2.1 决策树
2.1.1 决策树基本理论
1 原理
决策树是一种基本的分类与回归方法,其模型就是用一棵树来表示我们的整个决策过程。这棵树可以是二叉树(比如CART 只能是二叉树),也可以是多叉树(比如 ID3、C4.5 可以是多叉树或二叉树)。根节点包含整个样本集,每个叶节都对应一个决策结果(注意,不同的叶节点可能对应同一个决策结果),每一个内部节点都对应一次决策过程或者说是一次属性测试。从根节点到每个叶节点的路径对应一个判定测试序列。
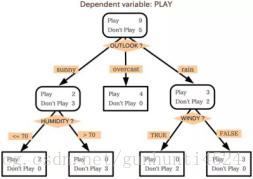
决策树的生成就是不断的选择最优的特征对训练集进行划分,是一个递归的过程。递归返回的条件有三种:
当前节点包含的样本属于同一类别,无需划分;
当前属性集为空,或所有样本在属性集上取值相同,无法划分;
当前节点包含样本集合为空,无法划分。
2 ID3、C4.5、CART
这三个是非常著名的决策树算法。简单粗暴来说:
ID3 使用信息增益作为选择特征的准则;
C4.5 使用信息增益比作为选择特征的准则;
CART 使用 Gini 指数作为选择特征的准则。
3 熵
在信息论与概率论中,熵用于表示随机变量不确定性的度量。
设X是一个有限状态的离散型随机变量,其概率分布为:
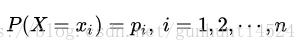
则随机变量X的熵定义为:
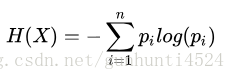
熵越大,则随机变量的不确定性越大。
条件熵(conditional entropy)
随机变量X给定的条件下,随机变量Y的条件熵H(Y|X)定义为:
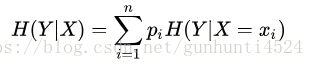
其中,pi = P(X = xi)。
信息增益(information gain)
信息增益表示的是:得知特征X的信息而使得类Y的信息的不确定性减少的程度。
特征A对训练数据集D的信息增益g(D,A)定义为集合D的经验熵H(D)与特征A给定条件下D的经验条件熵H(D|A)之差,即
g(D,A)=H(D)-H(D|A)
一般地,熵H(Y)与条件熵H(Y|X)之差称为互信息(mutual information).即:信息增益也称为互信息。
ID3
熵表示的是数据中包含的信息量大小(混乱度)。熵越小,数据的纯度越高,也就是说数据越趋于一致,这是我们希望的划分之后每个子节点的样子。
信息增益 = 划分前熵 - 划分后熵。信息增益越大,则意味着使用属性a来进行划分所获得的 “纯度提升” 越大 。也就是说,用属性a来划分训练集,得到的结果中纯度比较高。
ID3 仅仅适用于二分类问题。ID3 仅仅能够处理离散属性。
C4.5
C4.5 克服了 ID3 仅仅能够处理离散属性的问题,以及信息增益偏向选择取值较多特征的问题,使用信息增益比来选择特征。信息增益比 = 信息增益 / 划分前熵 选择信息增益比最大的作为最优特征。公式:
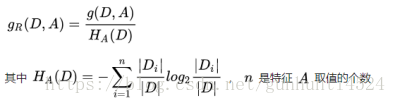
C4.5 处理连续特征是先将特征取值排序,以连续两个值中间值作为划分标准。尝试每一种划分,并计算修正后的信息增益,选择信息增益最大的分裂点作为该属性的分裂点。
CART
CART 与 ID3,C4.5 不同之处在于 CART 生成的树必须是二叉树。也就是说,无论是回归还是分类问题,无论特征是离散的还是连续的,无论属性取值有多个还是两个,内部节点只能根据属性值进行二分。
CART 的全称是分类与回归树(classification and regression tree)。从这个名字中就应该知道,CART 既可以用于分类问题,也可以用于回归问题。
回归树
使用平方误差最小化准则来选择特征并进行划分。每一个叶子节点给出的预测值,是划分到该叶子节点的所有样本目标值的均值,这样只是在给定划分的情况下最小化了平方误差。
要确定最优化分,还需要遍历所有属性,以及其所有的取值来分别尝试划分并计算在此种划分情况下的最小平方误差,选取最小的作为此次划分的依据。由于回归树生成使用平方误差最小化准则,所以又叫做最小二乘回归树。
具体为,假设已将输入空间划分为 M 个单元R1,R2,...,Rm,即 M 个特征,并且在每个单元Rm上有一个固定的输出值Cm,于是回归树可以表示为
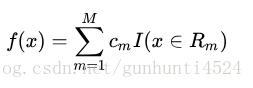
当输入空间的划分确定时,可以用平方误差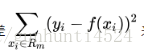 来表示回归树对于训练数据的预测误差,用平方误差最小的准则求解每个单元上的最优值。
来表示回归树对于训练数据的预测误差,用平方误差最小的准则求解每个单元上的最优值。


1.3 信息增益 vs 信息增益比
之所以引入了信息增益比,是由于信息增益的一个缺点。那就是:信息增益总是偏向于选择取值较多的属性。信息增益比在此基础上增加了一个罚项,解决了这个问题。
Gini 指数 vs 熵
既然这两个都可以表示数据的不确定性,不纯度。那么这两个有什么区别那?
Gini 指数的计算不需要对数运算,更加高效;
Gini 指数更偏向于连续属性,熵更偏向于离散属性。
剪枝
决策树算法很容易过拟合(overfitting),剪枝算法就是用来防止决策树过拟合,提高泛华性能的方法,剪枝分为预剪枝与后剪枝。
预剪枝是指在决策树的生成过程中,对每个节点在划分前先进行评估,若当前的划分不能带来泛化性能的提升,则停止划分,并将当前节点标记为叶节点。
后剪枝是指先从训练集生成一颗完整的决策树,然后自底向上对非叶节点进行考察,若将该节点对应的子树替换为叶节点,能带来泛化性能的提升,则将该子树替换为叶节点。
那么怎么来判断是否带来泛化性能的提升呢?最简单的就是留出法,即预留一部分数据作为验证集来进行性能评估。交叉验证
预剪枝和后剪枝的比较
总结
决策树算法主要包括三个部分:特征选择、树的生成、树的剪枝。常用算法有 ID3、C4.5、CART。
特征选择。特征选择的目的是选取能够对训练集分类的特征。特征选择的关键是准则:信息增益、信息增益比、Gini 指数;
决策树的生成。通常是利用信息增益最大、信息增益比最大、Gini 指数最小作为特征选择的准则。从根节点开始,递归的生成决策树。相当于是不断选取局部最优特征,或将训练集分割为基本能够正确分类的子集;
决策树的剪枝。决策树的剪枝是为了防止树的过拟合,增强其泛化能力。包括预剪枝和后剪枝。
最后
以上就是魔幻山水最近收集整理的关于决策树总结的全部内容,更多相关决策树总结内容请搜索靠谱客的其他文章。








发表评论 取消回复