Python预测基金净值:keras神经网络
- 如何搭建神经网络预测基金净值
- 一、时间窗口
- 二、爬基金数据,准备作为训练集、验证集、测试集
- 三、建模,读入数据,训练,验证
- 四、看图
- 总结
如何搭建神经网络预测基金净值
有一种观点:利用股票历史股价数据,搭建神经网络深度学习,预测股票未来走势,是外行人士的发神经。原因不外乎这些:首先,现有的量价指标等分析工具,远比仅研究历史股价数据靠谱;其次,涨停板的限制、新股N个涨停、停盘之后的补涨补跌等等,是股价历史数据自身无法解释和预测的;最后,不同股票差异太大,有人做出这种“归一化”:某日收盘价 / 历史最高收盘价,非常荒谬(应该采用每日涨跌幅)。
与此相反,搭建神经网络预测基金(指开放式基金)净值,则相对有意义:
1、股票的量价指标公式,通常不能用于基金分析(没有成交量)
2、基金本身并没有涨停板、停盘之类的干扰
3、基金的每日涨跌幅是现成的重要数据,可由基金每日净值简单计算
本文是上一篇《Python基金数据实战分析:偏债混合基金篇》的延续,沿用了其中的爬基金数据的方法(借鉴照搬了前人的经验)。此外,开发环境需安装keras(用tensorflow2.X自带的keras即可)。
关于keras,可参考:keras中文文档
一、时间窗口
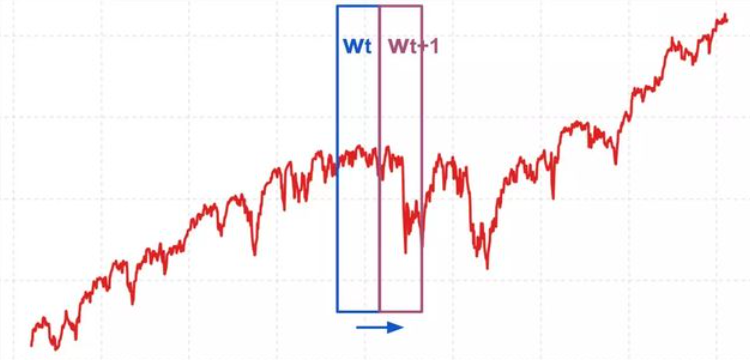
总长度为N的一系列数据,定义为p0,p1,…,pN-1,其中pi是第i天的数值,0≤i<N。 再定义一个固定大小的移动窗口w(实际上就是神经网络的input_size),该窗口大小的数据即是一个输入数据。
对于窗口数据,有不同的处理方法。主要有以下两种:
一、窗口不重叠
每次将窗口向右移动w个单位,使得所有移动窗口中的数据之间不重叠。用一个(或k+1个)移动窗口中的内容Wt来预测下一个Wt+1,亦即通过训练神经网络学习函数f,使得:Wt+1 = f(Wt),或Wt+1 = f(Wt, Wt-1, …, Wt-k)。这种方法可以预测窗口大小的未来日期的数值。
假定窗口大小3,用2个移动窗口预测下一个,那么训练样例如下:
Input1 = [[p0, p1, p2], [p3, p4, p5]], Label1 = [p6, p7, p8]
Input2 = [[p3, p4, p5], [p6, p7, p8]], Label2 = [p9, p10, p11]
…
二、窗口可重叠
每次将窗口向右移动1个单位(或多个单位),因此所有移动窗口中的数据之间可以重叠。用一个移动窗口中的内容Wt(即 ptw, ptw+1, …, p(t+1)w-1 )来预测下一个p(t+1)w,亦即通过训练神经网络学习函数f,使得:p(t+1)w = f(Wt)。这种方法可以预测下一天的数值。
假定窗口大小5,每次将窗口右移1个单位,那么训练样例如下:
Input1 = [[p0, p1, p2, p3, p4]], Label1 = [p5]
Input2 = [[p1, p2, p3, p4, p5]], Label2 = [p6]
…
神经网络模型可以用RNN(LSTM),也可以用普通的网络(CNN或全连接)。简单地说,普通网络不区分窗口内部的数据,而LSTM网络则越远的数据权重越小。本文先构造一个简单的2个隐藏层的全连接网络。
二、爬基金数据,准备作为训练集、验证集、测试集
import requests
import time
import execjs
fileTrain = './data/accTrain.csv'
jjTrain = ['004609', '004853', '005524', '005824', '007749']
fileTest = './data/accTest.csv'
jjTest = '007669'
def getUrl(fscode):
head = 'http://fund.eastmoney.com/pingzhongdata/'
tail = '.js?v='+ time.strftime("%Y%m%d%H%M%S",time.localtime())
return head+fscode+tail
# 根据基金代码获取净值
def getWorth(fscode):
content = requests.get(getUrl(fscode))
jsContent = execjs.compile(content.text)
#单位净值走势
netWorthTrend = jsContent.eval('Data_netWorthTrend')
#累计净值走势
ACWorthTrend = jsContent.eval('Data_ACWorthTrend')
netWorth = []
ACWorth = []
for dayWorth in netWorthTrend[::-1]:
netWorth.append(dayWorth['y'])
for dayACWorth in ACWorthTrend[::-1]:
ACWorth.append(dayACWorth[1])
return netWorth, ACWorth
ACWorthFile = open(fileTrain, 'w')
for code in jjTrain:
try:
_, ACWorth = getWorth(code)
except:
continue
if len(ACWorth) > 0:
ACWorthFile.write(",".join(list(map(str, ACWorth))))
ACWorthFile.write("n")
print('{} data downloaded'.format(code))
ACWorthFile.close()
ACWorthTestFile = open(fileTest, 'w')
