写在前面:本篇文章集中介绍了前馈神经网络模型、卷积神经网络模型、递归神经网络模型在自然语言处理领域的应用。对于模型本身,在《深度学习综述》一文中,已经有了一个比较细致和全面的介绍,这里将不做过多的介绍。
1 前馈神经网络在自然语言领域中的应用
这里要介绍的任务是一个分类问题,也可以认为是一个序列标注问题。自然语言处理中有一个很重要的基本问题,就是分词和词性标注问题。在处理分词问题,一个常见的处理方法是将单词标注为BIO类型。 BIO标注是将每个元素标注为“B-X”、“I-X”或者“O”。其中,“B-X”表示此元素所在的片段属于X类型并且此元素在此片段的开头,“I-X”表示此元素所在的片段属于X类型并且此元素在此片段的中间位置,“O”表示不属于任何类型。
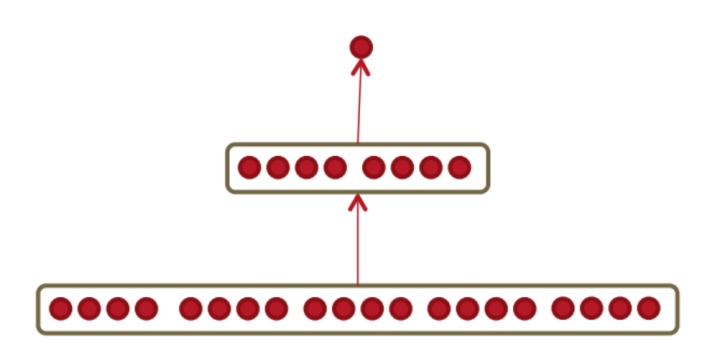
这里采用的前馈神经网络模型结构如下:
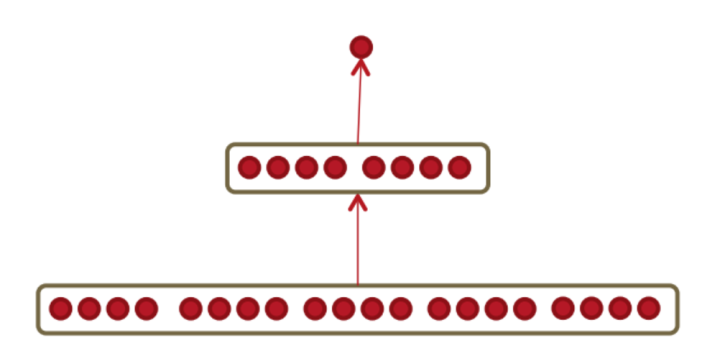
前馈神经网络模型的输入是窗口大小为
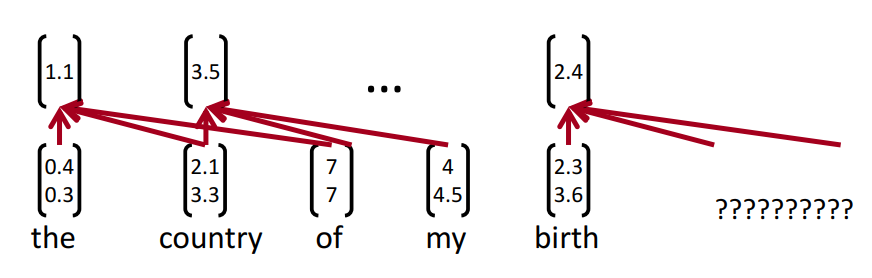
经过处理后的数据形式如下:
[('Sao', 'Paulo', '(', 'Brasil', ')', ',', '23', 'may', '(', 'EFECOM', ')', '.'), ('B-LOC', 'I-LOC', 'O', 'B-LOC', 'O', 'O', 'O', 'O', 'O', 'B-ORG', 'O', 'O')]经过padding操作后的窗口训练集举例:
['<DUMMY>', '<DUMMY>', 'Sao', 'Paulo', '('], 'B-LOC']其经过神经网络得到一个类别
2 卷积神经网络在自然语言处理领域中的应用
下图是一个单层CNN实例,卷积操作的数学公式表示如下:
