压缩解压缩:
文件很大:有损压缩 无损压缩
png:有损压缩 最为常见的9个像素合为1个像素
哈夫曼树:最佳搜索树
假如:
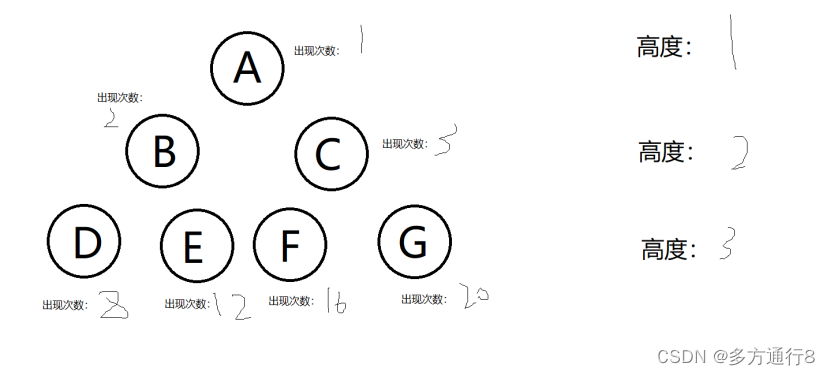
看看所有数据的查找次数:1*1+(2+3)*2+(8+12+16+20)*3=179
如果我们将出现次数最多的放在上层,比如:
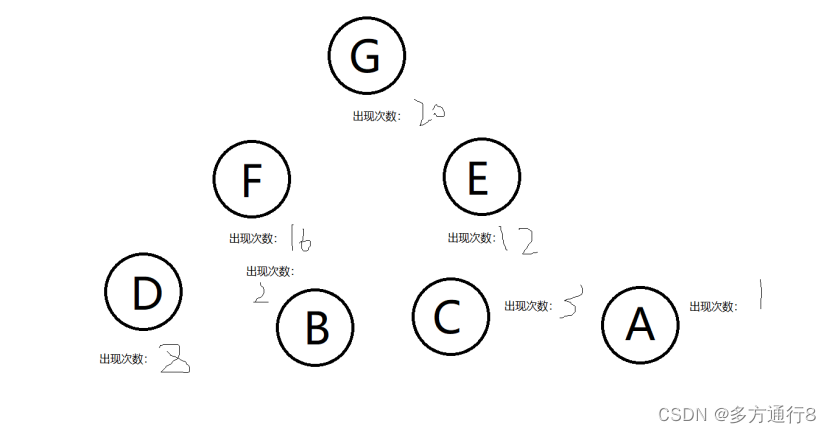
则,查找次数:20*1+(16+12)*2+(8+2+3+1)*3=128
而179 >128
这也是为什么哈夫曼树为最佳搜索树的原因
举例:写在用的智能输入法,用的字的次数越多,那个字出现在前面就越多,就是用哈夫曼树的一种构建方式。
频率高的越容易找到,低的越不容易找到。
为什么可以用来解压缩:
假如我打了一堆字符54个字母,一个字母一字节,那么就需要54字节去存储

而我们对这些字节从小到大进行存储:
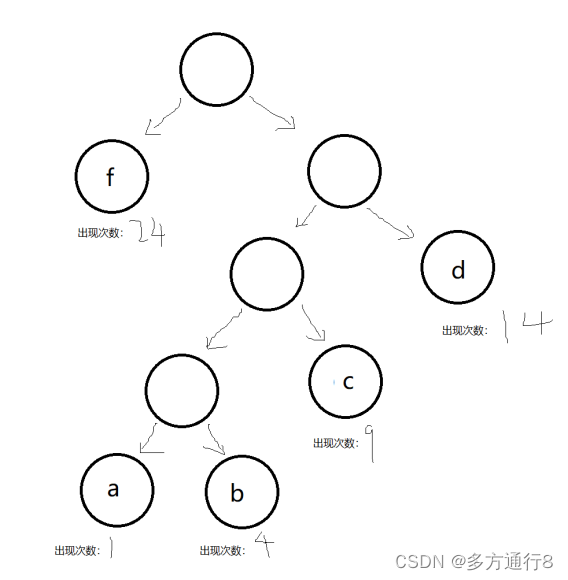
空白的为空字节,然后我们以左边的节点为0,右边的节点为1
则:
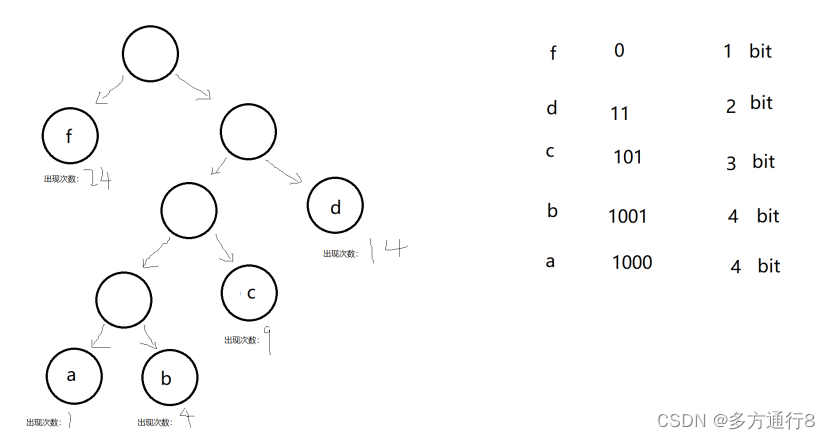
所以我们可以开始计算:1*24 + 2*14 + 3*9 + 4*4 + 4*1=99bit
99bit -> 13字节不到
本质上进行了压缩
出现频率高的编码就越短,出现频率低的编码就越长
如何实现:
1.压缩过程:
1.分析待压缩文件
获取文件中出现的字节 和 每个出现字节出现的次数 组合成字典(索引)
- 根据字典组建哈夫曼树,获取每个字节对应的哈夫曼编码
- 读待压缩文件 创建压缩后文件,把字典写入压缩后文件中
然后一个一个字节去读待压缩文件的 把它转换成对应的编码
把编码写入压缩后文件中
2.解压缩过程:
1.从压缩后文件中读取字典
2.根据字典生成哈夫曼树
3.循环从压缩后文件中读取字节
一个个bit位获取 根据bit位的值去哈夫曼树中寻找
找到一个节点就解压一个字节
没有孩子了仍然向右说明结束了
测试: 待解压文件名: 1.txt
压缩后文件名: 2.txt
解压后文件名: 3.txt
通过节点来创建数组,在数组里面找到最小的两个,然后数组里面添加空的节点(最小两个的和),然后在寻找最小两个节点
压缩代码:
#define _CRT_SECURE_NO_WARNINGS
#include<stdio.h>
#include<string>
//测试用,为1,如果不想测试,改为0即可
#define TESTHAFFMANCODE 0
#define TESTWRITECHAR 0
//哈夫曼编码长度 文件中字符种类越多,对应哈夫曼编码越长
#define HFM_CODE_LEN 10
struct ZiFu
{
unsigned char zf; //字符
unsigned int count; //字符出现次数
char code[HFM_CODE_LEN]; //哈夫曼编码
int idx; //字符数组下标
};
//做字典
struct allZiFu
{
int zf_count;//出现过字符的个数
ZiFu arr[256];//存储每个字符的信息
};
//哈夫曼树节点类型
struct treeNode
{
ZiFu data;
treeNode* pLeft;
treeNode* pRight;
treeNode* pParent;
};
//创建树的新节点
treeNode* creatNode(ZiFu* pzf);
//分析文件得到字典(出现过字符的个数 字符 字符出现次数)
void analysisFile(char* srcFile, allZiFu* zd);
//创建哈夫曼树并返回
treeNode* creatHaffmanTree(allZiFu* zd);
//根据哈夫曼树,创建哈夫曼编码,并写入字典中
void creatHaffmanCode(treeNode* root, allZiFu* zd);
//判断当前节点是否是叶子节点
bool isLeaf(treeNode* root);
//设置哈夫曼编码到字典
void setHaffmanCode(treeNode* root, char* pCodeStar);
//把字典和对应字符的编码写到压缩后文件中
void writeCompressFile(char* srcFile, char* dstFile, allZiFu* zd);
//从字典中获取某个字符的哈夫曼编码
void getHaffmanCode(char c, char* haffmanCode, allZiFu* zd);
int main()
{
char srcFile[256] = "1.txt";//待压缩文件
char dstFile[256] = "2.txt";//压缩后文件
allZiFu zd={0};//字典
analysisFile(srcFile, &zd);//分析好文件
