在数据横行霸道的时代, 不看你会多少软件。 能否在数据分析的行业站稳脚跟, 还要看你的思维, 对于案例的解题思维是你能否简单高效地解决问题的关键。
我是纯小白, 接触SAS只有五天, 快比赛了, 试试去年的水, 代码都在, 但是不会用宏, 所以可能有点low, 欢迎批评指正
一起学习一起交流!!
第一题
题目:
1) 使用Data步计来计算a600605这支股票在1995-1998年的市场收益,即该股票的月收益率(个股月收益率=[(本月收盘价-上月收盘价)/上月收盘价]×100%),过程中不要使用dif和lag函数。其中date的格式设置为‘1995-01’的形式,并删除1995年1月的观测数据。
2) 编写graph,绘制a600605这支股票的收益率曲线,横坐标标签改为“日期”,纵坐标标签改为“月收益率”。
思路:
第一问其实是没做出来, 只能用dif和lag计算了, 我自己写算式的时候计算不出来, 因为我对循环的语句还理解的不太好, 所以就调用了现成的函数, 一样的效果就是不按要求来喽。
第二问他说编写graph, 找了半天graph过程, 后来理解为就像优化的OR板块一样, 其实是作图板块, 里面有各种过程,这个比较简单, 就是考你会不会画图。
总的来说第一题很基础, 考了data步和循环等方面的应用。
代码:
/*libname sas2016 'C:UsersASUSDesktopsas往年赛题sasSAS大赛历年考题sas大赛2016';*/
data work.a600605_1;
set test.a600605;
keep Oppr/*开盘价*/ Clpr/*收盘价*/ date;
run;
proc timeseries data=work.a600605_1;
id date interval=month
accumulate=last
start="03Jan1995"d end="08Jan2001"d;
var Clpr;
run;
data work.acc;
set work.Data4;
keep Clpr date clpr_r;
clpr_r=dif(Clpr)/lag(Clpr);
label clpr_r="月收益率";
if clpr_r=" " then delete;
run;
axis1 label=("日期");
axis2 label=("月收益率");
symbol value=dot cv=red
interpol=join ci=blue;
proc gplot data=work.Acc;
plot clpr_r*date/haxis=axis1 vaxis=axis2;
run;
quit;
goptions reset=all;
第二题
问题:
1) 将TEST库下的credit_old数据集复制到work逻辑库下,并重命名为credit_new。(5分)
2) 使用数据字典读取credit_new数据集下所有解释变量中的字符变量的个数和名称。(10分)
3) 编写宏,为每一个字符变量重新编码,以“变量名_cd”的命名方式保存新的编码,并添加到原credit_new数据集的后面,效果就是变成数字就好(15分)
思路:
第二问意思是这有个字符变量“var”, 问你有什么,你说有“v”“a”“r”,人家再问你几个v几个a几个r,你去统计一下。
第三问是把上一问的字符“v”“a”“r”,变成比如123数字的, 本来想用input函数来做, 但是出不来效果, 就换了个法子。
代码:
/**/
%macro FreqBar(ds, varname);
proc freq data=&ds;
tables &varname / plots(only)=freqplot;
run;
%mend;
%FreqBar(credit_new, Branch)
proc means data=work.credit_new n nmiss min mean median max std;
