文章目录
- 前言
- 一、传统RNN
- 双向RNN
- 深层双向RNN
- 二、LSTM
- 第一层
- 第二层
- 第三层
- 第四层
- 三、GRU
- 四、 LSTM和GRU区别
- 参考
前言
为了复习NLP自己的相关知识,整理一个博客
一、传统RNN
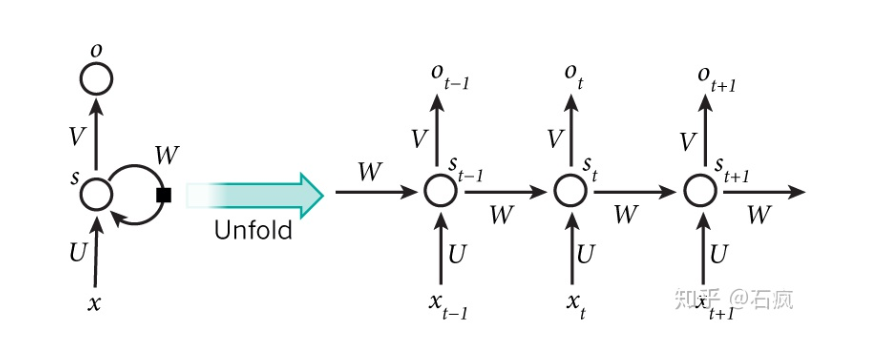
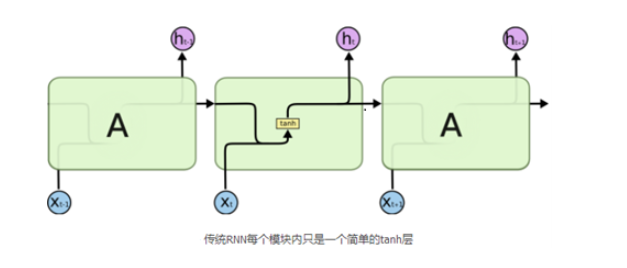
传统的RNN也即BasicRNNcell单元。内部的运算过程为,(t-1)时刻的隐层输出与w矩阵相乘,与t时刻的输入乘以u之后的值进行相加,然后经过一个非线性变化(tanh或Relu),然后以此方式传递给下一个时刻。
传统的RNN每一步的隐藏单元只是执行一个简单的tanh或者Relu操作。对于激活函数有遗忘的话,可以参考下面文章复习一下。(博主在前几天的面试就被问到了最基本的激活函数问题)
神经网络激活函数汇总(Sigmoid、tanh、ReLU、LeakyReLU、pReLU、ELU、maxout)
常用激活函数优缺点及性能对比
比如一个句子中有5个词,要给这5个词标注词性,那相应的RNN就是个5层的神经网络,每一层的输入是一个词,每一层的输出是这个词的词性。

聊聊文本的分布式表示: Distributional Representation和Distributed Representation的区别
RNN什么时候网络层次比较深呢?
RNN如果有多个时刻输入的时候,网络层次比较深,此时反向传播的路径比较长。反向传播是根据链式法则,如果开始的梯度小于1的话,则最后时刻的梯度几乎为0,则可理解为梯度消失;反之,若开始的梯度大于1的话,则最后时刻的梯度则非常大,可理解为梯度爆炸。这种情况下,开始应用Relu激活函数。
为什么应用Relu函数呢?
