一、原理
决策树是一种非参数的监督学习方法,它主要用于分类和回归。决策树的目的是构造一种模型,使之能够从样本数据的特征属性中,通过学习简单的决策规则——IF THEN规则,从而预测目标变量的值。
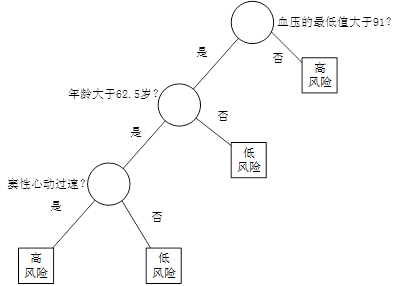
图1 决策树
例如,在某医院内,对因心脏病发作而入院治疗的患者,在住院的前24小时内,观测记录下来他们的19个特征属性——血压、年龄、以及其他17项可以综合判断病人状况的重要指标,用图1所示的决策树判断病人是否属于高危患者。在图1中,圆形为中间节点,也就是树的分支,它代表IF THEN规则的条件;方形为终端节点(叶节点),也就是树的叶,它代表IF THEN规则的结果。我们也把第一个节点称为根节点。
决策树往往采用的是自上而下的设计方法,每迭代循环一次,就会选择一个特征属性进行分叉,直到不能再分叉为止。因此在构建决策树的过程中,选择最佳(既能够快速分类,又能使决策树的深度小)的分叉特征属性是关键所在。这种“最佳性”可以用非纯度(impurity)进行衡量。如果一个数据集合中只有一种分类结果,则该集合最纯,即一致性好;反之有许多分类,则不纯,即一致性不好。有许多指标可以定量的度量这种非纯度,最常用的有熵,基尼指数(Gini Index)和分类误差,它们的公式分别为:
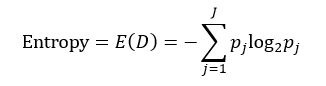 (1)
(1)
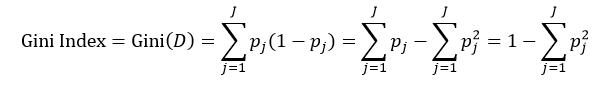 (2)
(2)
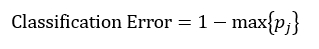 (3)
(3)
上述所有公式中,值越大,表示越不纯,这三个度量之间并不存在显著的差别。式中D表示样本数据的分类集合,并且该集合共有J种分类,pj表示第j种分类的样本率:
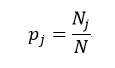 (4)
(4)
式中N和Nj分别表示集合D中样本数据的总数和第j个分类的样本数量。把式4带入式2中,得到:
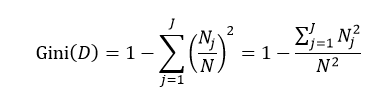 (5)
(5)
目前常用的决策树的算法包括ID3(Iterative Dichotomiser 3,第3代迭戈二叉树)、C4.5和CART(ClassificationAnd Regression Tree,分类和回归树)。前两种算法主要应用的是基于熵的方法,而第三种应用的是基尼指数的方法。下面我们就逐一介绍这些方法。
ID3是由Ross Quinlan首先提出,它是基于所谓“Occam'srazor”(奥卡姆剃刀),即越简单越好,也就是越是小型的决策树越优于大型的决策树。如前所述,我们已经有了熵作为衡量样本集合纯度的标准,熵越大,越不纯,因此我们希望在分类以后能够降低熵的大小,使之变纯一些。这种分类后熵变小的判定标准可以用信息增益(Information Gain)来衡量,它的定义为:
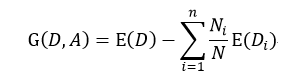 (6)
(6)
该式表示在样本集合D下特征属性A的信息增益,n表示针对特征属性A,样本集合被划分为n个不同部分,即A中包含着n个不同的值,Ni表示第i个部分的样本数量,E(Di)表示特征属性A下第i个部分的分类集合的熵。信息增益越大,分类后熵下降得越快,则分类效果越好。因此我们在D内遍历所有属性,选择信息增益最大的那个特征属性进行分类。在下次迭代循环中,我们只需对上次分类剩下的样本集合计算信息增益,如此循环,直至不能再分类为止。