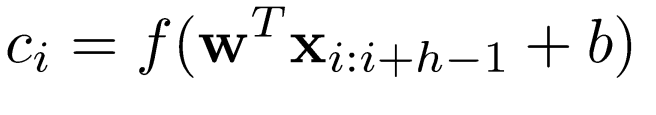
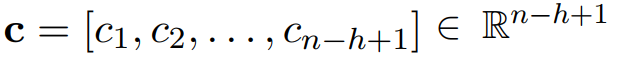
经过上式的卷积操作得到了feature map,对
通过一个实例介绍卷积神经网络是如何应用在自然语言处理领域的。在如下图的模型中,首先,将每个单词编码为一个5维的词向量,该句子被表示为了一个7*5的矩阵。接着,使用3个大小分别为2*5、3*5、4*5的卷积滤波器(每组各两个,即通道数out_channels为2)进行卷积操作,经过激活函数得到尺寸分别为6、4、4的特征向量,对得到的特征向量进行池化操作并合并每一组特征向量。最后对池化操作得到的向量组合作为softmax层的输入进行分类处理。
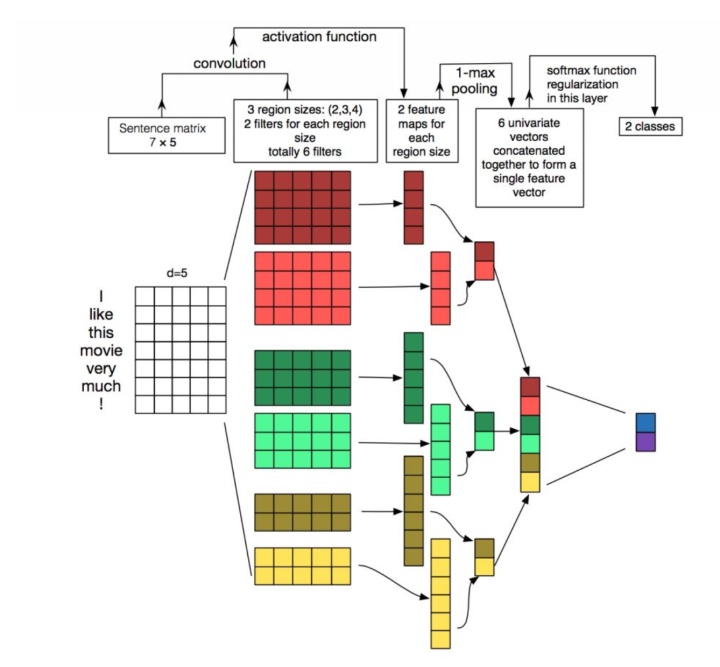
卷积实现:
kernel_size = (2,3,4)
kernel_dim = 2
self.convs = nn.ModuleList([nn.Conv2d(in_channels=1, out_channels=kernel_dim, kernel_size = (K, embedding_dim)) for K in kernel_sizes])Conv2d的参数解释:in_channels表示输入层的深度,这里是1。此外对于图像来说,黑白图像的in_channels为1,而彩色图像的in_channels为3(RGB三通道))。out_channels表示输出的通道数。
#注:Github中的卷积神经网络模型结构和该例子的模型并不一致。
此外,介绍一个字符级的卷积神经网络模型。模型架构如下图所示:
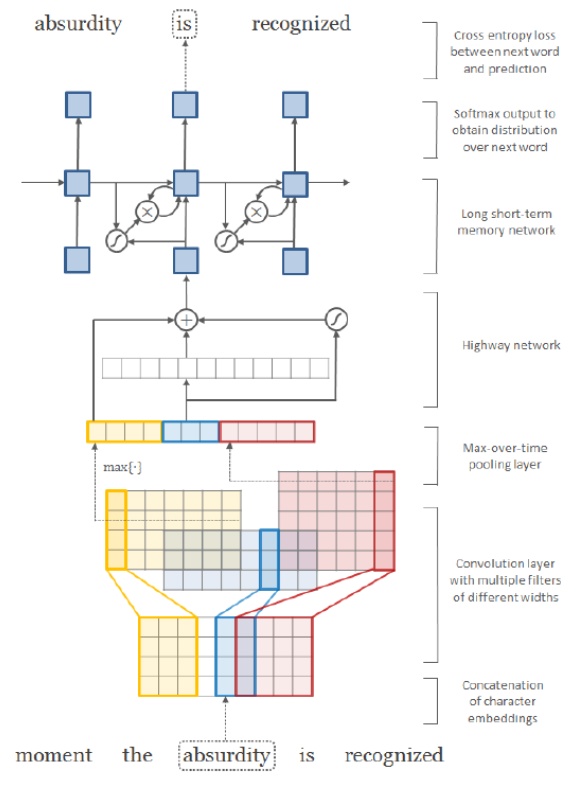
