一、引言
随机森林能够用来获取数据的主要特征,进行分类、回归任务。某项目要求对恶意流量检测中的数据流特征重要性进行排序,选择前几的特征序列集合进行学习。
二、随机森林简介
随机森林是一种功能强大且用途广泛的监督机器学习算法,它生长并组合多个决策树以创建"森林"。它可用于R和Python中的分类和回归问题。[1]
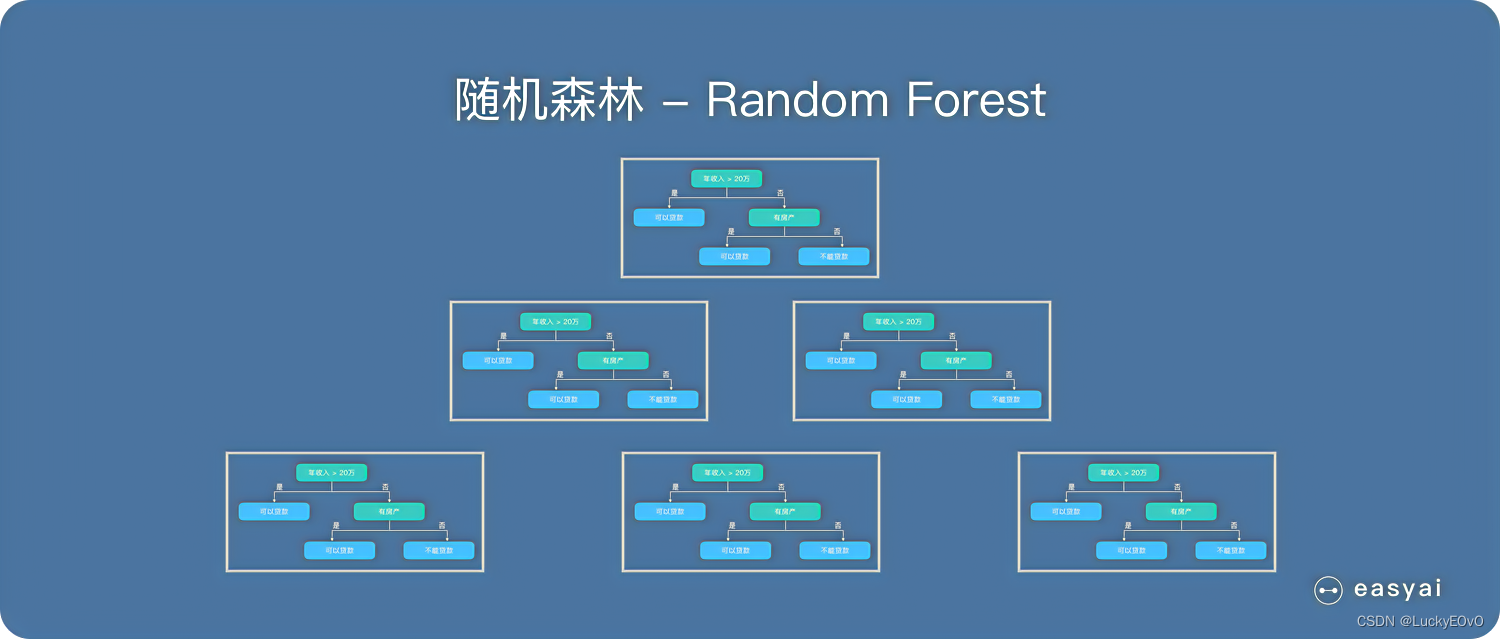
三、特征重要性评估
现实情况下,一个数据集中往往有成百上前个特征,如何在其中选择比结果影响最大的那几个特征,以此来缩减建立模型时的特征数是我们比较关心的问题。这样的方法其实很多,比如主成分分析,lasso等等。不过,这里我们要介绍的是用随机森林来对进行特征筛选。
用随机森林进行特征重要性评估的思想其实很简单,说白了就是看看每个特征在随机森林中的每颗树上做了多大的贡献,然后取个平均值,最后比较特征之间的贡献大小。[2]
四、具体实现
1.读取数据集(数据集来自CIC-IDS2018)
excel1=r'./Friday-WorkingHours-Afternoon-DDos.pcap_ISCX.csv'
frame1=pd.read_csv(excel1)
2.划分训练子集和测试子集
frame1.columns = ['Destination Port', 'Flow Duration', 'Total Fwd Packets', 'Total Backward Packets', 'Total Length of Fwd Packets',
'Total Length of Bwd Packets', 'Flow IAT Mean', 'Flow IAT Std', 'Flow IAT Max', 'Flow IAT Min']//数据流量标签
feat_labels = frame1.columns[:]
X, y = frame1.iloc[:,1:].values,frame1.iloc[:,0].values
test_size = 0.3,random_state = 0
X_train, X_test, y_train, y_test = train_test_split(X, y,
test_size=test_size,
random_state=random_state)
3.构建随机森林分类器
forest = RandomForestClassifier(n_estimators=100,
max_depth=5,
min_samples_leaf=10,
random_state=1)
(1)n_estimators参数代表森林中决策树的数量,默认为100,这个参数对随机森林模型的精确性影响是单调的,n_estimators越大,模型的效果往往越好。但是相应的,任何模型都有决策边界,n_estimators达到一定的程度之后,随机森林的精确性往往不在上升或开始波动,并且,n_estimators越大,需要的计算量和内存也越大,训练的时间也会越来越长。在测试时设置为500会直接把32G的内存占满后崩溃,一般个人的机器100~300可能比较合适。
(2)max_depth:树的最大深度。如果为None,则将节点展开,直到所有叶子都是纯净的(只有一个类),或者直到所有叶子都包含少于min_samples_split个样本。默认是None。常用的可以取值10-100之间。
(3)叶子节点最少样本数min_samples_leaf: 这个值限制了叶子节点最少的样本数,如果某叶子节点数目小于样本数,则会和兄弟节点一起被剪枝。 默认是1,可以输入最少的样本数的整数,或者最少样本数占样本总数的百分比。如果样本量不大,不需要管这个值。如果样本量数量级非常大,则推荐增大这个值。
(4)random_state此参数让结果容易复现。 一个确定的随机值将会产生相同的结果,将不同的随机状态的最优参数模型集成,有时候这种方法比单独的随机状态更好。
4.训练模型打印结果
forest.fit(X_train, y_train)
importances = forest.feature_importances_
print(importances)
indices = np.argsort(importances)[::-1]
for f in range(X_train.shape[1]):
print("%2d) %-*s %f" % (f + 1, 30, feat_labels[indices[f]], importances[indices[f]]))
1) Total Backward Packets 0.291891
2) Flow Duration 0.273377
3) Total Length of Fwd Packets 0.176061
4) Flow IAT Mean 0.106493
5) Total Fwd Packets 0.072531
6) Destination Port 0.038950
7) Flow IAT Std 0.025629
8) Flow IAT Max 0.008155
9) Total Length of Bwd Packets 0.006914
参考文献
[1] 随机森林random forest及python实现
[2]利用随机森林对特征重要性进行评估
最后
以上就是忧心豌豆最近收集整理的关于Python简单实现Random Forest随机森林算法笔记的全部内容,更多相关Python简单实现Random内容请搜索靠谱客的其他文章。








发表评论 取消回复