决策树的思路是这样的,假设有两个属性A,B,分别有两个值0,1,当A=0,B=0时这是个鸡,当A=0,B=1时是鸭,当A=1,B=0时是猫,当A=1,B=1时是狗。现在给了一个未知类别的物体,其属性是A=1,B=1,那么按照先判断A,后判断B的过程,得到如下决策流程:
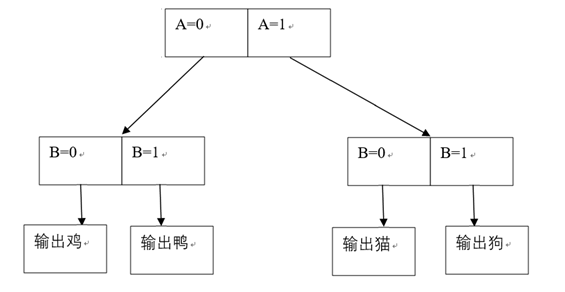
很简单的一种分类方法吧。
实际上也是这样,最简单的决策树,就是从第一个属性的值开始进行分组,根据值的不同分成了不同子树,接着下一层用第二个属性的值分组,再下一层用第三个,以此类推,直到:
① 这个属性值分出来的子树中只有一个类别了;
② 将所有的属性都已经用完了,即树到了第N层(属性个数N)。
满足上述两个条件之一则为叶子结点,返回。
特别要说明的是条件②,因为再这种情况下可能叶子结点里的数据并不是同一类的,此时选择数量较多的那个类就行了。
这个超简单的决策树就构建完成了,接下来如果输入一个未知类别的物体,那么走完这个决策树就会返回该算法预测的类别。
接下来我们看香农熵下的决策树(也就是书中的决策树)。
上面讲的简单决策树可以看到,选取哪个属性优先分组是我们默认的,从第一个依次类推。
而实际上选择属性的顺序非常重要,它关系到我们建立的这棵决策树的层数(层数约高耗时越长),那么我们应该按照什么顺序来选择分组的属性呢?
有一种想法是希望我们每次分组之后,最好都出现像上面简图那样的情况,尽量一个类别的数据集中在一起或者两个类别较均匀的分布,而避免出现分组后很多类别都在一棵子树上,这样会增加我们接下来对子树的分类量。
香农熵就是用来评估这个的,它衡量了信息的复杂程度,其定义为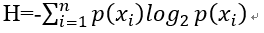
其中p(xi)为这个类别在这个子树中的概率,即所占的比例。
可以看到,一个类所占比例越大,-log2(p(xi))就越小,一个类所占比例越小,这个值就越大(注意那个负号,以及概率是一个小于等于1的数),当一个子树中只有一个类时,这个公式计算出来的香农熵为0,最小,假设有两个类别,那么这两个类别均匀的各占0.5所计算出来的H最小,这是-log2(p(xi))的意义,而之所以还有按比例求和的一步,是因为我们需要考虑各个子树的权重,不能说一个子树里只有一个数据,和另一个含有100个数据的两个均匀布置的子树等价,即把子树的数据量也考虑进去了,从而构成了香农熵。
可以预见,因为每次去掉一个属性,所以香农熵是递减的,即信息的复杂程度在逐渐减少,我们在每一次分组前,用每一个属性去试,看按这个属性分组后,香农熵减少多少,选取其中减少最大的一个属性(贪心),从而构成了属性决策的顺序。
总结:从整个过程可以看出,这个决策树只能处理那些属性值为离散的有限数值的分类问题,这个算法成为ID3,还有一些其他算法在后续章节才会介绍。
另外,该章节中python的一些运用很有意思,比如用字典构建树结构。
最后
以上就是坦率帆布鞋最近收集整理的关于《机器学习实战》-决策树算法心得的全部内容,更多相关《机器学习实战》-决策树算法心得内容请搜索靠谱客的其他文章。





![决策表(决策树)[软件工程]](https://www.shuijiaxian.com/files_image/reation/bcimg14.png)


发表评论 取消回复