第三节课的内容包括过拟合、欠拟合及其解决方案和梯度消失、梯度爆炸和循环神经网络进阶
一、过拟合、欠拟合及其解决方案
1.过拟合、欠拟合及相关概念
训练误差:模型在训练数据集上表现出的误差
泛化误差:模型在任意一个测试数据样本上表现出的误差,常通过测试集近似
验证集:预留一部分在训练数据集和测试数据集以外的数据集,用来进行模型选择
过拟合:训练误差远小于它在测试数据集上的误差
欠拟合:模型无法得到较低的训练误差
下图展现了模型复杂度与泛化误差和训练误差的关系,我们可以看到,训练误差会随着模型复杂度的提升而降低,而泛化误差会先降低之后升高产生过拟合的情况。
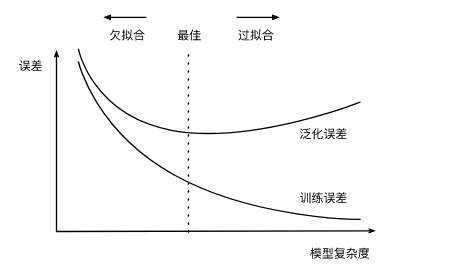
为此,我们应该尽可能选择泛化误差和训练误差都较低的模型,另外,我们希望训练集的数据尽可能多,对于数据集较少的情况,我们可以使用K折交叉验证。
在K折交叉验证中,我们把原始训练数据集分割成K个不重合的子数据集,然后我们做K次模型训练和验证。每一次,我们使用一个子数据集验证模型,并使用其他K-1个子数据集来训练模型。在这K次训练和验证中,每次用来验证模型的子数据集都不同。最后,我们对这K次训练误差和验证误差分别求平均。
2.权重衰减(L2正则化)
L2正则化在模型原损失函数基础上添加L2范数惩罚项,从而得到训练所需要最小化的函数。L2范数惩罚项指的是模型权重参数每个元素的平方和与一个正的常数的乘积。以线性回归中的线性回归损失函数为例
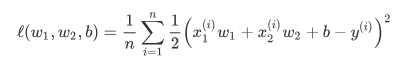
带有L2范数惩罚项的新损失函数为
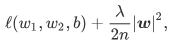
其中λ为超参数。当权重参数均为0时,惩罚项最小。当λ较大时,惩罚项在损失函数中的比重较大,这通常会使学到的权重参数的元素较接近0。当λ设为0时,惩罚项完全不起作用。L2正则化可以解决过拟合的问题,也是深度学习中常用的方法。
3.Dropout
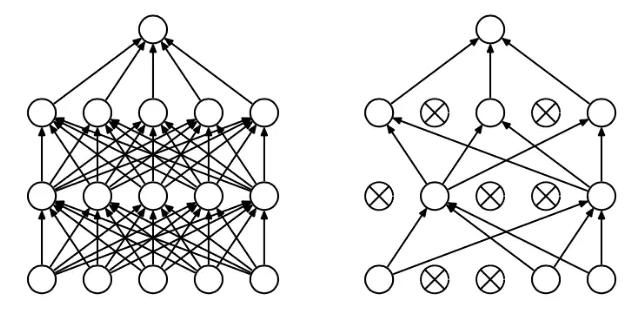
当对该隐藏层使用Dropout时,该层的隐藏单元将有一定概率被丢弃掉。如下图隐藏层的h2和h5两个单元被丢弃掉了。
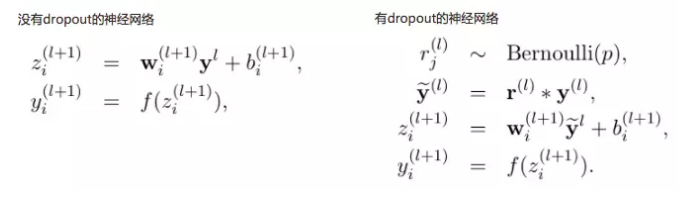
上面公式中Bernoulli函数,是为了以概率p,随机生成一个0、1的向量。
当模型使用了dropout layer,要注意的一点是训练的时候只有占比为 1-p 的隐藏层单元参与训练,那么在预测的时候,如果所有的隐藏层单元都需要参与进来,则得到的结果相比训练时平均要大 1/1-p ,为了避免这种情况,就需要测试的时候将输出结果乘以 1/1-p 使下一层的输入规模保持不变。
二、梯度消失和梯度爆炸
当神经网络的层数较多时,模型的数值稳定性容易变差。
以一个不含偏置的线性模型为例,可以看到,如果我们使用标准化初始w,那么各个层次的相乘都是0-1之间的小数,而激活函数f的导数也是0-1之间的数,其连乘后,结果会变的很小,导致梯度消失。若我们初始化的w是很大的数,w大到乘以激活函数的导数都大于1,那么连乘后,可能会导致求导的结果很大,形成梯度爆炸。
后面讲的三种环境因素理解的不是很好,简要列举一下。
协变量偏移:

个人理解是训练数据和测试数据分布不同导致的预测结果较差
标签偏移:

个人理解是训练数据较少导致有些标签不存在对应的输入数据
概念偏移:

标签本身的定义发生变化的情况,个人理解相同的输入对应输出的含义不同,例如机器翻译中单词的多个意义。
三、循环神经网络进阶
1.GRU
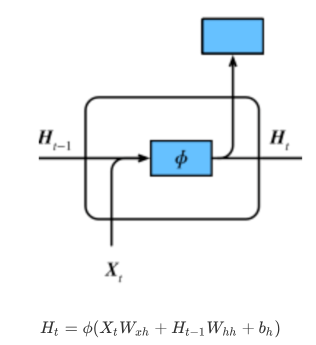
RNN存在的问题:易出现梯度消失或梯度爆炸,下图为RNN结构:
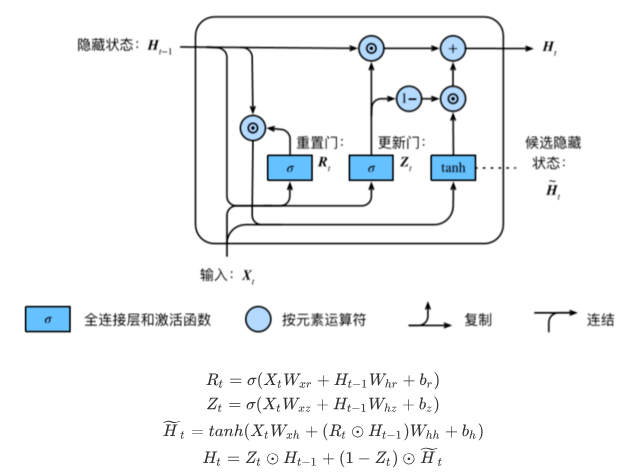
GRU单元包含重置门R和更新门Z两种结构。重置门有助于捕捉时间序列⾥短期的依赖关系;更新门有助于捕捉时间序列⾥⻓期的依赖关系。下图展现GRU单元的结构及计算方法。
导入包
import numpy as np
import torch
from torch import nn, optim
import torch.nn.functional as F
import sys
sys.path.append("../input/")
import d2l_jay9460 as d2l
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
(corpus_indices, char_to_idx, idx_to_char, vocab_size) = d2l.load_data_jay_lyrics()
初始化参数
num_inputs, num_hiddens, num_outputs = vocab_size, 256, vocab_size