treeNode* root = NULL;
root = creatHaffmanTree(&zd);
creatHaffmanCode(root, &zd);
writeCompressFile(srcFile, dstFile,&zd);//写压缩文件
printf("压缩完毕");
system("pause");
return 0;
}
treeNode* creatNode(ZiFu* pzf)
{
treeNode* pNew = (treeNode*)malloc(sizeof(treeNode));
if (NULL== pNew)
{
printf("哈夫曼树空白节点创建失败");
return NULL;
}
memset(pNew, 0, sizeof(treeNode));
memcpy(pNew->data.code, pzf->code, HFM_CODE_LEN);//拷贝
pNew->data.count = pzf->count;
pNew->data.zf = pzf->zf;
pNew->data.idx = pzf->idx;
return pNew;
}
void analysisFile(char* srcFile, allZiFu* zd)
{
//1.打开文件
FILE* fp = fopen(srcFile, "rb");//二进制只读
if (NULL==fp)
{
printf("analysisFile函数,打开待压缩文件%s失败。n",srcFile);
return;
}
//2.读取文件内容
unsigned char c; //存储读到的字节
int r; //fread返回值
bool isRead; //标记是否出现
int i;
while (1)//循环读取
{
//读取字节,读不到结束
r = fread(&c, 1, 1, fp);
if (1 != r)
{
break;
}
//判断是否出现过
isRead = false;
for (i = 0; i < zd->zf_count; i++)
{
if (c == zd->arr[i].zf)//说明出现过
{
isRead = true;
break;
}
}
#if 0
// 出现,统计次数加1
if (isRead)
{
zd->arr[i].count++;
}
else//如果没有出现,存储,统计次数加1
{
zd->zf_count++;//字符个数增加
zd->arr[i].zf = c;//记录字符
zd->arr[i].count++;
}
#else
if (!isRead)//如果没有出现
{
zd->zf_count++;//字符个数增加
zd->arr[i].zf = c;//记录字符
}
zd->arr[i].count++;
#endif // 0
}
//3.关闭
}
treeNode* creatHaffmanTree(allZiFu* zd)
{
//准备指针数组 存储所有节点
treeNode** treeArray = (treeNode**)malloc(sizeof(treeNode*) * zd->zf_count);
//容器也可以 vector<treeNode*> buff;for循环就行了
for (int i = 0; i < zd->zf_count; i++)
{
treeArray[i] = creatNode(&(zd->arr[i]));
treeArray[i]->data.idx = i;//下标
}
//循环找最小的和第二小的 循环zd->zf_count-1次
int minIdx, secMinIdx;
int j;
treeNode* pTemp=NULL;
for (int i = 0; i < zd->zf_count-1; i++)
{
//找出最小的和第二小的
j = 0;
while (treeArray[j]==NULL)
{
j++;//让j是第一个的下标
}
minIdx = j;
for (j= 0; j < zd->zf_count; j++)
{
if (treeArray[j] &&
treeArray[j]->data.count< treeArray[minIdx]->data.count)
{
minIdx = j;
}
}
//找出第二小的
j = 0;
while (treeArray[j]==NULL ||j==minIdx)
{
j++;
}
secMinIdx = j;
for (j = 0; j < zd->zf_count; j++)
{
if (treeArray[j] && j!=minIdx &&
treeArray[j]->data.count < treeArray[secMinIdx]->data.count)
{
secMinIdx = j;
}
}
//组合为树
//制作父节点的数据
