目录
HOWTO: RTOS and RT Applications
Memory for Real-time Applications
HOWTO build a simple RT application
HOWTO build a basic cyclic application
HOWTO build a simple RT application with a locking mechanism
HOWTO build a simple RT application with a signaling mechanism
CPU idle power saving methods for real-time workloads
HOWTO: RTOS and RT Applications
https://wiki.linuxfoundation.org/realtime/documentation/howto/applications/start
Memory for Real-time Applications
https://wiki.linuxfoundation.org/realtime/documentation/howto/applications/memory
Proper handling of memory will improve a real-time application's deterministic behavior. Three areas of memory management within the purview of a real-time application are considered :
- Memory Locking
- Stack Memory for RT threads
- Dynamic memory allocation
Keep in mind that the usual sequence is for an application to begin its execution as a regular (non-RT) application, then create the RT threads with appropriate resources and scheduling parameters.
Memory Locking
Memory locking APIs allow an application to instruct the kernel to associate (some or all of its) virtual memory pages with real page frames and keep it that way. In other words :
-
Memory locking APIs will trigger the necessary page-faults, to bring in the pages being locked, to physical memory. Consequently first access to a locked-memory (following an
mlock*()call) will already have physical memory assigned and will not page fault (in RT-critical path). This removes the need to explicitly pre-fault these memory. -
Further memory locking prevents an application's memory pages, from being paged-out, anytime during its lifetime even in when the overall system is facing memory pressure.
Applications can either use mlock(…) or mlockall(…) for memory locking. Specifics of these C Library calls can be found here The GNU C Library: Locking pages. Note that these calls requires the application to have sufficient privileges (i.e. CAP_IPC_LOCK capability) to succeed.
While mlock(<addr>, <length>) locks specific pages (described by address and length), mlockall(…) locks an application's entire virtual address space (i.e globals, stack, heap, code) in physical memory. The trade-off between convenience and locking-up excess RAM should drive the choice of one over the other. Locking only those areas which are accessed by RT-threads (using mlock(…)) could be cheaper than blindly using mlockall(…) which will end-up locking all memory pages of the application (i.e. even those which are used only by non-RT threads).
The snippet below illustrates the usage of mlockall(…) :
/* Lock all current and future pages from preventing of being paged to swap */
if (mlockall( MCL_CURRENT | MCL_FUTURE )) {
perror("mlockall failed");
/* exit(-1) or do error handling */
}Real-time applications should use memory-locking APIs early in their life, prior to performing real-time activities, so as to not incur page-faults in RT critical path. Failing to do so may significantly impact the determinism of the application.
Note that memory locking is required irrespective of whether swap area is configured for a system or not. This is because pages for read-only memory areas (like program code) could be dropped from the memory, when the system is facing memory pressure. Such read-only pages (being identical to on-disk copy), would be brought back straight from the disk (and not swap), resulting in page-faults even on setups without a swap-memory.
Stack Memory for RT threads
All threads (RT and non-RT) within an application have their own private stack. It is recommended that an application should understand the stack size needs for its RT threads and set them explicitly before spawning them. This can be done via the pthread_attr_setstacksize(…) call as shown in the snippet below. If the size is not explicitly set, then the thread gets the default stack size (pthread_attr_getstacksize() can be used to find out how much this is, it was 8MB at the time of this writing).
Aforementioned mlockall(…) is sufficient to pin the entire thread stack in RAM, so that pagefaults are not incurred while the thread stack is being used. If the application spawns a large number of RT threads, it is advisable to specify a smaller stack size (than the default) in the interest of not exhausting memory.
static void create_rt_thread(void)
{
pthread_t thread;
pthread_attr_t attr;
/* init to default values */
if (pthread_attr_init(&attr))
error(1);
/* Set a specific stack size */
if (pthread_attr_setstacksize(&attr, PTHREAD_STACK_MIN + MY_STACK_SIZE))
error(2);
/* And finally start the actual thread */
pthread_create(&thread, &attr, rt_func, NULL);
}Details: The entire stack of every thread inside the application is forced to RAM when mlockall(MCL_CURRENT) is called. Threads created after a call to mlockall(MCL_CURRENT | MCL_FUTURE) will generate page faults immediately (on creation), as the new stack is immediately forced to RAM (due to the MCL_FUTURE flag). So all RT threads need to be created at startup time, before the RT show time. With mlockall(…) no explicit additional prefaulting necessary to avoid pagefaults during first (or subsequent) access.
