1 前言
在上一篇文章最前沿:机器人学习Robot Learning的发展 - 知乎专栏 中,我们介绍了机器人学习Robot Learning这个方向的发展趋势,并介绍了部分基于DRL的方法,那么在本文,我们将继续介绍一下最近发展起来的机器人学习的一个重要分支------模仿学习Imitation Learning。通过深度增强学习Deep Reinforcement Learning,我们可以让机器人实现从0开始学习一个任务,但是我们人类学习新东西有一个重要的方法就模仿学习,通过观察别人的动作从而完成学习。因此,模仿学习Imitation Learning就是这样一个应运而生的方向:希望机器人也能够通过观察模仿来实现学习。
最近Pieter Abbeel在MIT的Talk放出了ppt,非常的前沿,介绍了他们前几天才发出来的一堆工作,甚至包含了还未发出的工作(One Shot Visual Imitation Learning),可以说Pieter Abbeel团队自己挖坑自己填的能力实在是太强了。与此同时,DeepMind也不是吃素的,也是在这几天发布了多篇和Imitation Learning相关的工作。
然后大家也看到了,模仿学习的终极目标就是One Shot Imitation Learning,能够让机器人仅需要少量的示范就能够学习。做到这一步就真的太强了。因此非常期待One Shot Visual Imitation Learning这篇paper。为了实现one shot,那么必然要结合Few Shot Learning少样本学习这个方法,而这个方向目前竞争最火热的就是学会学习Meta Learning/Learning to Learn (事实上One Shot Visual Imitation Learning也是直接结合Meta Learning来做)。 关于学会学习,我们在 最前沿:让AI拥有核心价值观从而实现快速学习 - 知乎专栏 让我们谈谈机器人革命 - 知乎专栏 这两篇文章中也做了一定的介绍,在之后我们也会再专门写一篇文章介绍目前学会学习各种百花齐放的方法。
最后,不管是Deep Reinforcement Learning for Robotics,还是Imitation Learning,Meta Learning,都可以说是目前深度学习最最最前沿的研究方向了,这些方向的研究将直接影响未来必将到来的机器人革命。所以也很想知道在知乎有多少知友也在做这一方面的研究,如果有知友主要精力也是在研究DeepMind和OpenAI在这一方面的Paper,并且也在做相关的研究,欢迎在专栏下留言。然后,对于同在Deep Learning的知友,也欢迎在专栏下留言,说说你对这个方向的看法。
2 相关Papers
[1] Model-Free Imitation Learning with Policy Optimization, OpenAI, 2016
[2] Generative Adversarial Imitation Learning, OpenAI, 2016
[3] One-Shot Imitation Learning, OpenAI, 2017
