一.摘要
本文中,我们介绍了序列标注上各种基于LSTM的模型,LSTM模型、双向LSTM模型、LSTM+CRF、BiLSTM+CRF。我们的工作是第一个在序列标注数据集上使用BiLSTM+CRF模型。BiLSTM-CRF模型通过双向LSTM有效地捕捉到了输入的过去和未来特征。它也可以通过CRF层使用到句子级的标注信息。BiLSTM-CRF在POS、分块、NER数据集上都取得了很好的效果。另外,与之前的工作相比,它更健壮,少依赖于词向量。
二.介绍
序列标注任务分为POS、分块、NER。大多数序列标注模型是线性统计模型,包括马尔科夫模型(HMM)、最大熵马尔科夫模型(MEMMs)、条件随机场(CRF)。最近在序列标注任务上也有出现基于卷积神经网络的模型。Conv-CRF模型在序列标注任务上也取得了不错的结果。
作者的贡献如下:
- 我们系统地比较了基于LSTM的各种模型在NLP标记数据集上的性能;
- 我们的工作在序列标注数据集上首次使用BiLSTM-CRF模型。这个模型可以捕捉到过去和未来的特征,通过CRF层也可以利用到句子级标签信息。在POS、分块、NER数据集上取得了很好地效果;
- 我们证明了BiLSTM-CRF模型是健壮的,与先前的观察结果相比,它对词向量的依赖性较小。
三、模型
本节将会介绍LSTM、BiLSTM、CRF、LSTM-CRF、BiLSTM-CRF模型。
3.1LSTM模型
在语言模型和语音识别任务上RNN模型都取得了不错的效果。RNN基于历史信息保存记忆,使得模型可以在长距离特征上预测当前输出。
下图表示了基本的RNN结构。输入层x,隐藏层h,输出层y。在NER中x表示输入特征,y表示输出标签。NER需要识别出人名、地名、机构名、其他实体、非实体。
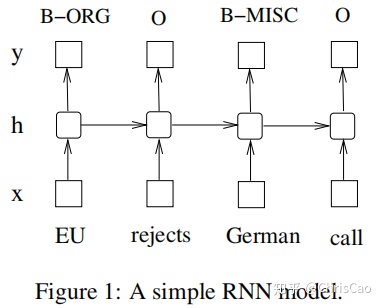
输入层表示时刻t的特征,可以是0-1编码的词特征、密集向量特征、或离散特征。输入层的维度与特征大小相同。输出层表示时刻t的标签概率分布,维度与标签大小相同。与前馈网络相比,RNN引入了先前隐藏状态和当前隐藏状态之间的连接,这个循环层旨在存储历史信息。隐藏层和输出层的计算公式如下:
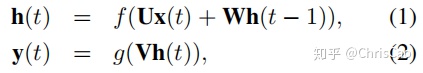
U,W,V是模型参数,f(z)和g(z)分别是sigmoid函数和softmax函数。
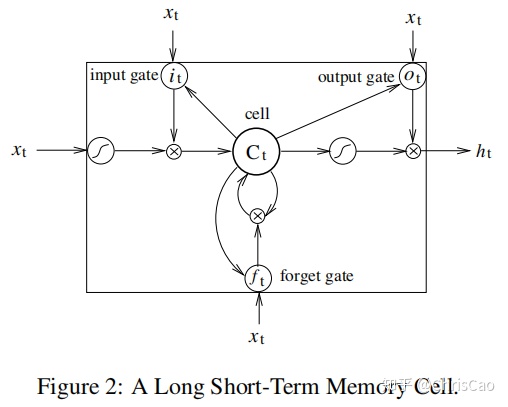
本文中,作者运用了LSTM网络,与RNN很相似,除了用专门构建的存储单元替换隐藏层的更新。因此,他们可能更善于发现和利用数据中的长程依赖性。一个LSTM的记忆神经元结构如下,不再详细介绍:

3.2双向LSTM模型
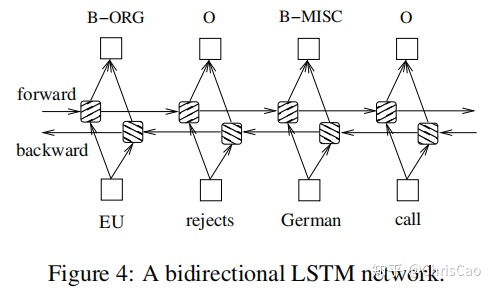
我们使用双向LSTM捕捉到当前时刻t的过去和未来的特征。通过反向传播来训练双向LSTM网络。
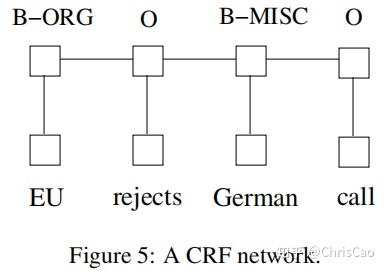
3.3CRF网络
在预测当前标签时,有两种不同的方法可以利用邻居标签信息。第一种是预测每个时间步的标签分布,然后使用类似波束的解码来找到最佳标签序列,最大熵分类器和最大熵马尔科夫模型的工作属于这一类。第二种是关注整个句子而不是单个位置,条件随机场属于这类。
实验表明,一般来说,CRF会得到更好的标记性能。
3.4LSTM-CRF网络
将LSTM和CRF结合在一起,可以捕捉到输入的过去特征和句子级的标签信息。CRF层有一个状态转换矩阵参数,通过CRF层,我们可以有效地使用过去和未来的标签信息来预测当前标签,这与双向LSTM有点类似。LSTM网络输出的状态分数为
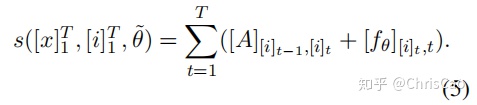
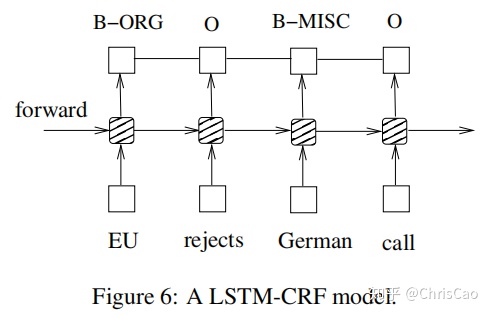
3.5BiLSTM-CRF网络
与LSTM-CRF网络类似,只是将LSTM换为BiLSTM,可以捕捉到过去和未来的特征,实验表明,额外的特征可以提高标注性能。
四.总结
在本文中,我们系统地比较了基于LSTM网络的序列标记模型的性能。 我们介绍了将BI-LSTM-CRF模型应用于NLP基准标记序列标记数据的第一项工作。 我们的模型可以在POS,分块和NER数据集上提供最先进的(或接近)准确性。 此外,与(Collobert et al。,2011)中的观察相比,我们的模型具有鲁棒性,并且对单词嵌入的依赖性较小。 无需借助词嵌入,即可达到准确率标记的准确性。
最后
以上就是甜甜嚓茶最近收集整理的关于lstm模型_用于序列标注的双向LSTM-CRF模型Summary的全部内容,更多相关lstm模型_用于序列标注内容请搜索靠谱客的其他文章。








发表评论 取消回复