在该模型中,Highway network是一个新的概念,其旨在减少深层网络出现的梯度消失问题。其数学公式的描述如下:可以看出,输出
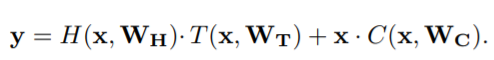
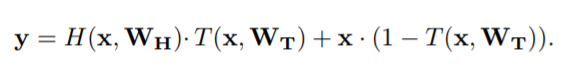
3 循环神经网络在自然语言处理领域中的应用
在介绍RNN模型之前,谈一谈语言模型的类型。Bi-RNN是一种考虑了全文信息的语言模型,前面谈到的Skip-Gram和CBOW属于基于窗口上下文的语言模型。n-gram模型和GloVe模型则属于基于计数的语言模型。
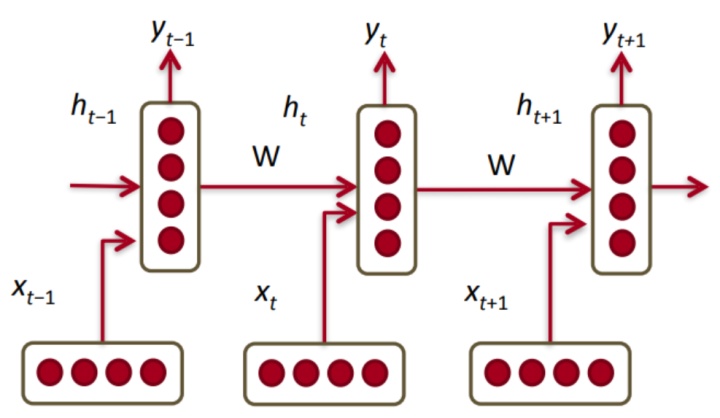
与传统的翻译模型不同,传统的翻译模型只考虑先前单词的有限窗口来调节语言模型,而递归神经网络(RNN)能够在语料库中的所有先前单词上调节模型。上图介绍了RNN架构,其中每个垂直矩形框是时间步t的隐藏层。 每个这样的层保持多个神经元,每个神经元对其输入执行线性矩阵运算,然后进行非线性运算。 运算过程如下式所示:
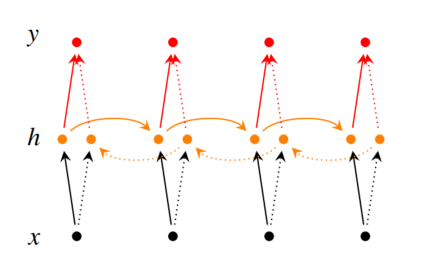
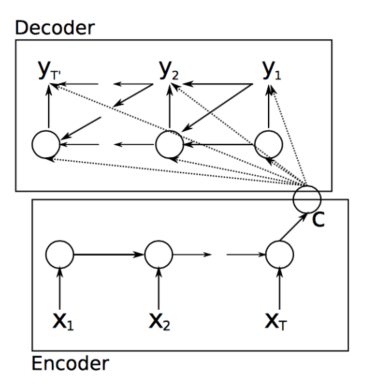
下图展示了一个双向的RNN模型:
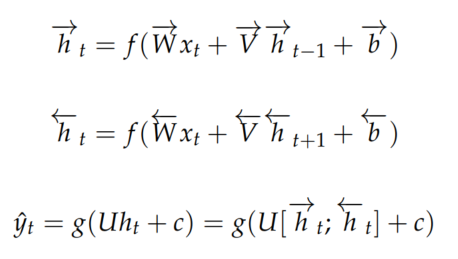
下图展示了RNN翻译模型,其中前三个隐含层单元属于源语言模型编码器,最后两个属于目标语言模型解码器。在这里,德语短语Echt dicke Kiste被翻译成Awesome sauce。 前三个隐藏层时间步骤将德语单词编码为一些语言单词特
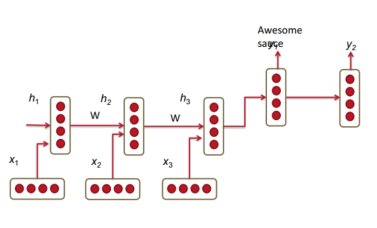
下式展示了上述模型的数学原理,第一个式子表示编码范围的关系,后两个式子表示解码范围的关系。