print('will use', device)
def get_params():
def _one(shape):
ts = torch.tensor(np.random.normal(0, 0.01, size=shape), device=device, dtype=torch.float32) #正态分布
return torch.nn.Parameter(ts, requires_grad=True)
def _three():
return (_one((num_inputs, num_hiddens)),
_one((num_hiddens, num_hiddens)),
torch.nn.Parameter(torch.zeros(num_hiddens, device=device, dtype=torch.float32), requires_grad=True))
W_xz, W_hz, b_z = _three() # 更新门参数
W_xr, W_hr, b_r = _three() # 重置门参数
W_xh, W_hh, b_h = _three() # 候选隐藏状态参数
# 输出层参数
W_hq = _one((num_hiddens, num_outputs))
b_q = torch.nn.Parameter(torch.zeros(num_outputs, device=device, dtype=torch.float32), requires_grad=True)
return nn.ParameterList([W_xz, W_hz, b_z, W_xr, W_hr, b_r, W_xh, W_hh, b_h, W_hq, b_q])
def init_gru_state(batch_size, num_hiddens, device): #隐藏状态初始化
return (torch.zeros((batch_size, num_hiddens), device=device), )
GRU模型
def gru(inputs, state, params):
W_xz, W_hz, b_z, W_xr, W_hr, b_r, W_xh, W_hh, b_h, W_hq, b_q = params
H, = state
outputs = []
for X in inputs:
Z = torch.sigmoid(torch.matmul(X, W_xz) + torch.matmul(H, W_hz) + b_z)
R = torch.sigmoid(torch.matmul(X, W_xr) + torch.matmul(H, W_hr) + b_r)
H_tilda = torch.tanh(torch.matmul(X, W_xh) + R * torch.matmul(H, W_hh) + b_h)
H = Z * H + (1 - Z) * H_tilda
Y = torch.matmul(H, W_hq) + b_q
outputs.append(Y)
return outputs, (H,)
训练模型
num_epochs, num_steps, batch_size, lr, clipping_theta = 160, 35, 32, 1e2, 1e-2
pred_period, pred_len, prefixes = 40, 50, ['分开', '不分开']
d2l.train_and_predict_rnn(gru, get_params, init_gru_state, num_hiddens,
vocab_size, device, corpus_indices, idx_to_char,
char_to_idx, False, num_epochs, num_steps, lr,
clipping_theta, batch_size, pred_period, pred_len,
prefixes)
Pytorch简洁实现
num_hiddens=256
num_epochs, num_steps, batch_size, lr, clipping_theta = 160, 35, 32, 1e2, 1e-2
pred_period, pred_len, prefixes = 40, 50, ['分开', '不分开']
lr = 1e-2 # 注意调整学习率
gru_layer = nn.GRU(input_size=vocab_size, hidden_size=num_hiddens)
model = d2l.RNNModel(gru_layer, vocab_size).to(device)
d2l.train_and_predict_rnn_pytorch(model, num_hiddens, vocab_size, device,
corpus_indices, idx_to_char, char_to_idx,