ZiFu tempZF = { 0,treeArray[minIdx]->data.count + treeArray[secMinIdx]->data.count };
tempZF.idx = -1;//保险
pTemp = creatNode(&tempZF);
pTemp->pLeft = treeArray[minIdx];
pTemp->pRight = treeArray[secMinIdx];
treeArray[minIdx]->pParent = pTemp;
treeArray[secMinIdx]->pParent = pTemp;
//数组添加(最小的和第二小的)父 删除最小的和第二小的
treeArray[minIdx] = pTemp;
treeArray[secMinIdx] = NULL;
}
return pTemp;
}
void creatHaffmanCode(treeNode* root, allZiFu* zd)
{
int idx;
if (root)
{
if (isLeaf(root))
{
idx = root->data.idx;
setHaffmanCode(root, zd->arr[idx].code);//往上去找父
}
else
{
creatHaffmanCode(root->pLeft, zd);
creatHaffmanCode(root->pRight, zd);
}
}
}
bool isLeaf(treeNode* root)
{
if (root && NULL==root->pLeft && NULL == root->pRight)
{
return true;
}
return false;
}
void setHaffmanCode(treeNode* root, char* pCodeStar)
{
treeNode* pTemp = root;
char buff[HFM_CODE_LEN] = { 0 };
int buffIdx = 0;
while (pTemp->pParent)//一路往上
{
if (pTemp==pTemp->pParent->pLeft)//左
{
buff[buffIdx] = 1;
}
else//右
{
buff[buffIdx] = 2;
}
buffIdx++;
pTemp = pTemp->pParent;
}
//逆转存储到参数数组中
char temp;
for (int i = 0; i < buffIdx/2; i++)
{
temp = buff[i];
buff[i] = buff[buffIdx - i - 1];
buff[buffIdx - i - 1] = temp;
}
//赋值
strcpy(pCodeStar, buff);
}
void writeCompressFile(char* srcFile, char* dstFile, allZiFu* zd)
{
//创建压缩后文件 打开待压缩文件
FILE* fpSrc = fopen(srcFile, "rb");
FILE* fpDst = fopen(dstFile, "wb");
if (NULL== fpSrc || NULL== fpDst)
{
printf("writeCompressFile函数打开文件失败n");
return;
}
//把字典写入压缩后文件中
fwrite(zd, 1, sizeof(allZiFu), fpDst);
//读待压缩文件 一个个字节读 对照字典中的哈夫曼编码 得到对应的二进制,
//每拼成一个字节(8bit)写入压缩后文件中
char c;//储存读到的字节
int r;
char charForWrite;//储存写入压缩后文件的字节(二进制位拼接而来)
int idxForWrite;//charForWrite的二进制位索引
char haffmanCode[HFM_CODE_LEN] = { 0 };//临时储存编码
int haffmanCodeIdx=0;
bool isEnd = false;
while (1)
{
if (0==haffmanCode[haffmanCodeIdx])
{
r = fread(&c, 1, 1, fpSrc);
if (1 != r)
{
break;
}
getHaffmanCode(c, haffmanCode, zd);
haffmanCodeIdx = 0;
}
#if TESTHAFFMANCODE
printf("%c ==============", c);
for (int i = 0; i <HFM_CODE_LEN ; i++)
{
printf("%d", haffmanCode[i]);
}
printf("n");
#endif // TESTHAFFMANCODE
//哈夫曼编码变成二进制储存到charForWrite里面,8个bit位写入fpDst一次