[4] Third-Person Imitation Learning, OpenAI, 2017
[5] Learning human behaviors from motion capture by adversarial imitation, DeepMind, 2017
[6] Robust Imitation of Diverse Behaviors, DeepMind, 2017
[7] Unsupervised Perceptual Rewards for Imitation Learning, Google Brain, 2017
[8] Time-Contrastive Networks: Self-Supervised Learning from Multi-View Observation, Google Brain, 2017
[9] Imitation from Observation/ Learning to Imitate Behaviors from Raw Video via Context Translation, OpenAI, 2017
[10] One Shot Visual Imitation Learning (等待发布), OpenAI, 2017
一些比较古老的文章我们就不管了,搞懂上面这十篇文章基本上就搞明白现在Imitation Learning到底搞到什么程度了。从上面我们也可以看出,Imitation Learning主要还是由OpenAI做的贡献,DeepMind和Google Brain各自贡献了部分(其实Google Brain也是由Sergey Levine领导)所以其实也很显然,如果三个世界上最顶级的人工智能研究机构都在研究Imitation Learning,那么说明Imitation Learning真的很重要。
OK,下面我们逐一简要分析一下每一篇Paper的核心idea,只观其大略,不细究细节。可以说本文对于关注这个方向的知友只能取到导读的作用,大家要想真正深入理解,还是需要好好的看看具体的Paper。
3 Paper Idea简析
对于模仿学习Imitation Learning,可能很多人会觉得是不是只要监督学习就可以。确实,如果有巨量样本,并且覆盖各种对的,错的情况,那么直接拿这些样本训练一个神经网络也就完事了,Nvidia就干了这么个事Paper, 通过采集大量样本来实现无人驾驶。显然,这种通过异常暴力的手段来做模仿学习是非常局限的。样本没那么多怎么办?无法获取负样本怎么办?甚至没办法直接获取样本怎么办?(比如我们希望通过人示范来让机器人模仿)所以模仿学习有得研究。
[1] Model-Free Imitation Learning with Policy Optimization, OpenAI, 2016