num_epochs, num_steps, lr, clipping_theta,
batch_size, pred_period, pred_len, prefixes)
2.LSTM
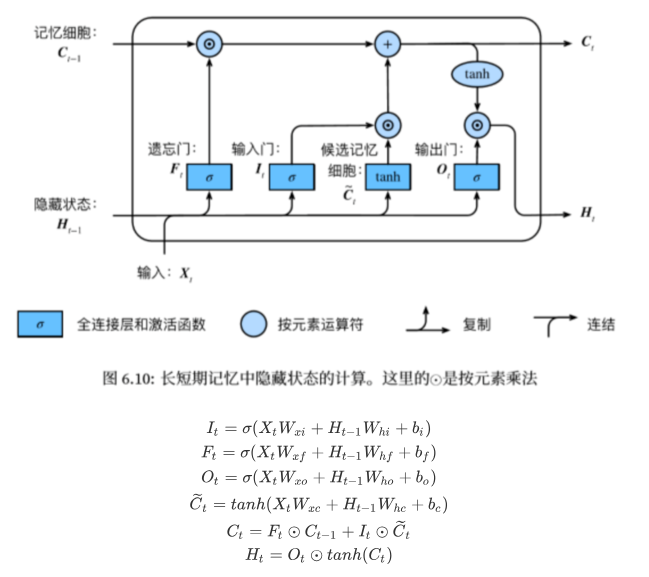
长短期记忆网络在GRU单元的基础上添加了遗忘门、输出门和记忆细胞的结构。与GRU相比,LSTM更加精准,但是比GRU耗时长,下图为LSTM结构及运算过程:
初始化参数
num_inputs, num_hiddens, num_outputs = vocab_size, 256, vocab_size
print('will use', device)
def get_params():
def _one(shape):
ts = torch.tensor(np.random.normal(0, 0.01, size=shape), device=device, dtype=torch.float32)
return torch.nn.Parameter(ts, requires_grad=True)
def _three():
return (_one((num_inputs, num_hiddens)),
_one((num_hiddens, num_hiddens)),
torch.nn.Parameter(torch.zeros(num_hiddens, device=device, dtype=torch.float32), requires_grad=True))
W_xi, W_hi, b_i = _three() # 输入门参数
W_xf, W_hf, b_f = _three() # 遗忘门参数
W_xo, W_ho, b_o = _three() # 输出门参数
W_xc, W_hc, b_c = _three() # 候选记忆细胞参数
# 输出层参数
W_hq = _one((num_hiddens, num_outputs))
b_q = torch.nn.Parameter(torch.zeros(num_outputs, device=device, dtype=torch.float32), requires_grad=True)
return nn.ParameterList([W_xi, W_hi, b_i, W_xf, W_hf, b_f, W_xo, W_ho, b_o, W_xc, W_hc, b_c, W_hq, b_q])
def init_lstm_state(batch_size, num_hiddens, device):
return (torch.zeros((batch_size, num_hiddens), device=device),
torch.zeros((batch_size, num_hiddens), device=device))
LSTM模型
def lstm(inputs, state, params):
[W_xi, W_hi, b_i, W_xf, W_hf, b_f, W_xo, W_ho, b_o, W_xc, W_hc, b_c, W_hq, b_q] = params
(H, C) = state
outputs = []
for X in inputs:
I = torch.sigmoid(torch.matmul(X, W_xi) + torch.matmul(H, W_hi) + b_i)
F = torch.sigmoid(torch.matmul(X, W_xf) + torch.matmul(H, W_hf) + b_f)
O = torch.sigmoid(torch.matmul(X, W_xo) + torch.matmul(H, W_ho) + b_o)
C_tilda = torch.tanh(torch.matmul(X, W_xc) + torch.matmul(H, W_hc) + b_c)
C = F * C + I * C_tilda
H = O * C.tanh()
Y = torch.matmul(H, W_hq) + b_q
outputs.append(Y)
return outputs, (H, C)
训练模型
num_epochs, num_steps, batch_size, lr, clipping_theta = 160, 35, 32, 1e2, 1e-2
pred_period, pred_len, prefixes = 40, 50, ['分开', '不分开']
d2l.train_and_predict_rnn(lstm, get_params, init_lstm_state, num_hiddens,
vocab_size, device, corpus_indices, idx_to_char,