Dynamic memory allocation in RT threads
Real-time threads should avoid doing dynamic memory allocation / freeing while in RT critical path. The suggested recommendation for real-time threads, is to do the allocations, prior-to entering RT critical path. Subsequently RT threads, within their RT-critical path, can use this pre-allocated dynamic memory, provided that it is locked as described here.
Non RT-threads within the applications have no restrictions on dynamic allocation / free.
HOWTO build a simple RT application
https://wiki.linuxfoundation.org/realtime/documentation/howto/applications/application_base
The POSIX API forms the basis of real-time applications running under PREEMPT_RT. For the real-time thread a POSIX thread is used (pthread). Every real-time application needs proper handling in several basic areas like scheduling, priority, memory locking and stack prefaulting.
Basic prerequisites
Three basic prerequisites are introduced in the next subsections, followed by a short example illustrating those aspects.
Scheduling and priority
The scheduling policy as well as the priority must be set by the application explicitly. There are two possibilities for this:
-
Using
sched_setscheduler()
This funcion needs to be called in the start routine of the pthread before calculating RT specific stuff. -
Using pthread attributes
The functionspthread_attr_setschedpolicy()andpthread_attr_setschedparam()offer the interfaces to set policy and priority. Furthermore scheduler inheritance needs to be set properly to PTHREAD_EXPLICIT_SCHED by usingpthread_attr_setinheritsched(). This forces the new thread to use the policy and priority specified by the pthread attributes and not to use the inherit scheduling of the thread which created the real-time thread.
Memory locking
See here
Stack for RT thread
See here
Example
/*
* POSIX Real Time Example
* using a single pthread as RT thread
*/
#include <limits.h>
#include <pthread.h>
#include <sched.h>
#include <stdio.h>
#include <stdlib.h>
#include <sys/mman.h>
void *thread_func(void *data)
{
/* Do RT specific stuff here */
return NULL;
}
int main(int argc, char* argv[])
{
struct sched_param param;
pthread_attr_t attr;
pthread_t thread;
int ret;
/* Lock memory */
if(mlockall(MCL_CURRENT|MCL_FUTURE) == -1) {
printf("mlockall failed: %mn");
exit(-2);
}
/* Initialize pthread attributes (default values) */
ret = pthread_attr_init(&attr);
if (ret) {
printf("init pthread attributes failedn");
goto out;
}
/* Set a specific stack size */
ret = pthread_attr_setstacksize(&attr, PTHREAD_STACK_MIN);
if (ret) {
printf("pthread setstacksize failedn");
goto out;
}
/* Set scheduler policy and priority of pthread */
ret = pthread_attr_setschedpolicy(&attr, SCHED_FIFO);
if (ret) {
printf("pthread setschedpolicy failedn");
goto out;
}
param.sched_priority = 80;
ret = pthread_attr_setschedparam(&attr, ¶m);
if (ret) {
printf("pthread setschedparam failedn");
goto out;
}
/* Use scheduling parameters of attr */
ret = pthread_attr_setinheritsched(&attr, PTHREAD_EXPLICIT_SCHED);
if (ret) {
printf("pthread setinheritsched failedn");
goto out;
}
/* Create a pthread with specified attributes */
ret = pthread_create(&thread, &attr, thread_func, NULL);
if (ret) {
printf("create pthread failedn");
goto out;
}
/* Join the thread and wait until it is done */
ret = pthread_join(thread, NULL);
if (ret)
printf("join pthread failed: %mn");
out:
return ret;
}
HOWTO build a basic cyclic application
https://wiki.linuxfoundation.org/realtime/documentation/howto/applications/cyclic
The cyclic RT task will use the basic application task which was built in the previous section (HOWTO build a simple RT application).