Relu函数在小于0时的梯度为0,大于0的时候梯度为1。使用Relu的好处:1 梯度容易求解;2 不会产生梯度消失或梯度爆炸。
双向RNN
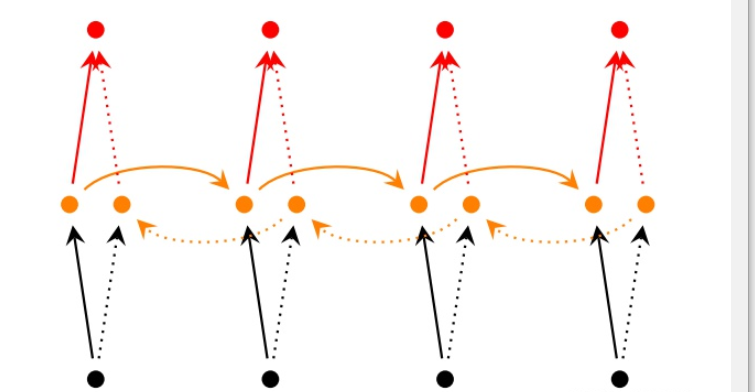
双向RNN认为otot不仅依赖于序列之前的元素,也跟tt之后的元素有关,这在序列挖掘中也是很常见的事实。
深层双向RNN
在双向RNN的基础上,每一步由原来的一个隐藏层变成了多个隐藏层。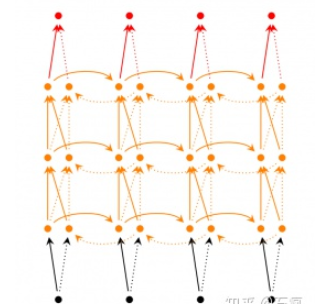
二、LSTM
优点:
可以在解决梯度消失和梯度爆炸的问题,还可以从语料中学习到长期依赖关系。
图中可以看出,t时刻有两个输出,上面代表长期输出,下面代表短期输出,用短期的输出与矩阵v运算得到t时刻的输出。
Tanh和sigmoid激活函数的优点?
首先tanh激活函数的范围是(-1,1),负的部分可以减一些信息,也即来控制忘记还是记忆信息,而sigmoid激活函数是用来表示记住多少的信息。
第一层
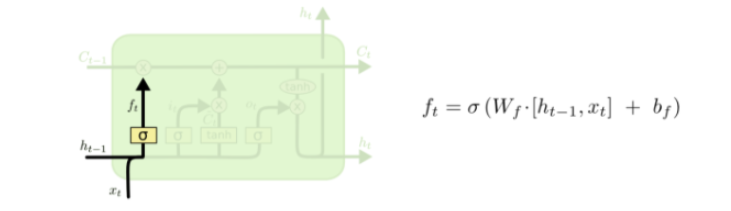
第一层是个忘记层,决定细胞状态中丢弃什么信息。把 ht-1 和 xt 拼接起来,传给一个Ct-1函数,该函数输出0到1之间的值,这个值乘到细胞状态 [公式] 上去。sigmoid函数的输出值直接决定了状态信息保留多少。比如当我们要预测下一个词是什么时,细胞状态可能包含当前主语的性别,因此正确的代词可以被选择出来。当我们看到新的主语,我们希望忘记旧的主语。
第二层
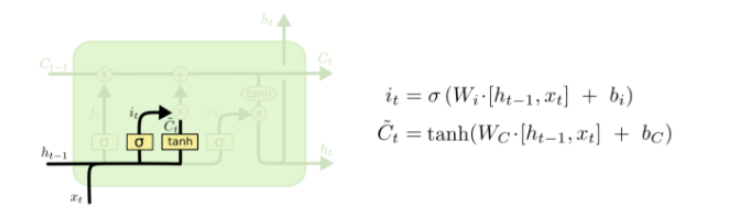
上一步的细胞状态 Ct-1已经被忘记了一部分,接下来本步应该把哪些信息新加到细胞状态中呢?这里又包含2层:一个tanh层用来产生更新值的候选项 Ct ,tanh的输出在[-1,1]上,说明细胞状态在某些维度上需要加强,在某些维度上需要减弱;还有一个sigmoid层(输入门层),它的输出值要乘到tanh层的输出上,起到一个缩放的作用,极端情况下sigmoid输出0说明相应维度上的细胞状态不需要更新。在那个预测下一个词的例子中,我们希望增加新的主语的性别到细胞状态中,来替代旧的需要忘记的主语。
第三层
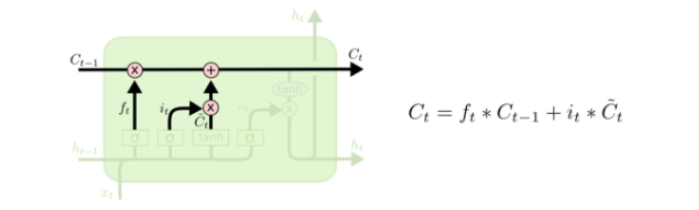
现在可以让旧的细胞状态 Ct-1 与 ft (f是forget忘记门的意思)相乘来丢弃一部分信息,然后再加个需要更新的部分 it*Ct (i是input输入门的意思),这就生成了新的细胞状态Ct
第四层