char_to_idx, False, num_epochs, num_steps, lr,
clipping_theta, batch_size, pred_period, pred_len,
prefixes)
Pytorch简洁实现
num_hiddens=256
num_epochs, num_steps, batch_size, lr, clipping_theta = 160, 35, 32, 1e2, 1e-2
pred_period, pred_len, prefixes = 40, 50, ['分开', '不分开']
lr = 1e-2 # 注意调整学习率
lstm_layer = nn.LSTM(input_size=vocab_size, hidden_size=num_hiddens)
model = d2l.RNNModel(lstm_layer, vocab_size)
d2l.train_and_predict_rnn_pytorch(model, num_hiddens, vocab_size, device,
corpus_indices, idx_to_char, char_to_idx,
num_epochs, num_steps, lr, clipping_theta,
batch_size, pred_period, pred_len, prefixes)
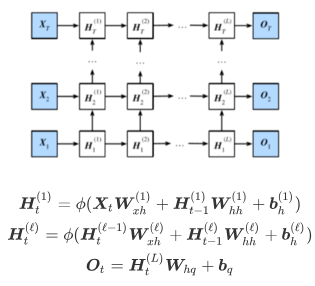
3.深度循环神经网络
深度循环神经网络在循环神经网络的基础上增加了多层结构,相比于LSTM的代码实现,只需将参数num_layers设置为希望的层数即可,结构如下图所示:
代码实现
num_hiddens=256
num_epochs, num_steps, batch_size, lr, clipping_theta = 160, 35, 32, 1e2, 1e-2
pred_period, pred_len, prefixes = 40, 50, ['分开', '不分开']
lr = 1e-2 # 注意调整学习率
gru_layer = nn.LSTM(input_size=vocab_size, hidden_size=num_hiddens,num_layers=2) # 修改参数num_layers即可
model = d2l.RNNModel(gru_layer, vocab_size).to(device)
d2l.train_and_predict_rnn_pytorch(model, num_hiddens, vocab_size, device,
corpus_indices, idx_to_char, char_to_idx,
num_epochs, num_steps, lr, clipping_theta,
batch_size, pred_period, pred_len, prefixes)
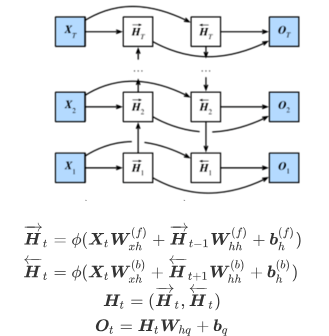
4.双向循环神经网络
双向循环神经网络在NLP中使用率更高,代码实现上将bidirectional参数设置为True,网络结构如下:
代码实现
num_hiddens=128
num_epochs, num_steps, batch_size, lr, clipping_theta = 160, 35, 32, 1e-2, 1e-2
pred_period, pred_len, prefixes = 40, 50, ['分开', '不分开']
lr = 1e-2 # 注意调整学习率
gru_layer = nn.GRU(input_size=vocab_size, hidden_size=num_hiddens,bidirectional=True)
model = d2l.RNNModel(gru_layer, vocab_size).to(device)
d2l.train_and_predict_rnn_pytorch(model, num_hiddens, vocab_size, device,
corpus_indices, idx_to_char, char_to_idx,
num_epochs, num_steps, lr, clipping_theta,
batch_size, pred_period, pred_len, prefixes)
注:
本博客所有内容均参考伯禹学习平台动手学深度学习课程
Dropout部分参考的原文
https://blog.csdn.net/fu6543210/article/details/84450890
最后
以上就是积极酒窝最近收集整理的关于动手学深度学习Pytorch Task03一、过拟合、欠拟合及其解决方案二、梯度消失和梯度爆炸三、循环神经网络进阶的全部内容,更多相关动手学深度学习Pytorch内容请搜索靠谱客的其他文章。








发表评论 取消回复