Cyclic Task
A cyclic task is one which is repeated after a fixed period of time like reading sensor data every 100 ms. The execution time for the cyclic task should always be less than the period of the task. Following are the mechanisms which we will be looking at for implementing cyclic task:
-
nanosleep
-
EDF Scheduling
Current Time
There are multiple ways to get current time – gettimeofday, time, clock_gettime, and some other processor specific implementations. Some of them, like gettimeofday, will get time from the system clock. The system clock can be modified by other processes. Which means that the clock can go back in time. clock_gettime with CLOCK_MONOTONIC clock can be used to avoid this problem. CLOCK_MONOTONIC argument ensures that we get a nonsettable monotonically increasing clock that measures time from some unspecified point in the past that does not change after system startup[1]. It is also important to ensure we do not waste a lot of CPU cycles to get the current time. CPU specific implementations to get the current time will be helpful here.
Basic Stub
Any mechanism for implementing a cyclic task can be divided into the following parts:
-
periodic_task_init(): Initialization code for doing things like requesting timers, initializing variables, setting timer periods.
-
do_rt_task(): The real time task is done here.
-
wait_rest_of_period(): After the task is done, wait for the rest of the period. The assumption here is the task requires less time to complete compared to the period length.
-
struct period_info: This is a struct which will be used to pass around data required by the above mentioned functions.
The stub for the real time task will look like:
void *simple_cyclic_task(void *data)
{
struct period_info pinfo;
periodic_task_init(&pinfo);
while (1) {
do_rt_task();
wait_rest_of_period(&pinfo);
}
return NULL;
}Examples
clock_nanosleep
clock_nanosleep() is used to ask the process to sleep for certain amount of time. nanosleep() can also be used to sleep. But, nanosleep() uses CLOCK_REALTIME which can be changed by another processes and hence can be discontinuous or jump back in time. In clock_nanosleep, CLOCK_MONOTONIC is explicitly specified. This is a immutable clock which does not change after startup. The periodicity is achieved by using absolute time to specify the end of each period. More information on clock_nanosleep at http://man7.org/linux/man-pages/man2/clock_nanosleep.2.html
struct period_info {
struct timespec next_period;
long period_ns;
};
static void inc_period(struct period_info *pinfo)
{
pinfo->next_period.tv_nsec += pinfo->period_ns;
while (pinfo->next_period.tv_nsec >= 1000000000) {
/* timespec nsec overflow */
pinfo->next_period.tv_sec++;
pinfo->next_period.tv_nsec -= 1000000000;
}
}
static void periodic_task_init(struct period_info *pinfo)
{
/* for simplicity, hardcoding a 1ms period */
pinfo->period_ns = 1000000;
clock_gettime(CLOCK_MONOTONIC, &(pinfo->next_period));
}
static void do_rt_task()
{
/* Do RT stuff here. */
}
static void wait_rest_of_period(struct period_info *pinfo)
{
inc_period(pinfo);
/* for simplicity, ignoring possibilities of signal wakes */
clock_nanosleep(CLOCK_MONOTONIC, TIMER_ABSTIME, &pinfo->next_period, NULL);
}EDF Scheduler
Recently, earliest deadline first scheduling algorithm has been merged in the mainline kernel. Now, users can specify runtime, period and deadline of a task and they scheduler will run the task every specified period and will make sure the deadline is met. The scheduler will also let user know if the tasks(or a set of tasks) cannot be scheduled because the deadline won't be met.
More information about the EDF scheduler including an example of implementation can be found at: https://www.kernel.org/doc/Documentation/scheduler/sched-deadline.txt(本站地址:https://rtoax.blog.csdn.net/article/details/113730130)
HOWTO build a simple RT application with a locking mechanism
https://wiki.linuxfoundation.org/realtime/documentation/howto/applications/locking
HOWTO build a simple RT application with a signaling mechanism
https://wiki.linuxfoundation.org/realtime/documentation/howto/applications/signal
CPU idle power saving methods for real-time workloads
https://wiki.linuxfoundation.org/realtime/documentation/howto/applications/cpuidle
Most configurations created for real-time applications disable power management completely to avoid any impact on latency. It is, however, possible to enable power management to a degree to which the impact on latency is tolerable based on application requirements. This document addresses how CPU idle states can be enabled and tuned to allow power savings while running real-time applications.