run;
proc tabulate data=work.credit_new;
class Branch Res;
table Branch res;
run;
/*branch*/
data work.data2;
set work.credit_new;
branch_cd=substr(branch, length(branch), 1);
run;
/*res*/
data work.data1;
set work.credit_new;
if res='U' then res=1;
if res='S' then res=2;
if res='R' then res=3;
run;
/*合起来*/
data work.data3;
set work.credit_new;
branch_cd=substr(branch, length(branch), 1);
if res='U' then res=1;
if res='S' then res=2;
if res='R' then res=3;
rename res=res_cd;
run;
第三题
问题:
所有的数据除了weight之外,全部是等级数据,分值越高意味着评价越正面。以weight为权数,根据数据集当中的变量,结合宏语言,编写宏程序完成下面的问题。
1)对于各个变量进行描述性分析
2)对四个变量,进行两两的列联表分析,生成的列联表保存,进行分卡方检验和其他分类数据相关系数的计算。
4)以年龄为条件,同其他三个变量中的任意两个,进行三维列联表分析,进行整体cmh检验,并将生成的列联表保存。
5)(可选)将4中生成的列联表,同样计算每个格子频数占总频数的比例,检验任意两个格子中的比例差异是否显著。
代码:
proc means data=test.Base mean median mode cv std var range qrange maxdec=2;
title "总体描述性统计";
var Q8 Q22 Q3F age10;
run;
proc freq data=test.base;
table Q8*Q22 Q8*Q3F Q8*age10 Q22*Q3F Q22*age10 Q3F*age10/chisq measures cmh;
title "卡方检验及其相关系数";
weight weight;
run;
proc freq data=test.base;
table Q8*Q22 Q8*Q3F Q8*age10 Q22*Q3F Q22*age10 Q3F*age10/expected cumcol;
title "每个格子计算频数占总频数的比例";
weight weight;
run;
proc freq data=test.base;
title"三维列联图";
table age10*Q8*Q22 age10*Q8*Q3F age10*Q22*Q3F/cmh;
weight weight;
run;
第四题
4、(25分)数据集coal中保存的是1980-2010年我国煤炭消费量和1980-2015年gdp的相关数据,根据数据的相关结构,结合宏语言,建立宏程序,完成下列题目。
1)利用ARIMA模型预测未来我国煤炭消费,要完成数据探索、模型识别、参数估计检验、模型优化的全部过程,最好要将建模过程写成宏程序调用。
2)利用指数平滑模型,对于我国煤炭消费量进行预测,同样完成模型识别、参数估计、优化,同时将参数估计结果保存,最好将建模过程写成宏程序调用。
3)以我国gdp为说明变量,煤炭消费量为因变量,建立带自回归误差的回归模型(autoreg过程),对煤炭消费量进行预测。尝试不同的滞后阶数,建立模型,降低自相关程度,最后选择最优模型。
时序图:
原数据的代码:
proc arima data=test.coal;
