大数据工作室学习打卡 第 N 次
一、Boosting(提升)
1.什么是集成学习?
首先,我们得先了解什么是集成学习,集成学习是一种通过组合弱学习器来产生强学习器的通用且有效的方法,简单来说,就是通过训练多个分类器,然后将其组合起来,从而达到更好的预测性能,提高分类器的泛化能力。
如下图:
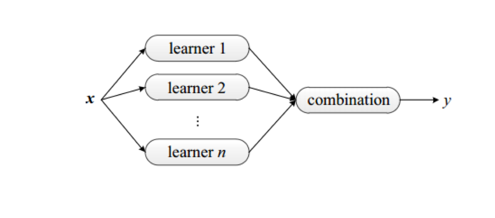
2.什么是boosting(提升)?
boosting和集成学习什么关系?
前面我们了解了集成学习,那么集成学习的关键就在于如何组合多个弱学习器,所以依次发展出了三大主要框架:
- bagging
- boosting
- stacking
显而易见,boosting是集成学习中的一种框架。
boosting每次对训练集进行转换后重新训练出基模型,最后再综合所有的基模型预测结果。主要算法有AdaBoost(adaptive boosting自适应增强) 和 GBDT。
如下图:
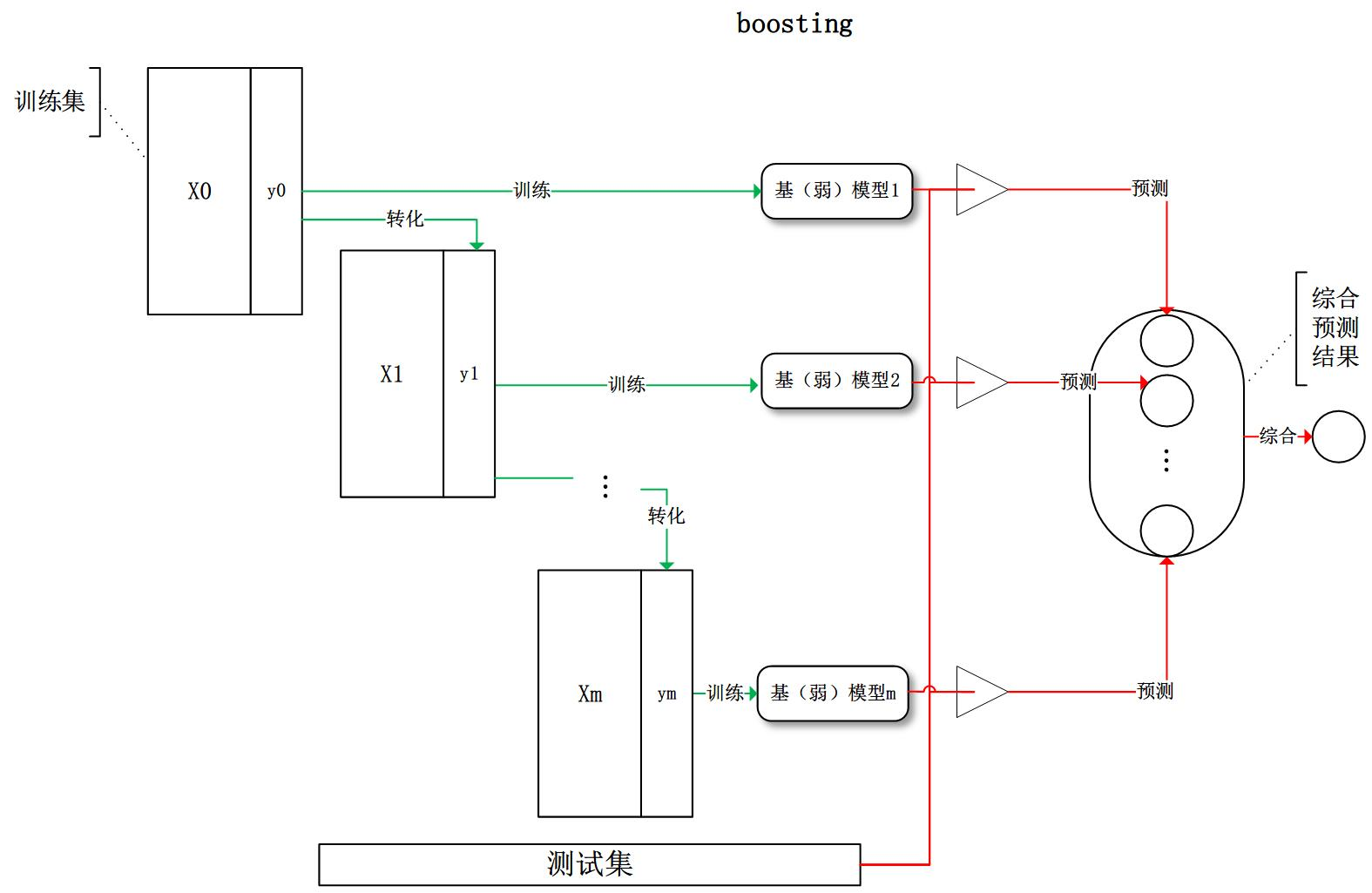
boosting可以用来提高其他弱分类算法的识别率,也就是将其他的弱分类算法作为基分类算法放于Boosting 框架中,通过Boosting框架对训练样本集的操作,得到不同的训练样本子集,用该样本子集去训练生成基分类器;
每得到一个样本集就用该基分类算法在该样本集上产生一个基分类器,这样在给定训练轮数 n 后,就可产生 n 个基分类器,然后Boosting框架算法将这 n个基分类器进行加权融合,产生一个最后的结果分类器,在这 n个基分类器中,每个单个的分类器的识别率不一定很高,但他们联合后的结果有很高的识别率,这样便提高了该弱分类算法的识别率。在产生单个的基分类器时可用相同的分类算法,也可用不同的分类算法,这些算法一般是不稳定的弱分类算法,如神经网络(BP) ,决策树(C4.5)等。
3.AdaBoost(自适应提升)
AdaBoost被称为是Boosting算法家族中的代表算法。曾被称为数据挖掘十大算法之一。