CPU idle states and their impact on latencies
A CPU idle state is a hardware feature to save power while the CPU is doing nothing. Different architectures support different types of CPU idle states. They vary in the degree of power savings, target residency and exit latency. Target residency is the amount of time the CPU needs to be in that idle state to justify the power consumed to enter and exit that state. Exit latency is the time the hardware takes to exit from that idle state.
CPU idle states in Intel CPUs are referred to as C states. Each C state has a name, starting from C0 until the maximum number of C states supported. C states are generally per core; however, a package can also enter a C state when all cores in the package enter a certain C state. The CPU is in C0 when it is fully active and is put into any of the other C states when the kernel becomes idle.
C states with higher numbers are referred to as “deeper C states.” These states save more power but also have higher exit latencies. Typically the deeper the idle state, the more components are either turned off or voltage reduced. Turning these components back on when the CPU wakes up from the deeper C states takes time. These delays can also vary depending on differences in platform components, kernel configurations, devices running, kernel operations around wake, state of caches and TLBs. Also the kernel must lock interrupts to synchronize the turning on of components, clocks and updating the state of the scheduler. The delays can vary a lot.
The following sections discuss how we can tune the system so that we can limit the power saving capabilities to the point where these variable latencies (jitter) are contained within the tolerance of the real-time application design.
Configurations to guard critical cores from interference
It would help to understand some basic configurations used in a real-time application environment to help reduce interference into the cores that run the real-time applications. These configurations are done in kernel boot parameters. Real-time applications can be run in “mixed mode” where some cores run real-time applications referred to as “critical cores” while other cores run regular tasks. If not running in mixed mode then all the cores would be running real-time applications and some of the configurations discussed below may not be necessary.
Detailed documentation of kernel parameters can be found at https://www.kernel.org/doc/Documentation/admin-guide/kernel-parameters.txt
isolcpus= cpu list. Give the list of critical cores. This will isolate the critical cores so that the kernel scheduler will not migrate tasks from other cores into them.
irqaffinity=cpu list. Give list of non-critical cores. This will protect the critical cores from IRQs.
rcu_nocbs=cpu list. Give the list of critical cores. This stops RCU callbacks from getting called into the critical cores.
nohz=off. The kernel's “dynamic ticks” mode of managing scheduling-clock ticks is known to impact latencies while exiting CPU idle states. This option turns that mode off. Refer to https://www.kernel.org/doc/Documentation/timers/NO_HZ.txt for more information about this setting.
nohz_full=cpu list. Give the list of critical cores. This will enable “adaptive ticks” mode of managing scheduling-clock ticks. The cores in the list will not get scheduling-clock ticks if there is only a single task running or if the core is idle. The kernel should be built with either the CONFIG_NO_HZ_FULL_ALL or CONFIG_NO_HZ_FULL options enabled.
Power Management Quality of Service (PM QoS)
PM QoS is an infrastructure in the kernel that can be used to fine tune the CPU idle system governance to select idle states that are below a latency tolerance threshold. It has both a user level and kernel level interface. It can be used to limit C states in all CPUs system wide or per core. The following sections explain the user level interface. A detailed description of PM QoS can be found at https://www.kernel.org/doc/Documentation/power/pm_qos_interface.txt.
Specifying system wide latency tolerance
You can specify system wide latency tolerance by writing a latency tolerance value in micro seconds into /dev/cpu_dma_latency. A value of 0 means disable C states completely. An application can write a limitation during critical operations and then restore to default value by closing the file handle to that entry.
Example setting system wide latency tolerance:
s32_t latency = 0;
fd = open("/dev/cpu_dma_latency", O_RDWR);
/* disable C states */
write(fd, &latency, sizeof(latency));
/* do critical operations */
/* Closing fd will restore default value */
close(fd);Specifying per-core latency tolerance
You can specify the latency tolerance of each core by writing the latency tolerance value into /sys/devices/system/cpu/cpu<cpu number>/power/pm_qos_resume_latency_us. The cpuidle governor compares this value with the exit latency of each C state and selects the ones that meet the latency requirement. A value of “0” means “no restriction” and a value of “n/a” means disable all C states for that core.
