
你和“懂AI”之间,只差了一篇论文
很多读者给芯君后台留言,说看多了相对简单的AI科普和AI方法论,想看点有深度、有厚度、有眼界……以及重口味的专业论文。
为此,在多位AI领域的专家学者的帮助下,我们解读翻译了一组顶会论文。每一篇论文翻译校对完成,芯君和编辑部的老师们都会一起笑到崩溃,当然有的论文我们看得抱头痛哭。
同学们现在看不看得懂没关系,但芯君敢保证,你终有一天会因此爱上一个AI的新世界。
读芯术读者论文交流群,请加小编微信号:zhizhizhuji。等你。
这是读芯术解读的第142篇论文
KDD 2019
DuerQuiz:一个面向智能招聘笔试、面试的个性化试题推荐系统
DuerQuiz: A Personalized QuestionRecommender System for Intelligent Job Interview
中国科学技术大学、百度
本文是中国科学技术大学和百度TIC联合发表于KDD2019的工作,文章提出一种个性化智能工作笔试、面试的试题推荐系统。为此,我们首先提出一种技能图构建的方法,主要包含技能实体抽取、技能实体降噪以及技能上下位关系抽取三个部分。随后我们提出一种基于历史招聘数据下的一种启发式个性化试题推荐方法。实验结果表明我们的系统可以在招聘环节中有效的选取人才。


1. 引言
人才招聘对于企业能否保持竞争优势至关重要,并且会直接影响企业的成功。为了招募合适的人才,笔试、面试有助于评估候选人与职位需求相关的技能和经验。但是,以合适高效的方式评估人才是一项艰巨的任务,糟糕的招聘决策会浪费公司大量的时间和金钱。例如,如美国一篇HR专业报道的那样,如今的公司要雇用合适的人才平均要支付4129美元,而工作面试的过程通常需要24天左右。因此,在过去的几十年中,人们在改善工作笔试、面试过程方面做出了巨大的努力,例如人际适合度评估,工作技能分析,面试官的安排和针对性评估。
但是,工作笔试、面试的关键挑战在于如何使用合适的问题,来全面评估被认为与个人和工作需求相关并具有代表性的能力。一方面,如果问题的设计通常侧重于基本的工作要求,就像传统候选人筛选的笔试情况一样,工作面试将不会有区分能力。例如,如果某位机器学习工程师岗位的申请者具有与深度学习相关的应用程序相关的丰富经验,则如果仅用基础机器学习基础算法或代码编程考核,去替代那些事实上确实和这个岗位很相关并且反应其个人经验的技能(例如,使用深度神经网络的经验),那么并不会有很好的区分性。另一方面,如果过多地关注与候选人的个人背景有关的问题,则考核可能会忽略工作的基本要求,从而无法确定出适合该职位的人才。因此,在设计试题时,应在工作要求和应聘者的经历之间取得平衡。
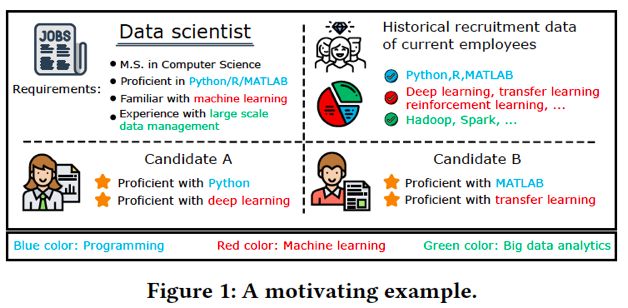
为此,在本文中,我们开发了一种新颖的个性化问题推荐系统DuerQuiz,以增强人才招聘中的工作笔试、面试评估。图1显示了我们的推荐系统的动机示例。可以看出,在数据科学家的职位描述中,分别有三个通用要求,分别是编程,机器学习和大数据分析。根据两位候选人的简历,他们在满足相应要求方面具有不同的个人技能背景。换句话说,候选人A精通Python和深度学习,而候选人B熟悉Matlab和迁移学习。因此,DuerQuiz的理想情况是可以基于候选人背景个性化地进行试题推荐。例如,对于应聘者1,DuerQuiz将推荐有关Python相关编程技巧和Deep Leaning相关机器学习模型的问题。同时,通过挖掘当前担任数据科学家职位的员工的历史招聘数据,我们认识到Hadoop和Spark是大数据分析的两个重要技能。在这种情况下,即使技能没有在简历中列出,DuerQuiz也会为两个候选人推荐相关的Hadoop和Spark问题。