是由Yoav Freund和Robert Schapire在1995年提出。Adaboost是一种基于boost思想的一种自适应的迭代式算法。通过在同一个训练数据集上训练多个弱分类器(weak classifier), 然后把这一组弱分类器ensmble起来, 产生一个强分类器(strong classifier)。可以说是一个meta algorithms。
AdaBoost 的自适应在于:前一个基本分类器分错的样本会得到加强,加权后的全体样本再次被用来训练下一个基本分类器。同时,在每一轮中加入一个新的弱分类器,直到达到某个预定的足够小的错误率或达到预先指定的最大迭代次数
整个Adaboost 迭代算法就3步:
- 初始化训练数据的权值分布。如果有N个样本,则每一个训练样本最开始时都被赋予相同的权值:1/N。
- 训练弱分类器。具体训练过程中,如果某个样本点已经被准确地分类,那么在构造下一个训练集中,它的权值就被降低;相反,如果某个样本点没有被准确地分类,那么它的权值就得到提高。然后,权值更新过的样本集被用于训练下一个分类器,整个训练过程如此迭代地进行下去。
- 将各个训练得到的弱分类器组合成强分类器。各个弱分类器的训练过程结束后,加大分类误差率小的弱分类器的权重,使其在最终的分类函数中起着较大的决定作用,而降低分类误差率大的弱分类器的权重,使其在最终的分类函数中起着较小的决定作用。换言之,误差率低的弱分类器在最终分类器中占的权重较大,否则较小。
该算法的优点如下:
(1) 具有较低的泛化误差(low generalization)
(2) 改善了分类器的分类正确率
(3) 可以将这个算法配合多个分类算法使用。 例如, 我们可以选择C4.5, CART, SVM, 贝叶斯分类器, 或者decision stump等作为我们的弱分类器。
(4)容易coding
(5)不容易出现overfiting(过拟合)现象
缺点如下:
对outliers(异常点)非常的sensitive。 因为异常点容易分错, 会逐级影响后面的产生的弱分类器。
Adaboost每一轮迭代的时候都会训练一个新的弱分类器。 直至达到某个预定的足够小的错误率。
二、提升树(boosting tree)
1.什么是提升树?