Example setting per-core latency tolerance from command line:
To disable all CPU idle states in CPU 3:
$echo “n/a” > /sys/devices/system/cpu/cpu3/power/pm_qos_resume_latency_usTo limit latency to 20 us:
$echo 20 > /sys/devices/system/cpu/cpu3/power/pm_qos_resume_latency_usTo remove all restrictions or revert to default:
$echo 0 > /sys/devices/system/cpu/cpu3/power/pm_qos_resume_latency_usExample setting per-core latency tolerance from application:
char latency_str[10];
fd = open("/sys/devices/system/cpu/cpu3/power/pm_qos_resume_latency_us", O_RDWR);
/* disable C states */
strcpy(latency_str, “n/a”);
write(fd, &latency, sizeof(latency));
/* do critical operations */
/* revert to “no restriction” */
strcpy(latency_str, “0”);
write(fd, &latency, sizeof(latency));
/* set latency tolerance to 20us */
sprintf(latency_str, “%d”, 20);
write(fd, &latency, sizeof(latency));
/* do operations tolerant of 20us latency */Note: The per-core user interface was changed in version 4.16. Current RT Linux is 4.14. Pull in commits 704d2ce, 0759e80 and c523c68 from 4.16.
Tools used to measure latencies
Cyclictest is used to measure the latencies while turbostat is used to identify the C states that are selected and their residencies.
A detailed description of cyclictest options can be found at http://manpages.ubuntu.com/manpages/precise/man8/cyclictest.8.html
https://wiki.linuxfoundation.org/realtime/documentation/howto/tools/cyclictest
Some parameters are discussed below
-a – Set affinity to CPU running real-time workload
-n – Use clock_nanosleep instead of posix interval timers
-h or –H – generate histogram. Takes a parameter to limit maximum latency to be captured
-t – number of threads to use
-p – priority of thread
-i – interval in microseconds. This is the time the application is idle between operations.
-m – locks memory locations preventing paging out
-D – duration to run the test.
–laptop – cyclictest by default disables all C states using PM QoS. This option will stop it from doing that.
Cyclictest will be used in the tuning methods described below. The first tuning method uses PM QoS to specify a latency tolerance. The second tuning method uses the “i” option of cyclictest to modify the interval to control the CPU idle state selection.
Tuning the latency using PM QoS
As explained above, you can use PM QoS to control the type of CPU idle states that the kernel selects when it goes to idle. The cpuidle governor compares the latency tolerance value registered through PM QoS with the hardware exit latencies of each CPU idle state and picks the one that meets the latency requirement.
Run cyclictest with the histogram option, and check the histogram for tolerable variations in the latency. Also check the other outputs such as maximum and average latencies to verify that they meet the requirements of the application.
If the histogram and the latency values do not meet the application requirements, reduce the PM QoS per-core latency tolerance value for the critical cores. Repeat this process until the results from cyclictest meet the application requirements.
Tuning the latency by adjusting application idle time
This section explains the tuning of CPU idle state selection by adjusting the interval for which the application goes to idle.
Each CPU idle state has a target residency value associated with it. Entering and exiting a CPU idle state consumes some power. The target residency of the CPU idle state is the amount of time in micro seconds that the CPU must be in idle to save enough power to justify the power consumed by entering and exiting that state. The cpuidle governor in the kernel compares the time the CPU is predicted to stay idle with the target residency of the different CPU idle states. It then picks the one that has a target residency less than the predicted idle time. The predicted idle time is the time when no task is scheduled to run in that CPU.
You can design your application to never be idle for more than the interval that would allow deeper CPU idle states with latency variations that are more than the latency tolerance of the application. This method first determines the maximum interval before the latency variations exceed the latency tolerance threshold.
This can be done by running cyclictest with different values for “i” (interval) parameter and checking the histogram and latency results. For example, run cyclictest with an interval value of 1000 us and then check cyclictest results. If they are not acceptable then decrease the value until an acceptable histogram and latency results are reached.
Tuning example
This example uses an Intel® NUC kit with Intel® Celeron® Processor J3455.
«Tests document performance of components on a particular test, in specific systems. Differences in hardware, software, or configuration will affect actual performance. Performance varies depending on system configuration.»