identify var=coal_china nlag=12;
where year>="1980"d;
run;
quit;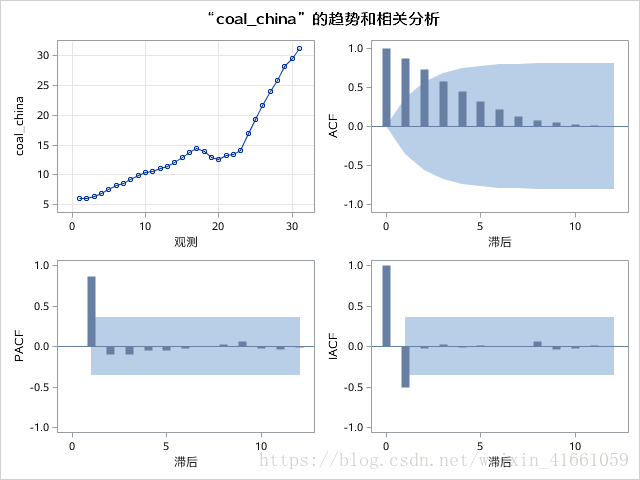
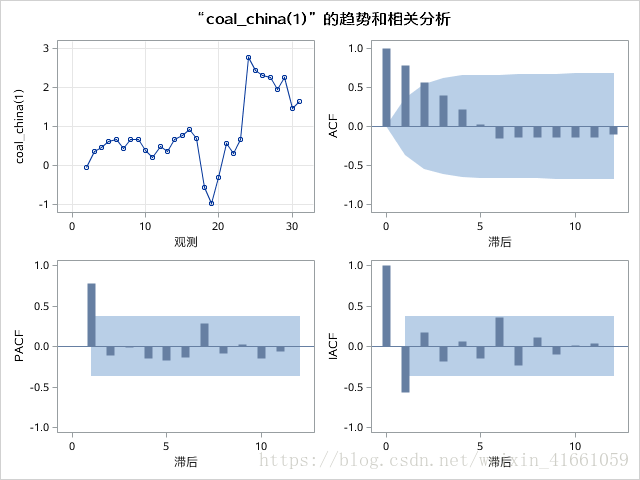
一阶差分代码:
proc arima data=test.coal;
identify var=coal_china(1) nlag=12;
where year>="1980"d;
run;
quit;
二阶差分代码:
proc arima data=test.coal;
identify var=coal_china(1,1) nlag=12;
where year>="1980"d;
run;
quit;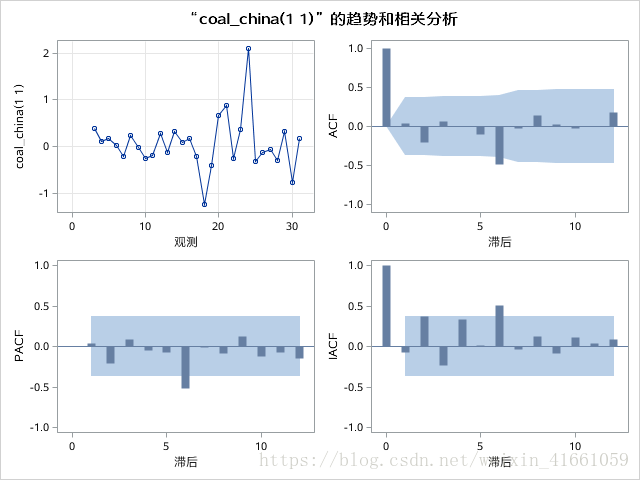
虽然看图二阶要更平稳,但是看P值, 二阶拒绝原假设了, 也就是说不是平稳序列,所以一阶差分就够了。
##
#####模型识别
/*模型识别*/
proc arima data=test.coal;
identify var=coal_china(1) nlag=6
esacf scan minic;
run;
可以看出scan、 esacf、 minic三个方法选择的模型, 挑出来scan和esacf共同的模型和minic选的BIC最小的模型。
##
#####参数估计检验
/*参数估计检验*/
proc arima data=test.coal;
identify var=coal_china(1) nlag=6;
eq1:estimate p=1 q=0 ml;
run;
把识别的模型pq值写进来, 用最大似然法估计, 得到参数估计值和相应模型的拟合优度报表。
##
#####预测
/*预测*/
proc arima data=test.coal;
identify var=coal_china(1) nlag=6;
eq1:estimate p=1 q=0 ml;
forecast lead=2;
run;
`lead`是预测后面几个值,直接预测就行,简单一点。
##
#####模型优化
/*模型优化,下面能找出异常值, 但是不会创建新变量*/
proc arima data=test.coal;
identify var=coal_china(1) nlag=6 noprint;
eq1:estimate p=1 q=0 ml;
outlier type=(ao ls tc(5)) maxnum=9 id=year;
run;
用`outlier`啊, `type`是方法, `maxnum`是最多能有几个异常值, `id`是你查谁有没有异常值的。
##
题目还有二三问,这边直接上代码吧:
/*第二问*/
proc forecast data=test.coal
out=work.demandARfor
outall
outest=work.paramerters
method=expo
trend=2
lead=2;
var coal_china;
id year;
run;
/*第三问*/
proc autoreg data=Test.coal;
model coal_china=GDP_China_real /nlag=12 backstep;
output out=Test.autoreg UCL=U95 LCL=L95 Predicted=Forecast;
run;喜欢的朋友点个赞哟, 支持原创拜托啦~
这是作者的第一篇CSDN博客, 纪念一下
原来右边有个markdown阿, 感谢之前比赛认识的大佬~

最后
以上就是狂野火车最近收集整理的关于关于2016全国高校SAS大赛初赛的解题想法的全部内容,更多相关关于2016全国高校SAS大赛初赛内容请搜索靠谱客的其他文章。








发表评论 取消回复