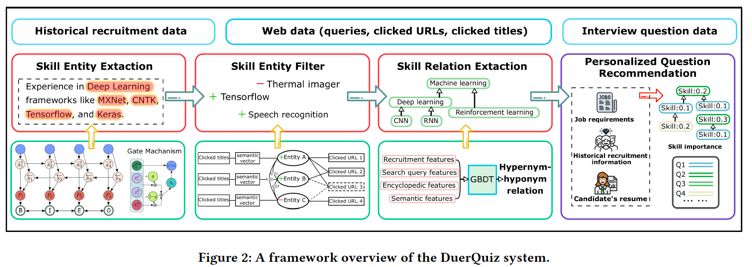
DuerQuiz的关键思想是构建工作技能的知识图,即Skill-Graph,以通过挖掘丰富的历史招聘数据和网络中可用的大规模工作技能数据,全面建模那些应在求职笔试、面试中进行评估的能力。具体来说,我们首先开发一种基于具有自适应门机制的双向LSTM-CRF神经网络的技能实体提取方法。特别地,为了提高提取的技能实体的可靠性,我们设计了一种基于实体-URL图上的标签传播方法,该实体-URL图是根据百度搜索引擎的查询日志中的点击数据构建的。此外,我们发现技能实体之间的上位词-下位词关系,并通过利用具有广泛上下文特征(例如招聘特征和搜索查询特征)训练的分类器来构建技能图。最后,我们提出了一种基于技能图的个性化问题推荐算法,以提高工作笔试、面试评估的效率和有效性。图2是DuerQuiz系统的一个示例图。
2. 模型框架
如图二所示,我们的系统主要分为技能图构建,即技能实体抽取、技能降噪与技能关系抽取,和个性化试题推荐组成。
2.1 技能实体抽取
要构建技能图,我们首先要从招聘数据(职位发布中的职位要求以及候选人简历中的工作/项目经验)中提取技能实体。例如,我们需要从职位需求文本“类似PaddlePaddle的深度学习框架中的经验”中提取技能Deep Learning和PaddlePaddle。在这里,我们依照基于名称实体识别的模型LSTM-CRF,来提取技能实体。此外,具有字符信息的基于字符的LSTM-CRF模型在没有显式词分隔符的语言(如中文和日语)上表现出比基于词的模型有更好的性能。因此,我们将基于字符的LSTM-CRF作为主要结构。另外,我们还将字符级别的bi-gram信息作为更好的字符表示的输入。
具体地,给定输入句子X,即职位发布中的工作要求或应聘者简历中的工作/项目经验描述,我们将上述三个元素信息(即字符、单词和字符的bi-gram)全部考虑在内。在这里,我们用{c1,c2,...,cn}表示X的字符序列,{b1,b2,..., bn}表示字符的bi-gram序列,其中bi= cici + 1。为了收集单词信息,我们首先使用中文分词器将X拆分为m个单词,即{w1,w2,...,wm}。同时,为了使单词序列的长度与字符序列对齐,表示为{w'1,w'2,...,w'n}。我们计算三类元素信息的表征为:
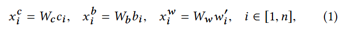
然后我们通过一个门结构控制字符级与词级别信息得到:
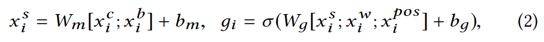
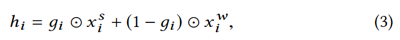
我们将其作为一个双向LSTM的输入,并引入一个标准的CRF层,他们的最后的预测标签为y= {y1,y2,...,yn},其中yi∈{I,O,B,E,S}表示当前字符是技能实体的Inside, Outside, Beginning, Ending 或 Singleton。我们有:
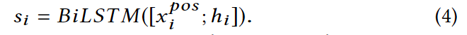
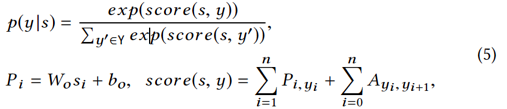
我们通过最大化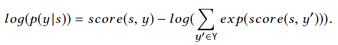 来进行模型的训练。
来进行模型的训练。
2.2 技能实体降噪
从招聘数据中提取技能实体后,我们获得了一组技能,表示为Ve = {v1e,…}。尽管技能实体抽取模型的表现良好,但在Ve中依旧不可避免的包含一些非技能词。为了解决这个问题,我们希望利用网络搜索数据(即点击日志(查询,单击的URL和标题))作为过滤实体的额外知识数据。受到之前研究者的启发,我们通过标记一部分的Ve(每个实体是否是真正的技能),设计一种基于标签传播(LP)的算法来对技能实体进行降噪。