CPU 3 is the critical core running real-time workloads. It is isolated and protected as described above.
At each point we can use turbostat to check the C states used in a CPU as follows:
$turbostat --debug
Core CPU Avg_MHz Busy% Bzy_MHz TSC_MHz IRQ SMI CPU%c1 CPU%c3 CPU%c6 CPU%c7
- - 74 13.22 561 1498 20123 0 3.67 0.00 83.11 0.00
0 0 78 13.76 567 1498 5051 0 3.79 0.00 82.46 0.00
1 1 78 13.56 572 1498 5039 0 3.63 0.00 82.80 0.00
2 2 75 13.42 559 1498 5030 0 3.70 0.00 82.89 0.00
3 3 66 12.13 543 1498 5003 0 3.58 0.00 84.29 0.00Calibrate worst case latency
Set PM QoS resume latency constraint to 0 (“no restrictions”). Run cyclictest with a high interval and capture histogram data in a file.
$cyclictest -a3 -n -q -H1000 -t4 -p80 -i200 -m -D5m --laptopGenerate a graph from the histogram data using any graphing tool, for example, gnuplot.
The following example graph shows very high jitter:
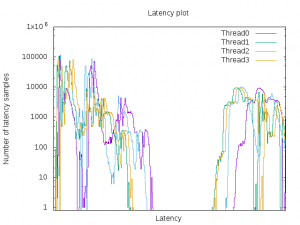
«Tests document performance of components on a particular test, in specific systems. Differences in hardware, software, or configuration will affect actual performance. Performance varies depending on system configuration.»
Note the maximum latency in this run for use in strategies to save more power discussed below. This would be the worst-case scenario that the application would take into consideration when it has idle times longer than this time and can decide to reduce restrictions saving more power.
Calibrate PM QoS resume latency constraint
Try some latency constraint values until a desired jitter level is reached. For the purpose of this demonstration, we will specify 49 us as a latency constraint to PM QoS.
$echo 49 > /sys/devices/system/cpu/cpu3/power/pm_qos_resume_latency_us
$cyclictest -a3 -n -q -H1000 -t4 -p80 -i200 -m -D5m --laptop
$echo 0 > /sys/devices/system/cpu/cpu3/power/pm_qos_resume_latency_us (Revert back to "no restriction" when done)Following is the graph generated from the histogram:
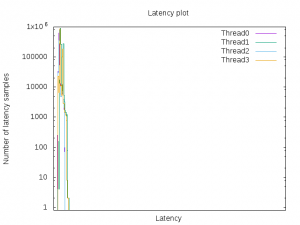
«Tests document performance of components on a particular test, in specific systems. Differences in hardware, software, or configuration will affect actual performance. Performance varies depending on system configuration.»
Cyclictest latency results and the histogram show that the latencies are not varying. Assuming this is the acceptable jitter level of the application, it should specify the corresponding PM QoS latency constraint value during critical operations and at other times remove the restriction to save more power.
Calibrate idle interval
For the purpose of demonstration, this example sets the maximum sleep time of the workload to 100 us. Only CPU idle states with target residency less than that will be allowed.
Note that the PM QoS latency tolerance value was reverted to “no restriction” for this run.
$cyclictest -a3 -n -q -H1000 -t4 -p80 -i100 -m -D5m --laptopFollowing is the graph generated from the histogram:
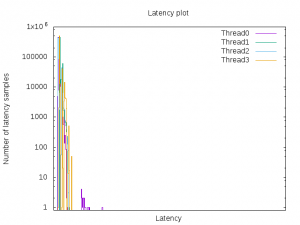
«Tests document performance of components on a particular test, in specific systems. Differences in hardware, software, or configuration will affect actual performance. Performance varies depending on system configuration.»
Latency results and histogram show that the latency impact is reduced compared to the initial run. If this jitter level is acceptable, the application should use the corresponding interval as the maximum time to idle during critical phases.
Conclusion
Using the PM QoS method, the application specifies a PM QoS resume latency constraint that ensures jitter stays within the maximum tolerance level of the application. To save more power, it reverts back to “no restriction” when there are no critical operations to be done.
