模型评估
正负样本的选择:
- 以少数样本为正样本
以违约样本为正样本,更加关注对坏样本预测能力的业务场景。
业务关注对坏样本的预测能力。
- 以多数样本为正样本
以没有违约的为正样本,直观上好理解
更加关注坏账率和通过率。
标准评估指标
回归问题的评估指标
SSE(和方差、残差平方和)
: 计算的是拟合数据和原始数据对应点的误差的平方和。越接近于0,说明模型选择和拟合更好,数据预测也越成功。
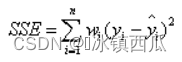
MSE(均方误差,方差)
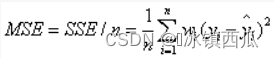

标准差

协方差
:在概率论和统计学中,协方差用于衡量两个变量的总体误差。协方差应该只能表示线性相关性
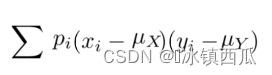
或者
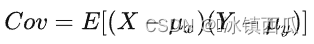
相关度(皮尔逊相关系数)
:衡量两个值线性相关强度的量 取值范围[-1,1]:正向相关>0,负向相关<0,无相关性=0
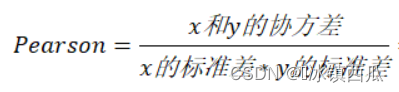
分类问题的评估指 标
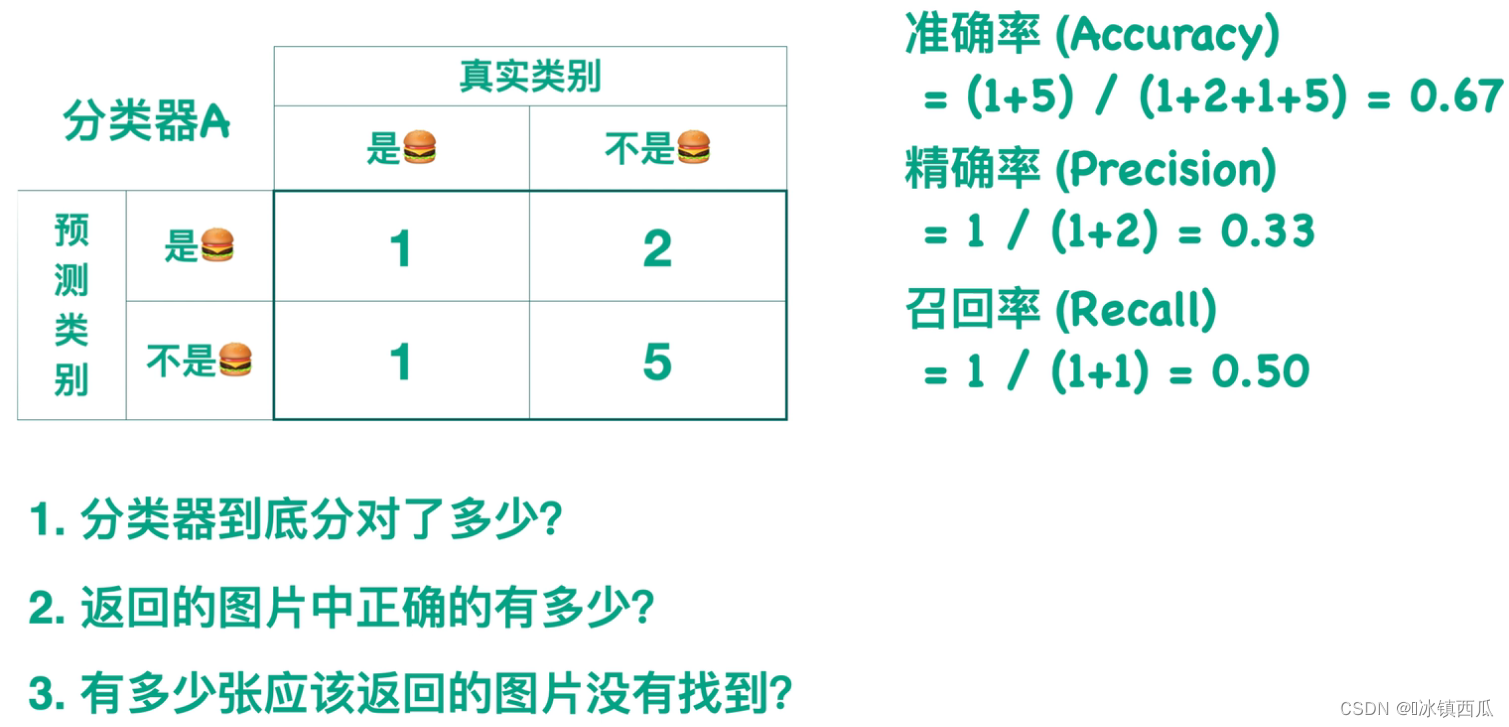
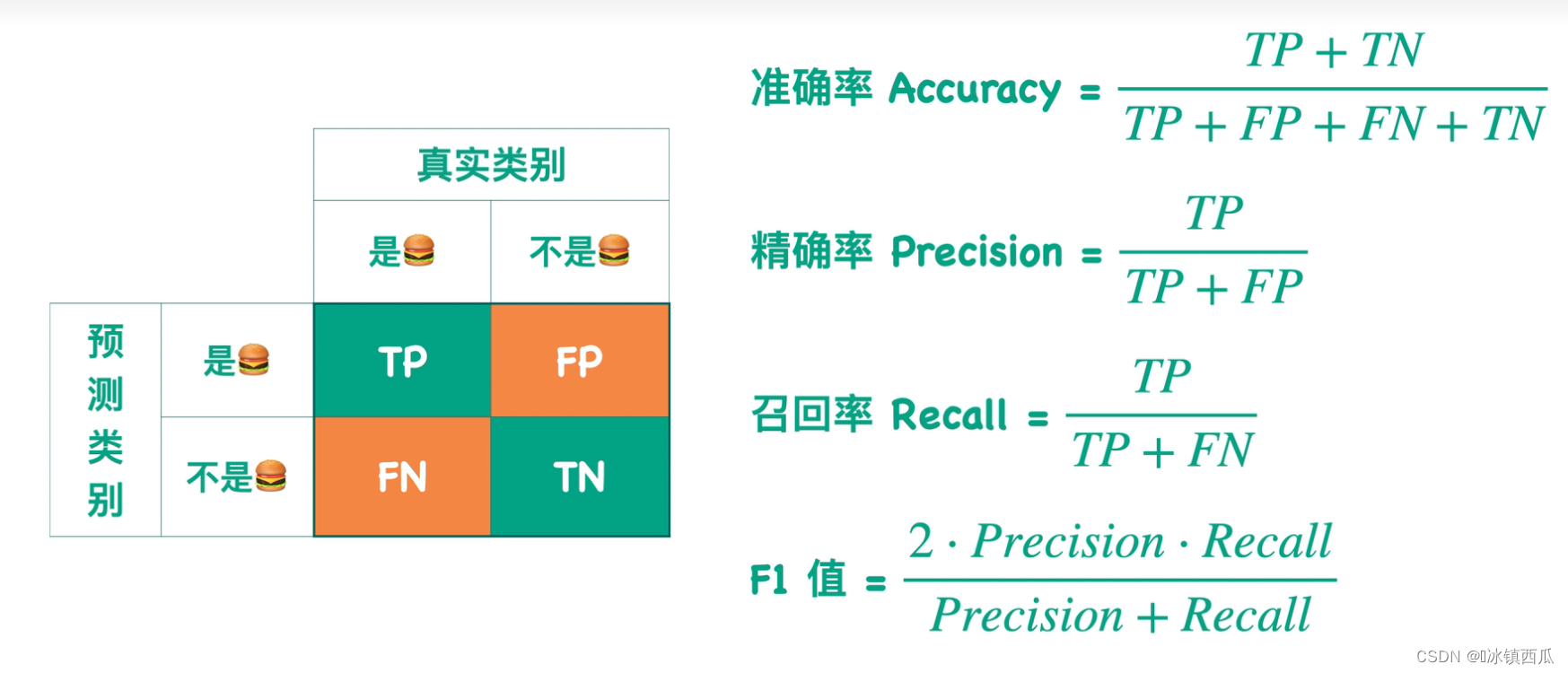
混淆矩阵
P代表预测的是正例、N代表预测的是反例
T代表预测正确预测、F代表错误预测
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-tHiob0AX-1661850893439)(C:Users李文龙AppDataRoamingTyporatypora-user-imagesimage-20220830