C4.5算法也是由Quinlan提出,它是ID3算法的扩展。ID3应用的是信息增益的方法,但这种方法存在一个问题,那就是它会更愿意选择那些包括很多种类的特征属性,即哪个A中的n多,那么这个A的信息增益就可能更大。为此,C4.5使用信息增益率这一准则来衡量非纯度,即:
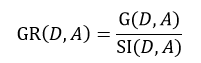 (7)
(7)
式中,SI(D, A)表示分裂信息值,它的定义为:
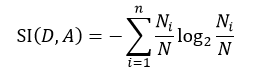 (8)
(8)
该式中的符号含义与式6相同。同样的,我们选择信息增益率最大的那个特征属性作为分类属性。
CART算法是由Breiman等人首先提出,它包括分类树和回归树两种。我们先来讨论分类树,针对特征属性A,分类后的基尼指数为:
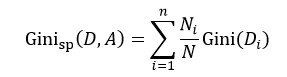 (9)
(9)
该式中的符号含义与式6相同。与ID3和C4.5不同,我们选择分类基尼指数最小的那个特征属性作为分类属性。当我们每次只想把样本集合分为两类时,即每个中间节点只产生两个分支,但如果特征属性A中有多于2个的值,即n> 2,这时我们就需要一个阈值β,它把D分割成了D1和D2两个部分,不同的β得到不同的D1和D2,我们重新设D1的样本数为L,D2的样本数为R,因此有L+ R = N,则式9可简写为:
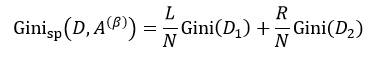 (10)
(10)
我们把式5带入上式中,得到:
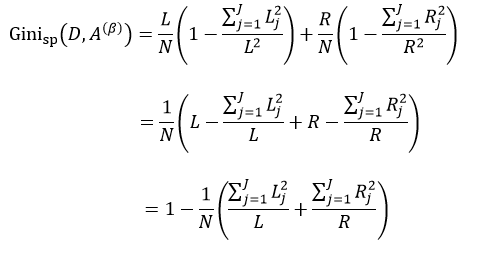 (11)
(11)
式中,∑Lj = L,∑Rj = R。式11只是通过不同特征属性A的不同阈值β来得到样本集D的不纯度,由于D内的样本数量N是一定的,因此对式11求最小值问题就转换为求式12的最大值问题:
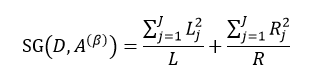 (12)
(12)
以上给出的是分类树的计算方法,下面介绍回归树。两者的不同之处是,分类树的样本输出(即响应值)是类的形式,如判断蘑菇是有毒还是无毒,周末去看电影还是不去。而回归树的样本输出是数值的形式,比如给某人发放房屋贷款的数额就是具体的数值,可以是0到120万元之间的任意值。为了得到回归树,我们就需要把适合分类的非纯度度量用适合回归的非纯度度量取代。因此我们将熵计算用均方误差替代:
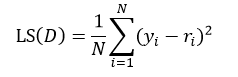 (13)
(13)
式中N表示D集合的样本数量,yi和ri分别为第i个样本的输出值和预测值。如果我们把样本的预测值用样本输出值的平均来替代,则式13改写为:
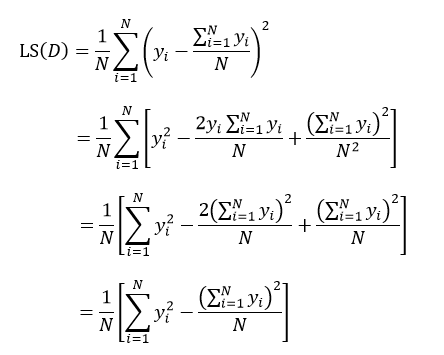 (14)
(14)
上式表示了集合D的最小均方误差,如果针对于某种特征属性A,我们把集合D划分为s个部分,则划分后的均方误差为:
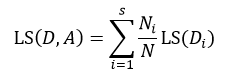 (15)
(15)
式中Ni表示被划分的第i个集合Di的样本数量。式15与式14的差值为划分为s个部分后的误差减小:
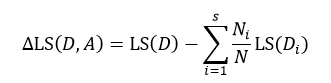 (16)
(16)
与式6所表示的信息增益相似,我们寻求的是最大化的误差减小,此时就得到了最佳的s个部分的划分。
同样的,当我们仅考虑二叉树的情况时,即每个中间节点只有两个分支,此时s= 2,基于特征属性A的值,集合D被阈值β划分为D1和D2两个集合,每个集合的样本数分别为L和R,则:
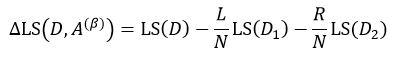 (17)
(17)
把式14带入上式,得:
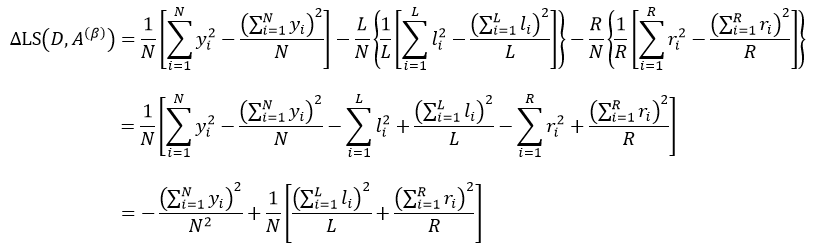 (18)
(18)
式中,yi是属于集合D的样本响应值,li和ri分别是属于集合D1和D2的样本响应值。对于某个节点来说,它的样本数量以及样本响应值的和是一个定值,因此式18的结果完全取决于方括号内的部分,即:
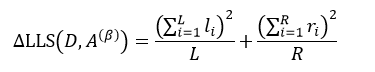 (19)
(19)
因此求式18的最大值问题就转变为求式19的最大值问题。
我们按照样本响应值是类的形式,还是数值的形式,把决策树分成了分类树和回归树,它们对应不同的计算公式。那么表示特征属性的形式也会有这两种形式,即类的形式和数值的形式,比如决定是否出去踢球,取决于两个条件:风力和气温。风力的表示形式是:无风、小风、中风、大风,气温的表示形式就是具体的摄氏度,如-10℃~40℃之间。风力这个特征属性就是类的形式,而气温就是数值的形式。又比如决定发放房屋贷款,其金额取决于两个条件:是否有车有房和年薪。有车有房的表示形式是:无车无房、有车无房、无车有房、有车有房,而年薪的表示形式就是具体的钱数,如0~20万。有车有房这个特征属性就是类的形式,年薪就是数值的形式。因此在分析样本的特征属性时,我们要把决策树分为四种情况:特征为类的分类树(如决定是否踢球的风力)、特征为数值的分类树(如决定是否踢球的温度)、特征为类的回归树(如发放贷款的有车有房)和特征为数值的回归树(如发放贷款的年薪)。由于特征形式不同,所以计算方法上有所不同:
Ⅰ、特征为类的分类树:对于两类问题,即样本的分类(响应值)只有两种情况:响应值为0和1,按照特征属性的类别的样本响应值为1的数量的多少进行排序。例如我们采集20个样本来构建是否踢球分类树,设出去踢球的响应值为1,不踢球的响应值为0,针对风力这个特征属性,响应值为1的样本有14个,无风有6个样本,小风有5个,中风2个,大风1个,则排序的结果为:大风<中风<小风<无风。然后我们按照这个顺序依次按照二叉树的分叉方式把样本分为左分支和右分支,并带入式12求使该式为最大值的那个分叉方式,即先把是大风的样本放入左分支,其余的放入右分支,带入式12,得到A,再把大风和中风放入左分支,其余的放入右分支,带入式12,得到B,再把大风、中风和小风放入左分支,无风的放入右分支,计算得到C,比较A、B、C,如果最大值为C,则按照C的分叉方式划分左右分支,其中阈值β可以设为3。对于非两类问题,采用的是聚类的方法。
Ⅱ、特征为数值的分类树:由于特征属性是用数值进行表示,我们就按照数值的大小顺序依次带入式12,计算最大值。如一共有14个样本,按照由小至大的顺序为:abcdefghijklmn,第一次分叉为:a|bcdefghijklmn,竖线“|”的左侧被划分到左分支,右侧被划分到右分支,带入式12计算其值,然后第二次分叉:ab|cdefghijklmn,同理带入式12计算其值,以此类推,得到这13次分叉的最大值,该种分叉方式即为最佳的分叉方式,其中阈值β为分叉的次数。
Ⅲ、特征为类的回归树:计算每种特征属性各个种类的平均样本响应值,按照该值的大小进行排序,然后依次带入式19,计算其最大值。
Ⅳ、特征为数值的回归树:该种情况与特征为数值的分类树相同,就按照数值的大小顺序依次带入式19,计算最大值。
在训练决策树时,还有三个技术问题需要解决。第一个问题是,对于分类树,我们还需要考虑一种情况,当用户想要检测一些非常罕见的异常现象的时候,这是非常难办到的,这是因为训练可能包含了比异常多得多的正常情况,那么很可能分类结果就是认为每一个情况都是正常的。为了避免这种情况的出现,我们需要设置先验概率,这样异常情况发生的概率就被人为的增加(可以增加到0.5甚至更高),这样被误分类的异常情况的权重就会变大,决策树也能够得到适当的调整。先验概率需要根据各自情况人为设置,但还需要考虑各个分类的样本率,因此这个先验值还不能直接应用,还需要处理。设Qj为我们设置的第j个分类的先验概率,Nj为该分类的样本数,则考虑了样本率并进行归一化处理的先验概率qj为:
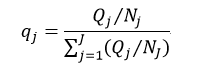 (20)
(20)
把先验概率带入式12中,则得到:
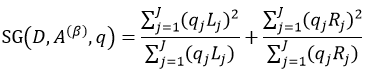 (21)
(21)
第二个需要解决的问题是,某些样本缺失了某个特征属性,但该特征属性又是最佳分叉属性,那么如何对该样本进行分叉呢?目前有几种方法可以解决该问题,一种是直接把该样本删除掉;另一种方法是用各种算法估计该样本的缺失属性值。还有一种方法就是用另一个特征属性来替代最佳分叉属性,该特征属性被称为替代分叉属性。因此在计算最佳分叉属性的同时,还要计算该特征属性的替代分叉属性,以防止最佳分叉属性缺失的情况。CART算法就是采用的该方法,下面我们就来介绍该方法。
寻找替代分叉属性总的原则就是使其分叉的效果与最佳分叉属性相似,即分叉的误差最小。我们仍然根据特征属性是类还是数值的形式,也把替代分叉属性的计算分为两种情况。
当特征属性是类的形式的时候,当最佳分叉属性不是该特征属性时,会把该特征属性的每个种类分叉为不同的分支,例如当最佳分叉属性不是风力时,极有可能把5个无风的样本分叉为不同的分支(如3个属于左分支,2个属于右分支),但当最佳分叉属性是风力时,这种情况就不会发生,也就是5个无风的样本要么属于左分支,要么属于右分支。因此我们把被最佳分叉属性分叉的特征属性种类的分支最大样本数量作为该种类的分叉值,计算该特征属性所有种类的这些分叉值,最终这些分叉值之和就作为该替代分叉属性的分叉值。我们还看前面的例子,无风的分叉值为3,再计算小风、中风、大风的分叉值,假如它们的值分别为4、4、3,则把风力作为替代分叉属性的分叉值为14。按照该方法再计算其他特征属性是类形式的替代分叉值,则替代性由替代分叉值按从大到小进行排序。在用替代分叉属性分叉时那些左分支大于右分支样本数的种类被分叉为左分支,反之为右分支,如上面的例子,无风的样本被分叉为左分支。
当特征属性是数值的形式的时候,样本被分割成了四个部分:LL、LR、RL和RR,前一个字母表示被最佳分叉属性分叉为左右分支,后一个字母表示被替代分叉属性分叉为左右分支,如LR表示被最佳分叉属性分叉为左分支,但被替代分叉属性分叉为右分支的样本,因此LL和RR表示的是被替代分叉属性分叉正确的样本,而LR和RL是被替代分叉属性分叉错误的样本,在该特征属性下,选取阈值对样本进行分割,使LL+RR或LR+RL达到最大值,则最终max{LL+RR,LR+RL}作为该特征属性的替代分叉属性的分叉值。按照该方法再计算其他特征属性是数值形式的替代分叉值,则替代性也由替代分叉值按从大到小进行排序。最终我们选取替代分叉值最大的那个特征属性作为该最佳分叉属性的替代分叉属性。
为了让替代分叉属性与最佳分叉属性相比较,我们还需要对替代分叉值进行规范化处理,如果替代分叉属性是类的形式,则替代分叉值需要乘以式12再除以最佳分叉属性中的种类数量,如果替代分叉属性是数值的形式,则替代分叉值需要乘以式19再除以所有样本的数量。规范化后的替代分叉属性如果就是最佳分叉属性时,两者的值是相等的。
第三个问题就是过拟合。由于决策树的建立完全是依赖于训练样本,因此该决策树对该样本能够产生完全一致的拟合效果。但这样的决策树对于预测样本来说过于复杂,对预测样本的分类效果也不够精确。这种现象就称为过拟合。