In the idle interval method, the application uses the calibrated safe idle interval as the maximum period that it will idle at a time during critical phases. If it needs to idle for longer periods, it will make sure that the idle period before the deadline will not exceed safe idle interval size. It would take into consideration the worst-case maximum latency that was found in the “no restriction” run.
As an example, let us assume the worst case latency is 400 us and the safe idle interval is 100 us. If the application is waiting for 1000 us, it will wake up early enough before reaching the deadline to make sure there is room for the worst-case latency. In this example, it would need to keep a buffer of 400 us before reaching the 1000 us deadline. First it would wait for 600 us (1000 - 400). Once woken, it would check how much time is left to reach the deadline. It will sleep in chunks of 100 us or less for the remaining time to block C states with target residencies higher than the calibrated safe idle interval.
In the same example, if PM QoS method is used, then the application can increase the restriction in PM QoS during the critical phase (400 us before the deadline) and wait for the remaining time.
An application can optimize power saving during long idle times by reducing the restriction and allowing more power to be saved when it can. It can also save power while performing non-critical operations. A combination of the PM QoS and idle interval methods will facilitate different strategies to save power without compromising the application's real-time constraints.
Strategies for effective power savings considering CPU topology and caching behavior
CPU topology plays an important role on how the processor utilizes the power saving capabilities of the different C states. Processors have multiple cores and the operating system groups logical CPUs within each core. Each of these groupings has shared resources that can be turned off only when all the processing units in that group reach a certain C state. If one logical CPU in a core can enter a deep C state but other logical CPUs are still running or at a lesser power saving C state, the CPU that can enter the deep state will be held at a less power saving state. This is because if the shared resources are turned off, then the other CPUs that are still running, will not be able to run. The same applies to package C states. A package can enter a deep C state only when all the cores in that package enter a certain deep C state, when the package level components can be turned off.
When designing a multi-core real-time application, assign tasks to a cluster of cores that can go idle at the same time. This may require some static configuration and knowledge of processor topology. Tools like turbostat can be used to get an idea of the groupings.
Another area to consider is cache optimization. Deeper C states would cause caches and TLBs to be flushed. Upon resume, the caches need to be reloaded for optimal performance. This reloading can cause latencies at places where it was not expected based on earlier calibrations. This can be avoided by adding logic in the methods described above to also force the cache to get repopulated by critical memory regions. As the application wakes up from deeper C states earlier than the approaching critical phase, it can access the memory regions it would need to reference in the critical phase, forcing them to get reloaded in the cache. This cache repopulating technique can be incorporated into any general cache optimization scheme the real-time application may be using. The technique applies not only to C states but also to any situation where the cache must be repopulated.
Reference
Kernel parameters: https://www.kernel.org/doc/Documentation/admin-guide/kernel-parameters.txt
Kernel scheduling ticks: https://www.kernel.org/doc/Documentation/timers/NO_HZ.txt
PM QoS: https://www.kernel.org/doc/Documentation/power/pm_qos_interface.txt
Cyclictest: https://wiki.linuxfoundation.org/realtime/documentation/howto/tools/cyclictest
Reducing OS jitter: https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/tree/Documentation/kernel-per-CPU-kthreads.txt?h=v4.14-rc2
Good reference for C states: https://books.google.com/books?id=DFAnCgAAQBAJ&pg=PA177&lpg=PA177&dq=c+state+latency+MSR&source=bl&ots=NLTLrtN4JJ&sig=1ReyBgj1Ej0_m6r6O8wShEtK4FU&hl=en&sa=X&ved=0ahUKEwifn4yI08vZAhUFwVQKHW1nDgIQ6AEIZzAH#v=onepage&q=c%20state%20latency%20MSR&f=false
最后
以上就是神勇小懒猪最近收集整理的关于The Real Time Linux and RT Applications | PREEMPT_RTHOWTO: RTOS and RT ApplicationsMemory for Real-time ApplicationsHOWTO build a simple RT applicationHOWTO build a basic cyclic applicationHOWTO build a simple RT application with a locking mechanism的全部内容,更多相关The内容请搜索靠谱客的其他文章。








发表评论 取消回复