具体来说,我们创建一个实体-url图G =(V,E)。节点集V包含两种节点,即实体Ve和包含在这些实体的查询日志中的点击URLs Vu = {vu}。边E的集合同样包括两个部分,即Eeu和Eee。具体来说,Eeu⊂Ve×Vu是Ve中的点与它们在Vu中的相应单击的URL之间的链接集。特别是,我们删除了在标记数据中同时连接了技能实体和非技能实体的URL的边,以减少实体节点和URL节点之间的噪音。我们用Weu∈Rpe×pu表示权重矩阵。并且,由于有些节点未连接Vu中的任何节点,因此我们在实体节点Ve之间定义了一组边Eee⊂Ve×Ve,以传播这些节点的信息。在这里,我们首先通过在点击的URL标题上训练主题模型,为每个实体节点生成主题向量。然后,我们可以计算一个高斯核矩阵S,其中每个元素si,j = exp {-||ti-tj||2/2σ2}。最后,我们仅在每个实体与其最接近的ke个节点之间创建边。对应的边集是Eee。我们定义权重矩阵Wee∈Rpe×pe,算法1显示了构造Eee的细节。

然后,我们通过基于LP的方法计算一个实体是否为技能的概率,如算法2所示。这里,将Y∈Rpe×2表示为实体标签。具体来说,当实体被标记为技能词时,我们设置对应的y0i,1= 1,如果实体被标记为非技能词,则设置y0i,0= 1。然后,我们计算如下两个归一化权重矩阵。
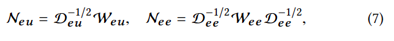
其中Deu和Dee是两个对角矩阵,其中每个元素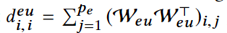 ,而
,而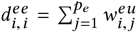 。然后,我们迭代地使用LP来更新Yeu,Yee∈Rpe×2,分别表示Weu和Wee所获实体标签的得分。对于第t次迭代,我们有:
。然后,我们迭代地使用LP来更新Yeu,Yee∈Rpe×2,分别表示Weu和Wee所获实体标签的得分。对于第t次迭代,我们有:
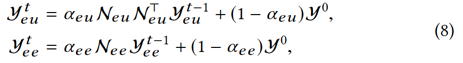
最后,在收敛之后,我们可以如下计算试题是否是技能实体的概率:
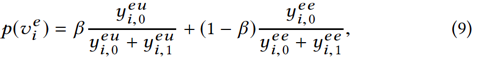

2.3 技能关系抽取
在技能实体提取和过滤过程之后,我们转向提取技能之间的关系,特别是上位词-下位词(“ is-a”)关系。例如,机器学习和强化学习技能具有特别是上位词-下位词的关系。该问题可以表述为分类问题,该分类问题用于确定技能对(vei,vej)是否为上位词-下位词。在这里,我们利用历史招聘数据、网络搜索日志数据和百科全书数据来构建特征,训练分类模型。
为了生成训练数据,我们受到Fu等人的想法启发,收集每个技能实体的候选上位词。具体来说,我们选择出现在成功应聘的岗位-简历对的共现技能对(职位发布中的需求的一项技能,候选人在简历描述中的另一项技能)和点击数据中的共现技能对(搜索查询中的一项技能和另一项技能)。
选择出现在历史成功应用程序中的同现技能(即,给定职位发布中的一项技能,以及候选人的相应简历中的另一项技能)和点击数据(即,搜索查询中的一项技能和点击链接的标题出现的另一个技能)作为候选的上位词。并且,我们手动标注了训练数据。训练分类模型的特征可以划分为四类,如下:
•招聘数据类特征:招聘数据,即岗位需求与其对应申请的简历数据中可以帮我们有效的提取上下位词的特征。通常,职位发布中的技能通常是简历中工作/项目经验中某些技能的上位词。例如,出现在工作要求中的机器学习技能是SVM和LDA的上位词,它们出现在相应的成功注册候选人的简历中。另外,技能对出现在相同的工作要求中,或者工作/项目经验也可能反映它们之间的关系。