_, ACWorth = getWorth(jjTest)
if len(ACWorth) > 0:
ACWorthTestFile.write(",".join(list(map(str, ACWorth))))
ACWorthTestFile.write("n")
print('{} data downloaded'.format(jjTest))
ACWorthTestFile.close()
如上一篇所述,‘004609’, ‘004853’, ‘005524’, ‘005824’, '007749’是5只目前收益较稳定的偏债型混合基金。爬取每日净值数据,作为训练集和验证集(通过validation_split=0.2参数使之八二开)的数据文件。'007669’也是一只同类型的基金,上一篇没选它,仅仅是因为它目前在支付宝基金里面暂停代购。这次用作测试集的数据文件------实际只会用其中最近几个月的数据作为测试集(为了可视化更直观,没其它原因)。
三、建模,读入数据,训练,验证
import numpy as np
import pandas as pd
import csv
from keras.models import Sequential
from keras.layers import Dense
from matplotlib import pyplot as plt
plt.rcParams['font.sans-serif']='SimHei'
plt.rcParams['axes.unicode_minus']=False
batch_size = 16
epochs = 100
look_back = 5 #窗口天数
showdays = 60 #最后画图观察的天数,必须大于look_back(小于窗口天数无法预测)
X_train = []
y_train = []
X_validation = []
y_validation = []
testset = [] #用来保存测试基金的近期净值
test_mean = [] #用来保存测试基金的近期净值的look_back日均线
y_mean = [] #用来保存测试基金近期涨跌幅的look_back日均线
def create_dataset(dataset):
dataX, dataY = [], []
print('len of dataset: {}'.format(len(dataset)))
for i in range(len(dataset) - look_back):
x = dataset[i: i + look_back]
dataX.append(x)
y = dataset[i + look_back]
dataY.append(y)
return np.array(dataX), np.array(dataY)
def build_model():
model = Sequential()
model.add(Dense(units=32, input_dim=look_back, activation='relu'))
model.add(Dense(units=8, activation='relu'))
model.add(Dense(units=1))
model.compile(loss='mean_squared_error', optimizer='adam')
return model
# 导入数据
with open(fileTrain) as f:
row = csv.reader(f, delimiter=',')
for r in row:
dataset = []
r = [x for x in r if x != 'None']
days = len(r) - 1
#有效天数小于窗口天数,忽略
if days <= look_back:
continue
for i in range(days):
f2 = float(r[days - i])
f1 = float(r[days - i -1])
if f1 == 0 or f2 ==0:
dataset = []
break
#把数据放大100倍,相当于以百分比为单位
f1 = (f1 - f2) / f2 * 100
if f1 > 10 or f1 < -10:
dataset = []
break
dataset.append(f1)
if len(dataset) > look_back:
X_1, y_1 = create_dataset(dataset)
X_train = np.append(X_train, X_1)
y_train = np.append(y_train, y_1)
with open(fileTest) as f:
row = csv.reader(f, delimiter=',')
#写成了循环,但实际只有1条验证数据
for r in row:
dataset = []
#去掉记录为None的数据(当天数据缺失)
r = [x for x in r if x != 'None']
#只需要最后画图观察天数的数据
if len(r) > showdays + 1:
r = r[:showdays + 1]
days = len(r) - 1
#有效天数小于窗口天数,忽略
if days <= look_back:
continue
for i in range(days):
f2 = float(r[days - i])
f1 = float(r[days - i -1])
if f1 == 0 or f2 ==0:
dataset = []
break
#把数据放大100倍,相当于以百分比为单位
f1 = (f1 - f2) / f2 * 100
if f1 > 10 or f1 < -10:
dataset = []
break
dataset.append(f1)