模仿学习和增强学习不一样的很重要的一点是增强学习有Reward,而模仿学习没有。那么一种想法就是如果我们可以利用专家数据构造出这个Reward,那么显然我们也就可以使用这个Reward来采用DRL算法进行训练。这篇文章是在吴恩达提出的学徒学习Apprenticeship Learning的基础上进行神经网络化,从而使用Policy Gradient方法来更新网络,基本思想是利用当前策略的样本和专家样本估计出一个Reward函数,然后利用这个Reward进行DRL。但是基本上这篇文章的做法是很难真正Work到复杂场景的,关键还是这个Reward根据当前测量数据和专家数据来估计的准确性其实很低。就说让机器人倒水这种事,即使是人都很难界定一个动作的好坏,所以要能够更好构造Reward,或者直接不用Reward。
[2] Generative Adversarial Imitation Learning, OpenAI, 2016
这篇文章把GAN引入到Imitation Learning当中,基本的思路就是就是构造一个GAN,其中的Generator用于生成动作序列,而Discriminator则用于区分这个动作序列是专家动作还是不是。那么Discriminator的输出其实等价于Reward,Generator因此可以使用一般的DRL算法如TPRO来训练,通过这样的GAN的训练,希望Generator生成的动作和专家动作越来越接近。基于GAN的Imitation Learning这个做法非常的novel,换了一种方式来获取Reward(也可以说绕开了人为设定Reward的方式),可能最大的问题就是训练的效果可以达到怎样的程度。
[3] One-Shot Imitation Learning, OpenAI, 2017
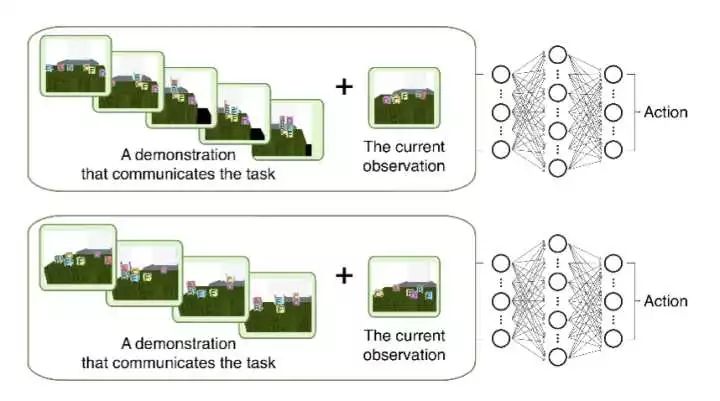
这篇文章比较有名了,OpenAI专门弄了个Blog Robots that Learn来介绍这个成果。确实做的比较有意思,能够让机器人使用机械臂搭积木。那么这篇文章的Idea是比较简单的,首先要注意这篇文章并没有使用视觉pixel信息输入,而是直接输入的积木的位置信息。这篇文章可以说是构建了一个带Condition的神经网络,输入Demo+当前state,然后输出Action。Demo(专家演示)作为一个条件输入。这样神经网络就可以区分任务Task。那么只要构造了足够多的Task,神经网络对于任务就有一定的区分度,从而面对一个新的同一个范围内的Task,也能够直接应对,从而实现One Shot。这篇文章的成果很Promising,基于Pixel的他们结合Meta Learning也做出来了,(初步了解)基本上就是用Meta Learning训练一个提取特征的base model,从而可以用少量数据就能对应到One Shot Imitation Learning的网络中。
[4] Third-Person Imitation Learning, OpenAI, 2017

这篇文章换了一个角度,之前的模仿学习都是第一视角,就是专家的视角和机器人的视角是一样的,但是实际上人类可以用第三视角看着老师做动作然后学习,因此也就是有了这篇文章。这篇文章延续了GAN的思路,但是加了两层的GAN,一个GAN是为了区分Domain也就是视角不一样,目的是通过这种训练让即使不同的视角也能提取出相同的Feature,另一个GAN就是区别是不是专家了,目的是构造出Reward用于DRL训练。总的来说,第三视角的模仿学习的关键是不同视角的特征一致性,只要能让不同视角得到相同特征输出,那么就可以无所谓视角了。