•搜索查询日志特征:点击日志可以帮助我们了解技能之间的关系。例如,点击的URL标题中包含的技能将与检索到的技能词有很强的关联。此外,许多搜索查询和URL标题包含多种技能,也可以反映出它们之间的一些协作关系。
•百科知识特征:百科全书数据中包含有关实体关系的大量知识,可以提取出有效的特征。例如“百度百科”页面摘要中显示的技能可能与此技能具有上位词-下位词关系的描述。
在这里,我们使用GBDT作为分类器。在我们预测了技能词的所有上位词之后,我们可以使用所有上位词-下位词关系作为图中的有向边来构造技能图。并且我们基于Fu等人的方法去除掉一些较弱的边,避免形成有向环。
2.4 个性化试题推荐算法
最后,我们介绍利用技能图Gr进行面试问题推荐。我们首先收集一组面试问题,并将其与Gr技能进行手动关联。然后,对于一个申请(即给定了一对候选人的简历和申请的职位),我们利用候选人的简历文本,申请职位文本和历史招聘数据来寻找适合考查的技能,以及他们应该考察的权重。我们希望由我们的推荐算法产生的面试问题不仅可以涵盖工作的技能要求,而且可以同时考虑候选人背景。

给定岗位J,将当前岗位的员工们的简历表示为R={R1,…},并且我们还利用员工的工作表现表示为P = {P1,…},候选人的简历为S。我们首先根据技能图获得上述文本数据中包含的技能,将VJ,VRi和VS分别表示为J,Ri和S的技能集合。随后我们计算:
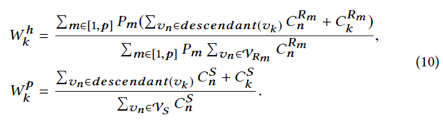
我们将所有技能分成三个部分:匹配的技能,个性化的技能和未匹配的技能,并分别计算其权重。此外,为解决冷启动问题,我们还考虑了仅出现在职位发布中但没有出现在历史招聘数据或应聘者简历中的技能。我们通过如下计算所有提取的技能的权重:
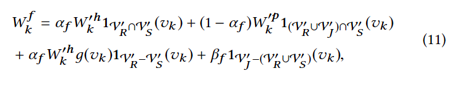
在标准化wfk为wf’k后,我们可以计算属于V’RUV’S的技能的孩子节点的权重为:
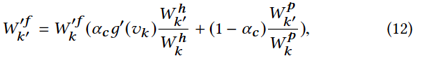
随后,我们通过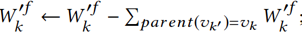 更新vk的权重。在生成推荐问题集时,对于每个vk,我们都会针对该技能生成W'fk·N个问题。并且,如果没有与vk关联的问题,我们将其权重添加到其父节点中,并进一步为父节点生成问题。具体的推荐算法由算法3给出。
更新vk的权重。在生成推荐问题集时,对于每个vk,我们都会针对该技能生成W'fk·N个问题。并且,如果没有与vk关联的问题,我们将其权重添加到其父节点中,并进一步为父节点生成问题。具体的推荐算法由算法3给出。
3. 实验
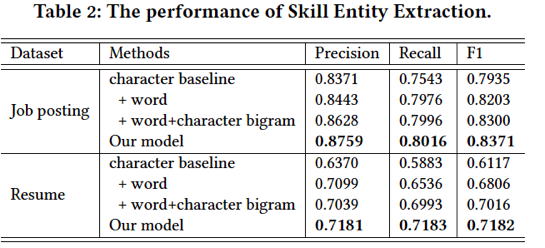
•技能实体抽取的效果:在这里,我们使用了历史招聘数据集来提取技能实体。为了训练我们的模型以及验证模型效果,我们手动在2,000个岗位需求和3,700个工作/项目经验中标记了技能实体。表2中显示了模型的总体表现,可以看出我们使用的三类信息(字符、单词、字符bi-gram)对建模技能实体抽取的有效性,以及门结构的有效性。
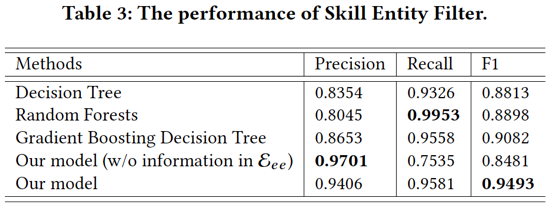