idxForWrite = 0;
charForWrite = 0;
while (idxForWrite<8)
{
if (2==haffmanCode[haffmanCodeIdx])//设置对应bit位为0
{
charForWrite &= ~(1 << (7 - idxForWrite));
haffmanCodeIdx++;
idxForWrite++;
}
else if(1 == haffmanCode[haffmanCodeIdx])
{
charForWrite |= (1 << (7 - idxForWrite));
haffmanCodeIdx++;
idxForWrite++;
}
else//读取下一个字符或者结束
{
r = fread(&c, 1, 1, fpSrc);
if (1!=r)
{
isEnd = true;
break;
}
getHaffmanCode(c, haffmanCode, zd);
haffmanCodeIdx = 0;
#if TESTHAFFMANCODE
printf("%c ==============", c);
for (int i = 0; i < HFM_CODE_LEN; i++)
{
printf("%d", haffmanCode[i]);
}
printf("n");
#endif // TESTHAFFMANCODE
}
}
fwrite(&charForWrite, 1, 1, fpDst);//写入压缩后文件中
#if TESTWRITECHAR
for (int i = 0; i < 8; i++)
{
if ((charForWrite & 0x80) == 0x80)
{
printf("1");
}
else
{
printf("0");
}
charForWrite <<= 1;
}
printf("n");
#endif // TESTWRITECHAR
if (isEnd)
{
break;
}
}
//关闭保存
fclose(fpSrc);
fclose(fpDst);
}
void getHaffmanCode(char c, char* haffmanCode, allZiFu* zd)
{
for (int i = 0; i < zd->zf_count; i++)
{
if (c==zd->arr[i].zf)
{
strcpy(haffmanCode,zd->arr[i].code);
break;
}
}
}
解压代码:
#define _CRT_SECURE_NO_WARNINGS
#include<stdio.h>
#include<string>
#define HFM_CODE_LEN 10
struct ZiFu
{
unsigned char zf; //字符
unsigned int count; //字符出现次数
char code[HFM_CODE_LEN]; //哈夫曼编码
int idx; //字符数组下标
};
//做字典
struct allZiFu
{
int zf_count;//出现过字符的个数
ZiFu arr[256];//存储每个字符的信息
};
//哈夫曼树节点类型
struct treeNode
{
ZiFu data;
treeNode* pLeft;
treeNode* pRight;
treeNode* pParent;
};
treeNode* creatNode(ZiFu* pzf);
treeNode* creatHaffmanTree(allZiFu* zd);
bool isLeaf(treeNode* root);
int main()
{
char srcFile[256] = "2.txt";//压缩后文件
char dstFile[256] = "3.txt";//解压后文件
allZiFu zd = { 0 };//字典
//1.读取字典
FILE* fpSrc = fopen(srcFile, "rb");
fread(&zd, 1, sizeof(allZiFu), fpSrc);
//根据字典生成哈夫曼树
treeNode* root = creatHaffmanTree(&zd);
//循环读取
//统计字节数
int allCount = root->data.count;
int myCount = 0;
char temp;
int bit_idx;//bit位索引
treeNode* tempNode = root;
FILE* fpDst=fopen(dstFile,"wb");
bool isOver = false;
while (1 == fread(&temp, 1, 1, fpSrc))
{
bit_idx = 0;
while (bit_idx < 8)
{
if ((0x80>>bit_idx)==(temp&(0x80>>bit_idx)))//当前位为1;
{
