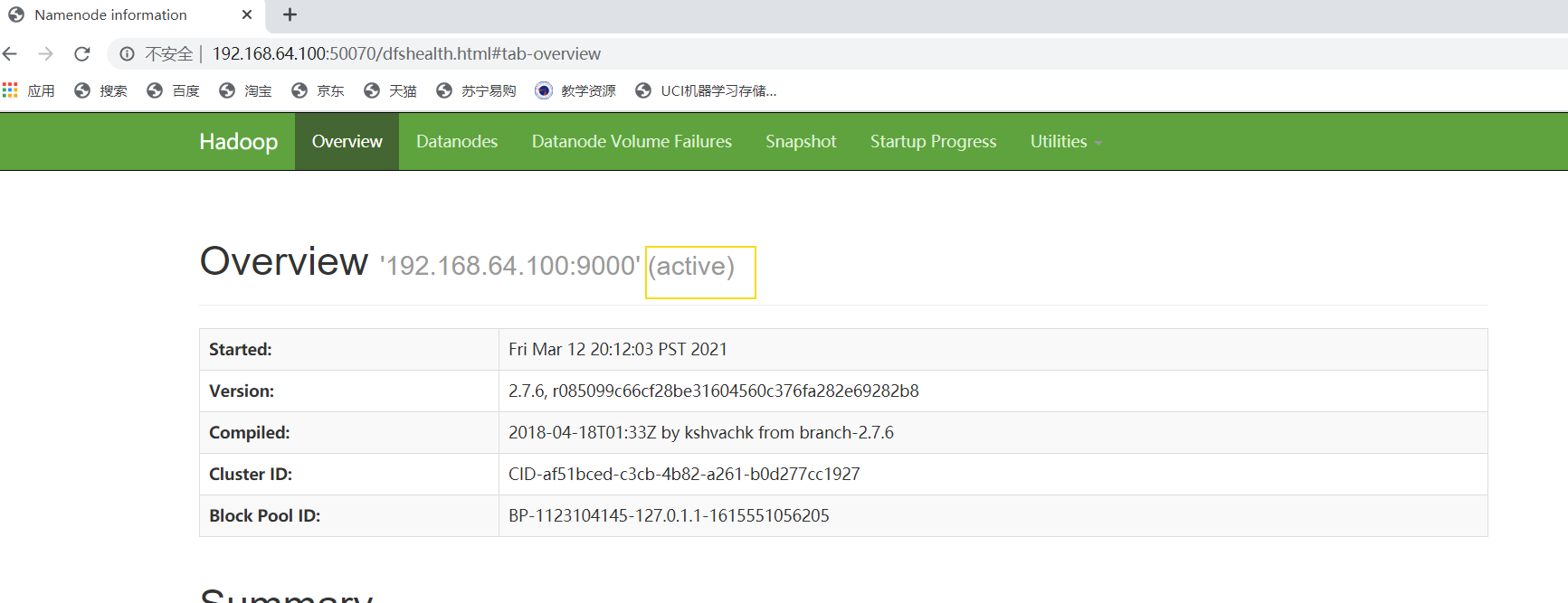
返回顶部
最后
以上就是潇洒冥王星最近收集整理的关于【Ubuntu】Hadoop 伪分布式安装的全部内容,更多相关【Ubuntu】Hadoop内容请搜索靠谱客的其他文章。








发表评论 取消回复