提升树是以 分类树 或 回归树 为基分类器。
提升方法实际采用加法模型(即基函数的线性组合)与前向分布算法。以决策树为基函数的提升方法称为提升树(boosting tree)。对分类问题决策树是二叉分类树,对回归问题决策树是二叉回归树。
创新点在于第一个回归树预测的效果可能一般,但是第二个回归树把第一个预测错的残差作为输入, 也就是说,如果第一个点的值被预测错误,那么在下一个回归树里面的模型的权值的就会变大,相当于吸取前一个模型的经验,从而提高模型的效果。
2.提升树模型
如果我们取一个基本分类器 if (x > 30) 1 else 0,这可以看做是由一个根节点直接连接两个叶结点的简单决策树,即所谓的决策树桩(decision stump)。提升树模型可以表示为决策树的加法模型。
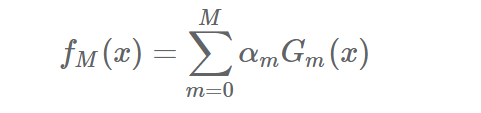
其中,T(x;θm)表示决策树;θm为决策树的参数;M为树的个数。
3.梯度提升算法(GBDT)
提升树利用加法模型与前向分步算法实现学习的优化过程,当损失函数是平方损失和指数损失函数时,每一步优化是很简单的。但对一般损失函数而言,往往每一步优化并不是那么容易。针对这一问题,Freidman提出了梯度提升(gradient boosting)算法。这是利用最速下降法的近似方法,器其关键是利用损失函数的负梯度在当前模型的值:
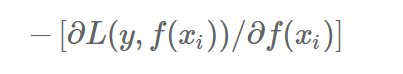
作为回归问题提升树算法中的残差的近似值,拟合一个回归树。
梯度提升算法:
输入:训练数据集T=(x1,y1),(x2,y2),…(xN,yN),xi∈X⊂Rn,yi∈y⊂R; 损失函数L(y, f(x));
输出:回归树f(x).
三、随机森林(Random Forest)
1.什么是bagging
前面在介绍集成学习的时候提到了集成学习的三大主要框架:
- bagging
- boosting
- stacking
Bagging框架算法 (英语:Bootstrap aggregating,引导聚集算法),又称装袋算法,是机器学习领域的一种团体学习算法。最初由Leo Breiman于1996年提出。Bagging算法可与其他分类、回归算法结合,提高其准确率、稳定性的同时,通过降低结果的方差,避免过拟合的发生。
2.什么是随机森林?
随机森林指的是利用多棵树对样本进行训练并预测的一种分类器,是在bagging基础上做了修改的一种算法。
基本思路是:
(1)从样本集中用Bootstrap采样(有放回的采样)选出n个样本(重采样);
(2)从所有属性中随机选择k个属性,选择最佳分割属性作为节点建立CART决策树;
(3)重复以上两步m次,即建立了m棵CART决策树;
(4)这m个CART形成随机森林,通过投票表决结果,决定数据属于哪一类随机性在于n个样本的随机,及其k个特征属性的选择,这两个随机。
随机森林的优点有 :
(1)对于很多种资料,它可以产生高准确度的分类器;
(2)它可以处理大量的输入变数;
(3)它可以在决定类别时,评估变数的重要性;
(4)在建造森林时,它可以在内部对于一般化后的误差产生不偏差的估计;
(5)它包含一个好方法可以估计遗失的资料,并且,如果有很大一部分的资料遗失,仍可以维持准确度;
(6)它提供一个实验方法,可以去侦测variable interactions;
(7)对于不平衡的分类资料集来说,它可以平衡误差;
(8)它计算各例中的亲近度,对于数据挖掘、侦测离群点(outlier)和将资料视觉化非常有用;
(9)使用上述。它可被延伸应用在未标记的资料上,这类资料通常是使用非监督式聚类。也可侦测偏离者和观看资料;
(10)学习过程是很快速的。
最后
以上就是甜美飞机最近收集整理的关于机器学习——Boosting、提升树、随机森林(Random Forest)学习笔记的全部内容,更多相关机器学习——Boosting、提升树、随机森林(Random内容请搜索靠谱客的其他文章。








发表评论 取消回复