[5] Learning human behaviors from motion capture by adversarial imitation, DeepMind, 2017
接下来这两篇文章是DeepMind刚发布的,DeepMind也专门弄了个Blog https://deepmind.com/blog/producing-flexible-behaviours-simulated-environments/。 DeepMind的思路依然是以仿真为主,和OpenAI不一样。
那么这篇文章的出发点和OpenAI的也不一样。这篇文章是希望在原有DRL算法训练的基础上,通过模仿人类的动作来调整Policy,使得机器人的行为看起来更像人,而不是僵死。这篇文章的结果也确实让人大开眼界,机器人的行为看起来很人非常像,而使用人的样本还可以很少。想想波士顿动力的大狗,辛辛苦苦搞了几十年搞出来,现在通过深度学习可能可以更快更好的实现。之所以说更好是因为大狗的运动模式是固定的,但是通过神经网络可以赋予大狗各种各样的模式。就像这篇文章里面的例子,可以让机器人正常走也可以让其学醉汉走路,还可以通过键盘控制。所以这里也非常期待完全神经网络化的大狗机器人出来。
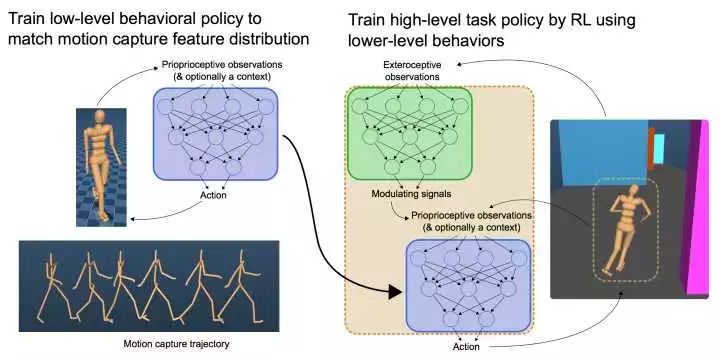
文章的思路还是基于GAN的方法,简称GAIL,也就是文章[2]。文章对[2]的方法进行了拓展,Discriminator甚至不需要输入action,而只需要state。
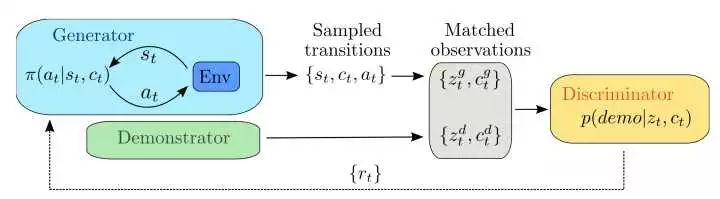
通过Motion Capture获取人的行为,然后训练一个discriminator作为reward function,然后使用TRPO算法进行DRL。这是第一次DeepMind使用OpenAI的人提出的DRL算法。看来TRPO在连续控制上还是有优势的。
[6] Robust Imitation of Diverse Behaviors, DeepMind, 2017

上一篇文章主要面向单一行为,而这篇文章则希望模仿多种行为。基本思路依然是在GAIL上进行改进,添加了一个VAE encoder从而更好的提取图像特征信息,使得整个GAIL更鲁棒,其他部分看起来没有太大变化。这篇文章因为加上了VAE Encoder,大幅度提升了信息量,对于一个全新的动作,也能够直接模仿,这点和One Shot Imitation Learning又很接近了。这里特别注意不同行为的模仿都只使用同一个Policy 网络。
总的来说DeepMind这两篇文章把GAIL方法应用到了一个新的境界,这效果一点不输OpenAI的真实机器人,反倒是OpenAI自己人提出的GAIL却没有发扬光大。
[7] Unsupervised Perceptual Rewards for Imitation Learning, Google Brain, 2017
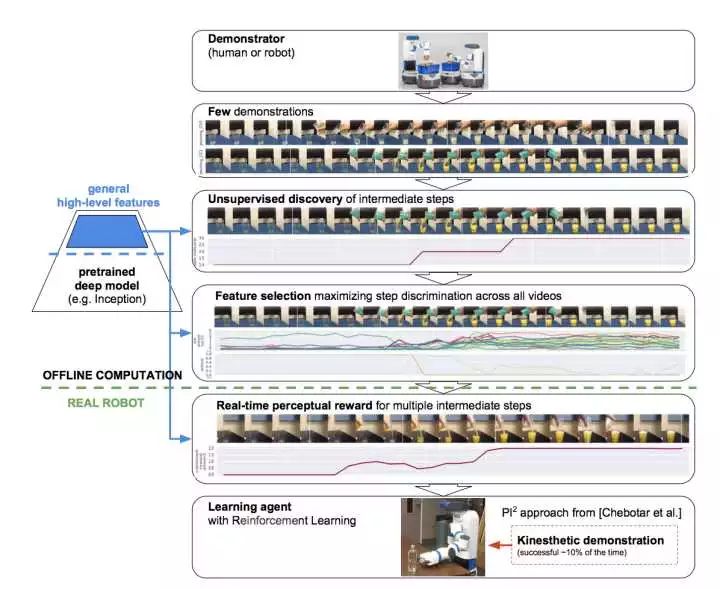
