本文的主要内容是基于Python机器学习基础教程决策树部分进行整理和总结。
模型描述
梯度提升回归树和随机森林一样,是一种决策树集成方法,通过合并多个决策树来构建一个更为强大的模型。虽然名字中有“回归”,但是该方法既能用于回归问题,也能用于分类问题,与随机森林不同的是,梯度提升回归树(GBDT)采用连续的方式构造树,每棵树都在试图修正前一棵树的错误。默认情况下,梯度提升回归树没有随机化,而是用到了强预剪枝,并且梯度提升通常使用深度很小(1<max_depth<5)的树。这样的模型占用内存小,预测速度也更快。
梯度提升的主要思想在于合并多个简单模型,每棵树只能对部分数据做出好的预测,添加的树越多,就可以不断的迭代提高性能。
与随机森林相比,梯度提升对参数设置更为敏感,如果参数设置正确的话,模型精度也会更高。
Sklearn实现
应用梯度提升算法对乳腺癌数据进行预测,默认使用100棵树,最大深度3,学习率0.1(学习率用于控制每棵树纠正前一棵树错误的强度,高学习率对应更复杂的模型)
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_breast_cancer
from sklearn.ensemble import GradientBoostingClassifier
cancer = load_breast_cancer()
X_train,X_test,y_train,y_test = train_test_split(cancer['data'],cancer['target'],random_state=0)
gbdt = GradientBoostingClassifier(random_state=0)
gbdt.fit(X_train,y_train)
print("Accuracy of train set {:.3f}".format(gbdt.score(X_train,y_train)))
print("Accuracy of test set {:.3f}".format(gbdt.score(X_test,y_test)))
Accuracy of train set 1.000
Accuracy of test set 0.958
训练精度过高,判断存在过拟合,此时可以通过两个方法减小过拟合,降低决策树最大深度max_depth和降低学习率learning_rate来降低模型复杂度,抑制过拟合。
降低决策树最大深度:
gbdt = GradientBoostingClassifier(max_depth=1,random_state=0)
gbdt.fit(X_train,y_train)
print("Accuracy of train set {:.3f}".format(gbdt.score(X_train,y_train)))
print("Accuracy of test set {:.3f}".format(gbdt.score(X_test,y_test)))
Accuracy of train set 0.991
Accuracy of test set 0.972
降低学习率:
gbdt = GradientBoostingClassifier(learning_rate=0.01,random_state=0)
gbdt.fit(X_train,y_train)
print("Accuracy of train set {:.3f}".format(gbdt.score(X_train,y_train)))
print("Accuracy of test set {:.3f}".format(gbdt.score(X_test,y_test)))
Accuracy of train set 0.988
Accuracy of test set 0.965
可以看到,使用上述两种方法都达到了减小过拟合,提高测试集精度的目的。
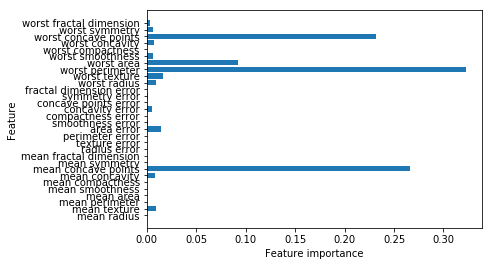
特征重要性的可视化:
def plot_feature_importances_cancer(model):
n_features = cancer.data.shape[1]
plt.barh(range(n_features),model.feature_importances_,align='center')
plt.yticks(np.arange(n_features),cancer.feature_names)
plt.xlabel('Feature importance')
plt.ylabel("Feature")
plot_feature_importances_cancer(gbdt)
模型评价
- 由于梯度提升和随机森林在类似的数据上都具有很好的性能,因此一种常用的方法就是先使用随机森林,它的鲁棒性很好,若使用随机森林预测时间过长,那么切换成梯度提升通常会有用;
- 梯度提升不需要对数据进行缩放(如归一化或标准化),也适用于二元特征和连续特征同时存在的数据集;
- 该模型的一个主要缺点就是需要仔细调参,同时不适用于高维稀疏矩阵;
- 梯度提升树模型的主要参数包括树的数量n_estimators和学习率learning_rate,learning_rate主要用于控制每棵树对前一棵树的纠正强度,learning_rate越低,就需要更多的树来构建具有相似复杂度的模型,增大n_estimators会导致模型复杂,所以通常的做法是根据时间和内存的预算选择合适的n_estimators,然后对不同的learning_rate进行遍历。
最后
以上就是眼睛大衬衫最近收集整理的关于梯度提升回归树(GBDT)模型描述Sklearn实现模型评价的全部内容,更多相关梯度提升回归树(GBDT)模型描述Sklearn实现模型评价内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复