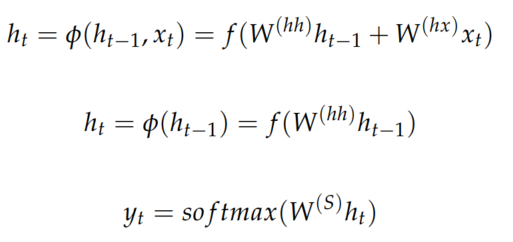
事实上,只是用上述的模型很难达到一个令人满意的结果,下面给出一些扩展模型的建议:
I)为编码器和解码器训练不同的RNN权重参数。
II)考虑下面的模型:
III)增加RNN模型的深度,这意味着语料库应该会很大。
IV)使用双向的RNN提高预测的精度。
V)给定的德语单词序列A、B、C,预测英语序列X、Y。使用C、B、A的序列作为训练集的输入。这是因为A更可能被转换为X.因此,考虑到前面讨论的消失梯度问题,反转输入词的顺序可以帮助降低生成输出短语的错误率。
值得注意的是,.对于RNN而言,相同的权重应用于输入的每个时间步。此外RNN模型存在以下问题:
- 计算很慢 ,因为它是顺序的,所以无法并行化。
- 在实践中,由于诸如消失和爆炸的梯度等问题,很难从许多步骤中获取信息。
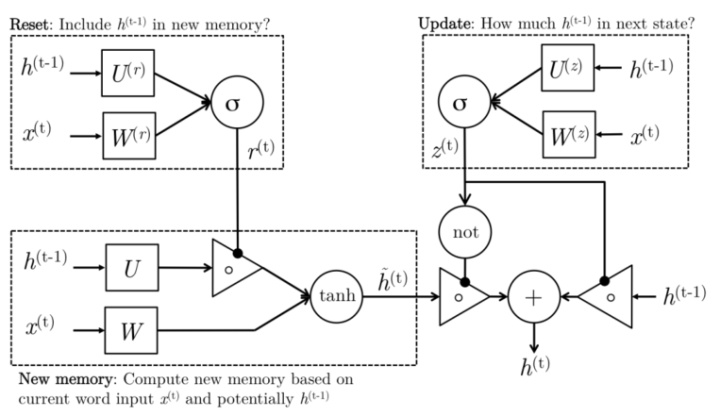
尽管RNN理论上可以捕获长期依赖性,但实际上很难进行训练。 门控循环单元的设计具有更持久的内存,从而使RNN更容易捕获长期依赖。下面介绍 Gated Recurrent Units的结构,LSTM前面已有详细介绍,这里就不再赘述。在Gated Recurrent Units结构中,Reset Gate负责确定
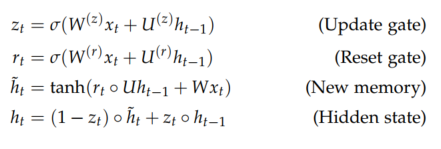
分类,卷积,循环神经网络完整版实现代码:
zhangtao-seu/cs224ngithub.com
最后
以上就是犹豫白羊最近收集整理的关于rnn神经网络模型_常见神经网络模型在自然语言处理领域中的应用的全部内容,更多相关rnn神经网络模型_常见神经网络模型在自然语言处理领域中内容请搜索靠谱客的其他文章。








发表评论 取消回复