将复杂的决策树进行简化的过程称为剪枝,它的目的是去掉一些节点,包括叶节点和中间节点。剪枝常用的方法有预剪枝和后剪枝两种。预剪枝是在构建决策树的过程中,提前终止决策树的生长,从而避免过多的节点的产生。该方法虽然简单但实用性不强,因为我们很难精确的判断何时终止树的生长。后剪枝就是在决策树构建完后再去掉一些节点。常见后剪枝方法有四种:悲观错误剪枝(PEP)、最小错误剪枝(MEP)、代价复杂度剪枝(CCP)和基于错误的剪枝(EBP)。CCP算法能够应用于CART算法中,它的本质是度量每减少一个叶节点所得到的平均错误,在这里我们重点介绍CCP算法。
CCP算法会产生一系列树的序列{T0,T1,…,Tm},其中T0是由训练得到的最初的决策树,而Tm只含有一个根节点。序列中的树是嵌套的,也就是序列中的Ti+1是由Ti通过剪枝得到的,即实现用Ti+1中一个叶节点来替代Ti中以该节点为根的子树。这种被替代的原则就是使误差的增加率α最小,即
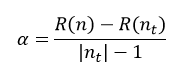 (22)
(22)
式中,R(n)表示Ti中节点n的预测误差,R(nt)表示Ti中以节点n为根节点的子树的所有叶节点的预测误差之和,|nt|为该子树叶节点的数量,|nt|也被称为复杂度,因为叶节点越多,复杂性当然就越强。因此α的含义就是用一个节点n来替代以n为根节点的所有|nt|个节点的误差增加的规范化程度。在Ti中,我们选择最小的α值的节点进行替代,最终得到Ti+1。以此类推,每需要得到一棵决策树,都需要计算其前一棵决策树的α值,根据α值来对前一棵决策树进行剪枝,直到最终剪枝到只剩下含有一个根节点的Tm为止。
根据决策树是分类树还是回归树,节点的预测误差的计算也分为两种情况。在分类树下,我们可以应用上面介绍过的式1~式3中的任意一个,如果我们应用式3来表示节点n的预测误差,则:
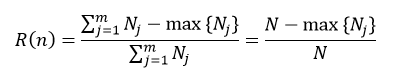 (23)
(23)
式中,Nj表示节点n下第j个分类的样本数,N为该节点的所有样本数,max{Nj}表示在m个分类中,拥有样本数最多的那个分类的样本数量。在回归树下,我们可以应用式14来表示节点n的预测误差:
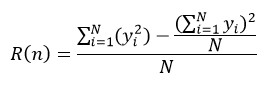 (24)
(24)
式中,yi表示第i个样本的响应值,N为该节点的样本数量。我们把式23和式24的分子部分称为节点的风险值。
我们用全部样本得到的决策树序列为{T0,T1,…,Tm},其所对应的α值为α0<α1<…<αm。下一步就是如何从这个序列中最优的选择一颗决策树Ti。而与其说找到最优的Ti,不如说找到其所对应的αi。这一步骤通常采用的方法是交叉验证(Cross-Validation)。
我们把L个样本随机划分为数量相等的V个子集Lv,v=1,…,V。第v个训练样本集为:
 (25)
(25)
则Lv被用来做L(v)的测试样本集。对每个训练样本集L(v)按照CCP算法得到决策树的序列{T0(v),T1(v),…,Tm(v) },其对应的α值为α0(v)<α1(v)<…<αm(v)。α值的计算仍然采用式22。对于分类树来说,第v个子集的节点n的预测误差为:
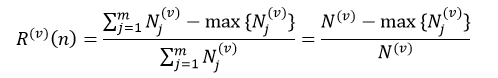 (26)
(26)
式中,Nj(v)表示训练样本集L(v)中节点n的第j个分类的样本数,N(v)为L(v)中节点n的所有样本数,max{Nj(v)}表示在m个分类中,L(v)中节点n拥有样本数最多的那个分类的样本数量。对于回归树来说,第v个子集的节点n的预测误差为:
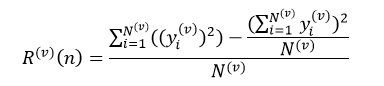 (27)
(27)
式中,yj(v)表示训练样本集L(v)中节点n的第i个样本的响应值。我们仍然把式26和式27的分子部分称交叉验证子集中的节点风险值。