•技能实体降噪的效果:在这里,我们收集了2018年1月至2018年6月之间的点击数据,其中每个搜索查询都包含上述候选实体。删除噪声数据后,我们对查询进行了细分,并将其n-gram项与候选实体匹配。最终,我们获得了3.74亿个实体-url-标题三元组。我们手动标注了1416个技能实体与502个非技能实体。随机选择了60%的数据作为训练集,10%作为校验集合,30%作为测试集验证器性能。结果如表三所示,我们发现,缺少Eee导致测试集中20%的实体节点无法连接任何URL,因此无法对其进行预测。因此,尽管精度很高,但召回率仅为0.75。而利用Eee,我们提出的LP算法可以预测所有实体标签,并且与经典机器学习算法相比,获得最好的效果。
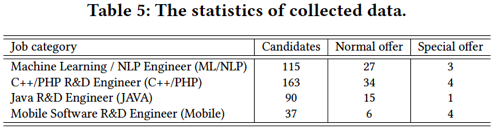
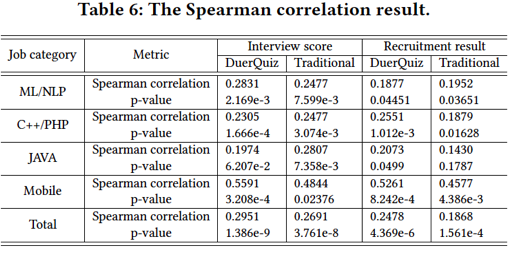
•试题推荐的效果: 我们在实际场景中评估我们的推荐系统。具体地,我们将其部署到了2018年的百度校招中。对于4类选定的岗位:机器学习/ NLP工程师,C ++ / PHP研发工程师,Java研发工程师和移动软件研发工程师,我们邀请应聘者参加我们由DuerQuiz系统生成的在线笔试练习。为了验证我们系统的性能,我们收集了他们的最终招聘结果以及他们在面试中的表现,包括我们的智能笔试,传统笔试和现场面试。表5显示数据的统计信息。
在这里,我们使用Spearman相关系数来衡量候选人的不同笔试评估方法与其招聘结果之间的相关性。具体来说,我们首先将最终的面试成绩映射为[0,8],最终的招聘结果分为三种类型:招聘失败,正常offer和special offer与分数0、1和2相对应。相关系数分析的结果如表6所示。根据结果,我们发现我们的DuerQuiz框架和传统笔试都与大多数工作岗位的面试结果、招聘结果显著相关。而且很多岗位中我们的智能笔试与传统考试相比具有更好的相关性,这表明DuerQuiz能很好的进行人才评估。
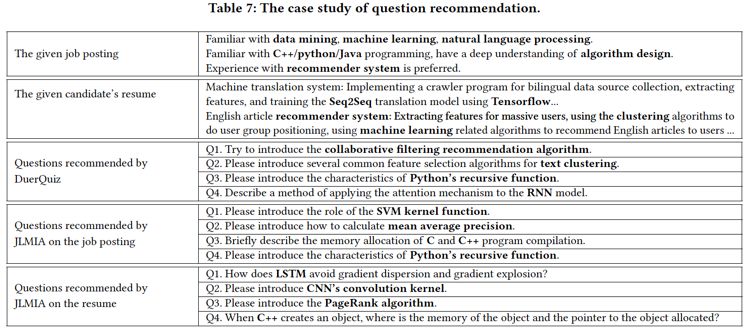
•案例分析: 为了进一步说明我们的DuerQuiz系统的有效性,表7展示了我们系统推荐的前4个问题的示例,以及一个最新的面试题推荐方法JLMIA [2],该方法通过在成功的工作面试记录中关于职位发布,候选人简历,面试评估文本中使用预先训练的概率主题模型来推荐面试问题。我们可以看到DuerQuiz推荐的问题涉及职位需求和应聘者简历中提到的技能。(Q1与推荐系统有关,Q2与聚类->机器学习有关,Q3与Python有关,Q4与RNN有关,其中“->”表示下位词-上位词关系。)同时,JLMIA模型不能很好的同时考察岗位需求和候选人简历信息。例如,JLMIA推荐了两个有关C ++和Python的问题,以匹配职位发布要求。但是,由于无法捕获候选人具有Python经验的事实,因此建议推荐C ++和Python相关的问题。
4. 总结
在本文中,我们介绍了一个个性化问题推荐系统DuerQuiz,用于人才招聘中的智能求职笔试、面试评估中。DuerQuiz的关键思想是通过挖掘历史招聘数据和从网络中获得的工作技能数据来构建工作技能的知识图。具体来说,我们首先基于双向LSTM-CRF神经网络设计了一种技能实体提取方法。然后基于点击日志数据设计了标签传播方法,以提高提取的技能实体的可靠性。此外,我们提出基于技能实体之间的上位词-下位词关系,构建技能图,并提出了一种启发式的个性化的问题推荐算法,以改善工作笔试、面试评估。最后,对现实世界的招聘数据进行的实验证明了DuerQuiz的有效性。其中,DuerQuiz被部署在2018年百度校园招聘活动中进行笔试试题推荐。


留言 点赞 发个朋友圈
我们一起分享AI学习与发展的干货

最后
以上就是靓丽鸵鸟最近收集整理的关于KDD 2019|DuerQuiz:一个面向智能招聘笔试、面试的个性化试题推荐系统1. 引言的全部内容,更多相关KDD内容请搜索靠谱客的其他文章。








发表评论 取消回复