这篇文章的目的是构造Reward,但是希望完全无监督的生成Reward(其实我觉得对于Imitation Learning的问题也没法有监督呀,本来就没有Reward)。当然这里文章之所以说Unsupervised主要是说要让神经网络无监督的从视频中感知重要的过程。比如说倒水,会有很长一段时间,但是中间倒水的那个动作瞬间显然是最重要的。如果计算机自己能判断这种关键点,我们也就是能够大概的给出个reward,从而应用DRL。所以这篇文章也很牛逼,换句话说就是我们人给机器人示范了一系列动作,机器人可以自己判断哪些动作是关键的,并且弄出一条平滑的Reward Function曲线,然后就开始自己训练成功。而且这篇文章还是完全基于视觉的,这就很厉害了。这篇文章的方法是基于预训练的model如Inception来提取图像的特征,然后使用IRL来计算Reward。
[8] Time-Contrastive Networks: Self-Supervised Learning from Multi-View Observation, Google Brain, 2017
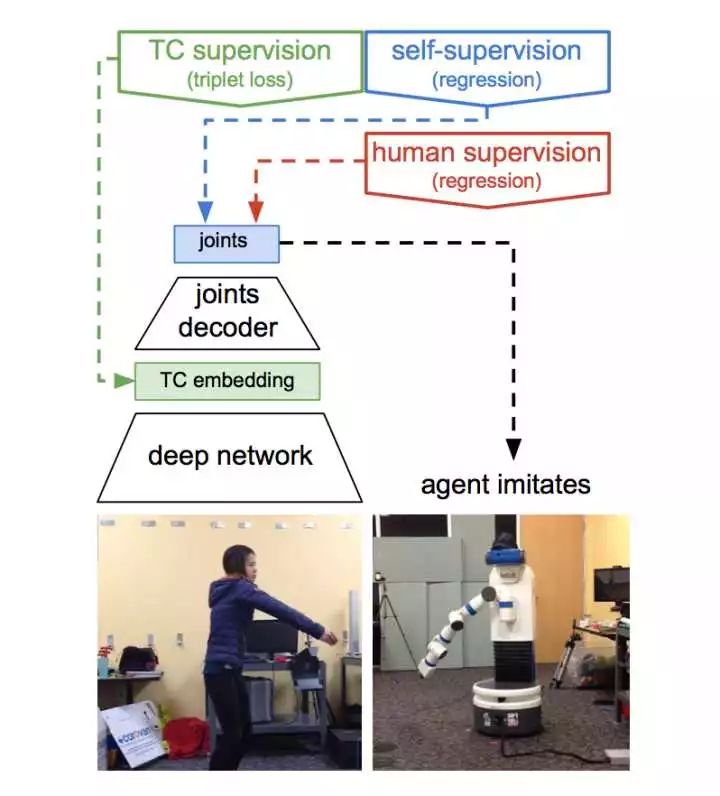
这篇文章提出一个Time-Contrastive Networks实际上就是把不同的视频帧做一个multi-view metric learning,让相同时间片的帧的特征聚在一起,不同时间片的帧的特征分得越开越好。那么在这样的训练基础下,本质和Third Person Imitation Learning非常接近,目的是让不同视角的特征输出尽量一样,这样也就可以模仿学习。也就是说既然人做的动作和机器人的动作要得到相同特征,那么机器人动作就和人动作一致。人做的动作基于图像输入到网络,输入机器人的关节动作,那么这个动作也就和人的动作一致。
[9] Imitation from Observation/ Learning to Imitate Behaviors from Raw Video via Context Translation, OpenAI, 2017
这篇文章是Third Person Imitation Learning的进一步研究,但是这篇文章牛大发了:

这篇文章做的想法非常夸张,直接对第三视角的视频进行转换,转成第一视角。然后使用神经网络提取的视频特征计算Reward从而应用DRL。看上面的图,第三个图是从第一个图转换过来的(完全通过神经网络输出),这转换的效果令人震惊!具体的训练方法其实还很简单,就是直接构造一个带Condition(也就是目标视角的第一帧图像)的Encoder-Decoder网络,然后直接用MSELoss计算预测图像与真实图像的偏差。当然,作者为了让提取的特征也一致,还加了特征的MSELoss。
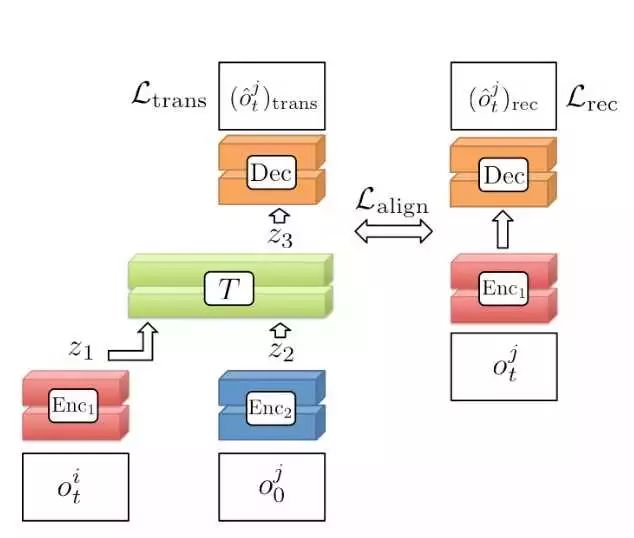
真的是思路简单,效果惊人。但是其实大家可以看到,基本思想还是要让不同视角输出的特征相一致。
最后
以上就是典雅自行车最近收集整理的关于imitation learning 前沿论文的全部内容,更多相关imitation内容请搜索靠谱客的其他文章。








发表评论 取消回复