155414882.png)]](https://www.shuijiaxian.com/files_image/2023061118/e720c53fa32941f8af785bf4d0fd6c27.png)
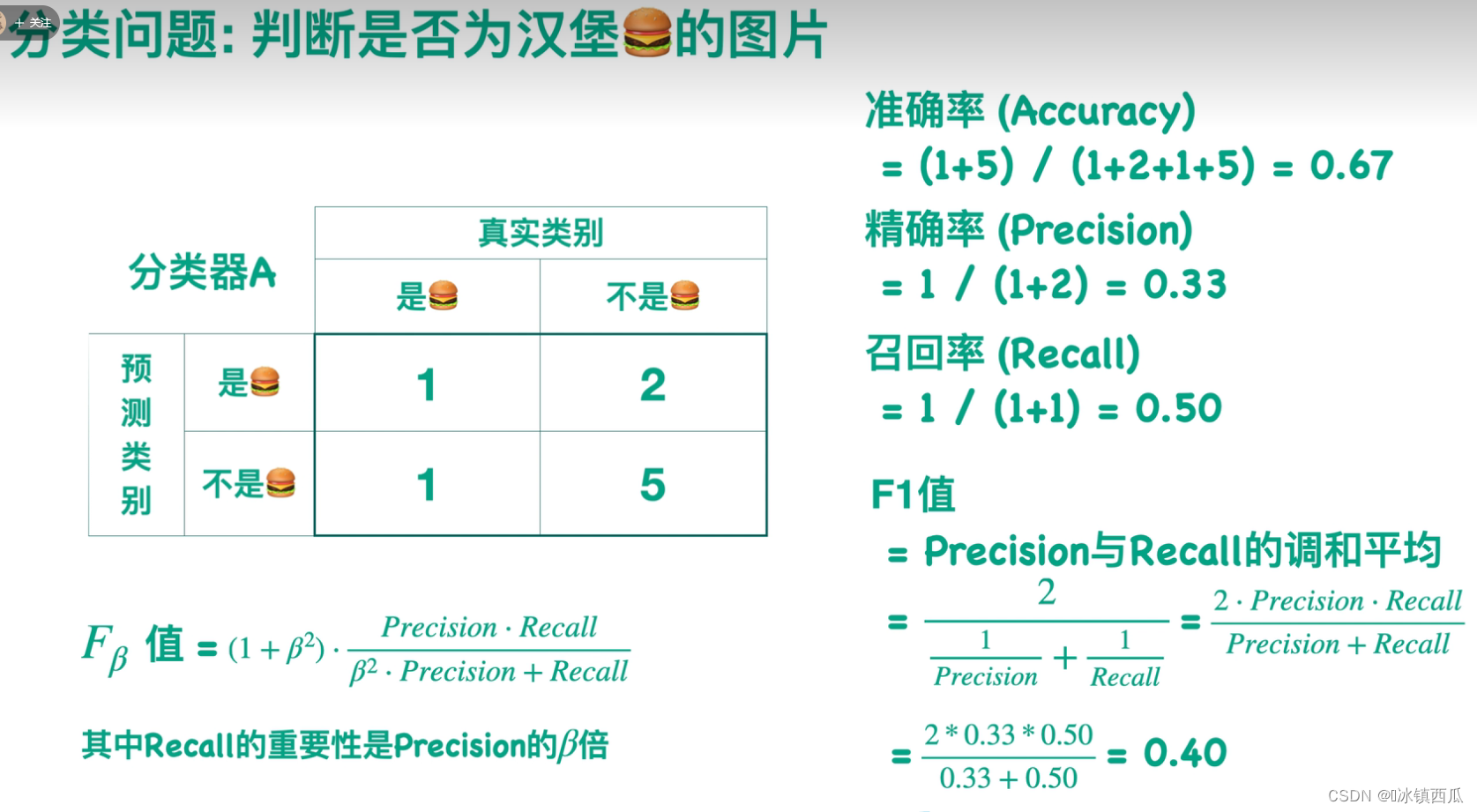
准确率(Accuracy)
分对的数量占总数量的比例。
精确率(Precision)
被预测为正类样本中真正正类的比例。
召回率(Recall)
应该预测的类别中真正返回的比例。召回率衡量了在所有正例中模型正确预测的概率。召回率与精确率是相对的,召回率越高,精确率越低。
F1分值
综合考虑了召回率与精准率两种情况
最后
以上就是有魅力金毛最近收集整理的关于模型评估方法的全部内容,更多相关模型评估方法内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复