我们由训练样本集得到了树序列,然后应用这些树对测试样本集进行测试,测试的结果用错误率来衡量,即被错误分类的样本数量。对于分类树来说,节点n的错误率为:
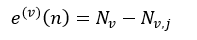 (28)
(28)
式中,Nv表示测试样本集Lv中节点n的所有样本数,Nv,j表示Lv中第j个分类的样本数,这个j是式26中max{|Lj(v)|}所对应的j。对于回归树来说,节点n的错误率为:
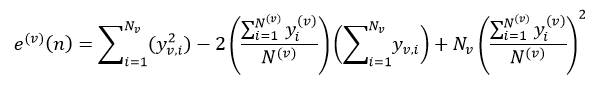 (29)
(29)
式中,yv,i表示Lv的第i个样本响应值。决策树的总错误率E(v)等于该树所有叶节点的错误率之和。
虽然交叉验证子集决策树序列T(v)的数量要与由全体样本得到的决策树序列T的数量相同,但两者构建的形式不同,它需要比较两者的α值后再来构建。而为了比较由全体样本训练得到α值与交叉验证子集的α(v)值之间的大小,我们还需要对α值进行处理,即
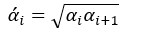 (30)
(30)
其中α’0 = 0,而α’m为无穷大。
我们设按照式22得到的初始训练子集L(v)决策树序列为{T0(v),T1(v),…,Tm(v)},其所对应的α(v)值为{α0(v), α1(v),…,αm(v)}。最终的树序列也是由这些T(v)组成,并且也是嵌套的形式,但可以重复,而且必须满足:
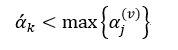 (31)
(31)
该式的含义是T(v)中第k个子树的α(v)值要小于α’k的最大的α(v)所对应的子树,因此最终的树序列有可能是这种形式:T0(v),T0(v),T1(v),T1(v),T2(v),T2(v),T2(v),T2(v),…,直到序列中树的数量为m为止。
子集的决策树序列构建好了,下面我们就可以计算V个子集中树序列相同的总错误率之和,即
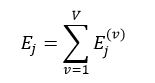 (32)
(32)
则最佳的子树索引J为:
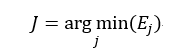 (33)
(33)
最终我们选择决策树序列{T0,T1,…,Tm}中第J棵树为最佳决策树,该树的总错误率最小。
如果我们在选择决策树时使用1-SE(1 Standard Error of Minimum Error)规则的话,那么有可能最终的决策树不是错误率最小的子树,而是错误率略大,但树的结构更简单的那颗决策树。我们首先计算误差范围SE:
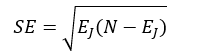 (34)
(34)
式中,EJ表示最佳子树的总错误率,N为总的样本数。则最终被选中的决策树的总错误率EK要满足:
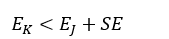 (35)
(35)
并且决策树的结构最简单。
以上我们完整并详细的介绍了构建决策树,也就是训练决策树的过程,在这个过程中我们没有放过每个技术细节。而预测样本很简单,只要把样本按照最佳分叉属性(或替代分叉属性)一次一次分叉,直到到达决策树的叶节点,该叶节点的值就是该预测样本的响应值。
代码实现在blog中有,我就不copy了,http://blog.csdn.net/zhaocj/article/details/50503450在里面可以看到完整的代码
最后
以上就是飘逸小虾米最近收集整理的关于决策树的完整知识点总结的全部内容,更多相关决策树内容请搜索靠谱客的其他文章。








发表评论 取消回复