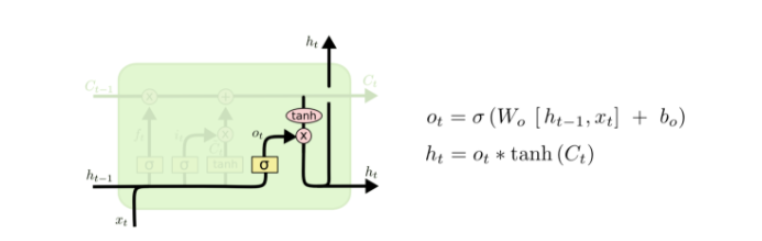
最后该决定输出什么了。输出值跟细胞状态有关,把 [公式] 输给一个tanh函数得到输出值的候选项。候选项中的哪些部分最终会被输出由一个sigmoid层来决定。在那个预测下一个词的例子中,如果细胞状态告诉我们当前代词是第三人称,那我们就可以预测下一词可能是一个第三人称的动词。
三、GRU
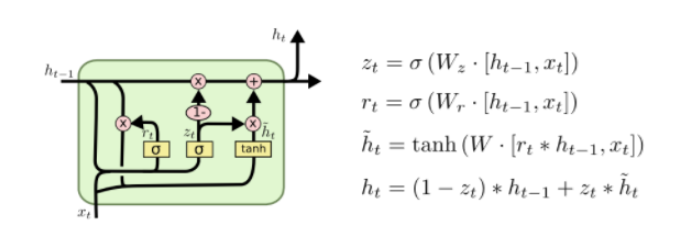
GRU(Gated Recurrent Unit)是LSTM最流行的一个变体,比LSTM模型要简单。
GRU 有两个有两个门,即一个重置门(reset gate)和一个更新门(update gate)。从直观上来说,重置门决定了如何将新的输入信息与前面的记忆相结合,更新门定义了前面记忆保存到当前时间步的量。如果我们将重置门设置为 1,更新门设置为 0,那么我们将再次获得标准 RNN 模型。使用门控机制学习长期依赖关系的基本思想和 LSTM 一致,但还是有一些关键区别:
- GRU 有两个门(重置门与更新门),而 LSTM 有三个门(输入门、遗忘门和输出门)。
- GRU 并不会控制并保留内部记忆(c_t),且没有 LSTM 中的输出门。
- LSTM 中的输入与遗忘门对应于 GRU 的更新门,重置门直接作用于前面的隐藏状态。
四、 LSTM和GRU区别
- 对memory 的控制
LSTM: 用output gate 控制,传输给下一个unit
GRU:直接传递给下一个unit,不做任何控制
- input gate 和reset gate 作用位置不同
LSTM: 计算new memory c(t)c(t)时 不对上一时刻的信息做任何控制,而是用forget gate 独立的实现这一点
GRU: 计算new memory h(t)h(t) 时利用reset gate 对上一时刻的信息 进行控制。
- 相似
最大的相似之处就是, 在从t 到 t-1 的更新时都引入了加法。
这个加法的好处在于能防止梯度弥散,因此LSTM和GRU都比一般的RNN效果更好。
参考
RNN、LSTM、GRU基础原理篇
RNN,LSTM,GRU
最后
以上就是清脆草莓最近收集整理的关于RNN、LSTM、GRU基础原理梳理前言一、传统RNN二、LSTM三、GRU四、 LSTM和GRU区别参考的全部内容,更多相关RNN、LSTM、GRU基础原理梳理前言一、传统RNN二、LSTM三、GRU四、内容请搜索靠谱客的其他文章。








发表评论 取消回复