tempNode = tempNode->pLeft;
}
else
{
tempNode = tempNode->pRight;
}
if (isLeaf(tempNode))
{
fwrite(&(tempNode->data.zf), 1, 1, fpDst);
myCount++;
if (myCount >= allCount)
{
isOver = true;
break;
}
tempNode = root;
}
bit_idx++;
}
if (isOver)
{
break;
}
}
fclose(fpSrc);
fclose(fpDst);
printf("解压缩完毕");
system("pause");
return 0;
}
treeNode* creatNode(ZiFu* pzf)
{
treeNode* pNew = (treeNode*)malloc(sizeof(treeNode));
if (NULL == pNew)
{
printf("哈夫曼树空白节点创建失败");
return NULL;
}
memset(pNew, 0, sizeof(treeNode));
memcpy(pNew->data.code, pzf->code, HFM_CODE_LEN);//拷贝
pNew->data.count = pzf->count;
pNew->data.zf = pzf->zf;
pNew->data.idx = pzf->idx;
return pNew;
}
treeNode* creatHaffmanTree(allZiFu* zd)
{
//准备指针数组 存储所有节点
treeNode** treeArray = (treeNode**)malloc(sizeof(treeNode*) * zd->zf_count);
//容器也可以 vector<treeNode*> buff;for循环就行了
for (int i = 0; i < zd->zf_count; i++)
{
treeArray[i] = creatNode(&(zd->arr[i]));
treeArray[i]->data.idx = i;//下标
}
//循环找最小的和第二小的 循环zd->zf_count-1次
int minIdx, secMinIdx;
int j;
treeNode* pTemp = NULL;
for (int i = 0; i < zd->zf_count - 1; i++)
{
//找出最小的和第二小的
j = 0;
while (treeArray[j] == NULL)
{
j++;//让j是第一个的下标
}
minIdx = j;
for (j = 0; j < zd->zf_count; j++)
{
if (treeArray[j] &&
treeArray[j]->data.count < treeArray[minIdx]->data.count)
{
minIdx = j;
}
}
//找出第二小的
j = 0;
while (treeArray[j] == NULL || j == minIdx)
{
j++;
}
secMinIdx = j;
for (j = 0; j < zd->zf_count; j++)
{
if (treeArray[j] && j != minIdx &&
treeArray[j]->data.count < treeArray[secMinIdx]->data.count)
{
secMinIdx = j;
}
}
//组合为树
//制作父节点的数据
ZiFu tempZF = { 0,treeArray[minIdx]->data.count + treeArray[secMinIdx]->data.count };
tempZF.idx = -1;//保险
pTemp = creatNode(&tempZF);
pTemp->pLeft = treeArray[minIdx];
pTemp->pRight = treeArray[secMinIdx];
treeArray[minIdx]->pParent = pTemp;
treeArray[secMinIdx]->pParent = pTemp;
//数组添加(最小的和第二小的)父 删除最小的和第二小的
treeArray[minIdx] = pTemp;
treeArray[secMinIdx] = NULL;
}
return pTemp;
}
bool isLeaf(treeNode* root)
{
if (root && NULL == root->pLeft && NULL == root->pRight)
{
return true;
}
return false;
}最后
以上就是完美电话最近收集整理的关于哈夫曼解压缩解压缩学习的全部内容,更多相关哈夫曼解压缩解压缩学习内容请搜索靠谱客的其他文章。








发表评论 取消回复