testset.append(f2)
#保存look_back日均线,以备之后画图所用
y_mean = pd.Series(dataset).rolling(window=look_back).mean()
#预测明天,需先假定明天涨跌为0,增加入dataset
dataset.append(0)
f2=float(r[0])
testset.append(f2)
#保存look_back日均线,以备之后画图所用
test_mean = pd.Series(testset).rolling(window=look_back).mean()
if len(dataset) > look_back:
X_validation, y_validation = create_dataset(dataset)
#之前append改变了维数,需要重新改回窗口大小
X_train = X_train.reshape(-1, look_back)
print('num of X_train: {}tnum of y_train: {}'.format(len(X_train), len(y_train)))
print('num of X_validation: {}tnum of y_validation: {}'.format(len(X_validation), len(y_validation)))
# 训练模型
model = build_model()
model.fit(X_train, y_train, epochs=epochs, batch_size=batch_size, verbose=1, validation_split=0.2, shuffle=True)
# 评估模型
train_score = model.evaluate(X_train, y_train, verbose=0)
print('Train Set Score: %.2f' % (train_score))
validation_score = model.evaluate(X_validation, y_validation, verbose=0)
print('Test Set Score: %.2f' % (validation_score))
#设置测试集明天数值为NAN
testset.append(np.nan)
testset = np.array(testset).reshape(-1, 1)
#将之前假定的明天涨跌由0改为NAN
y_validation[showdays-look_back] = np.nan
y_validation = np.array(y_validation).reshape(-1, 1)
#去掉前(look_back-1)个NAN,注意这是预测均线(实际均线右移1天)
y_mean = y_mean[look_back-1:]
y_mean = np.array(y_mean).reshape(-1, 1)
# 图表查看预测趋势
predict_validation = model.predict(X_validation)
# 图表显示
fig=plt.figure(figsize=(15,6))
plt.plot(y_validation, color='blue', label='基金每日涨幅')
plt.plot(y_mean, color='yellow', label='之前日均涨幅')
plt.plot(predict_validation, color='red', label='预测每日涨幅')
plt.legend(loc='upper left')
plt.show()
共军主力都在这里了。
一开始,导入数据,建立训练集、验证集、测试集。如之前所说,基金净值多数是一元多、两元多,可不做“归一化”直接用,但显然还是用基金的每日涨跌幅作为数据,效果会更好。
关于训练集(含验证集):
由于是5个基金5条数据,最后生成X_train时append了一下,改变了维数,因此需要重新X_train.reshape(-1, look_back)改回窗口大小,亦即神经网络input_size。
关于测试集:
虽然写成了循环结构,但目前实际只有1个基金1条数据。这段代码不强壮,如果测试集的有效天数小于窗口天数(这样就无法预测了),测试集就建不了了。注意,由于希望预测出“明天”的数值,因此最后虚构了一个涨幅0的数据,作为明天的标签。但是,最后画图的时候,不希望这个涨幅0画出来,因此又把它设置为NAN。plot画线要求数据是两维的,因此把一维的list都转成了两维(其列数是1列)。
训练速度很快,主要的打印信息如下:
num of X_train: 3090 num of y_train: 3090
num of X_validation: 56 num of y_validation: 56
Epoch 1/100
156/156 [= = = = =] - 0s 3ms/step - loss: 0.0450 - val_loss: 0.1114
…
Epoch 100/100
156/156 [= = = = =] - 0s 2ms/step - loss: 0.0299 - val_loss: 0.1056
Train Set Score: 0.05
Test Set Score: 0.09
最后再解释一下这个“预测均线”:
以窗口大小为5天为例,假设第1~5天数据分别为1.01、1.02、1.03、1.04、1.05,则传统的5日均线,前4天为NAN,第5天为均值1.03。而这个“预测均线”则是前5天都是NAN,第6天为1.03,换言之,是传统均线向右平移一天。把它画出来,最主要原因是希望看到神经网络做出的预测,跟“预测均线”要有不同,亦即不希望训练出来一个“均线结果”,或高端一点的名称:“线性回归值”。
四、看图
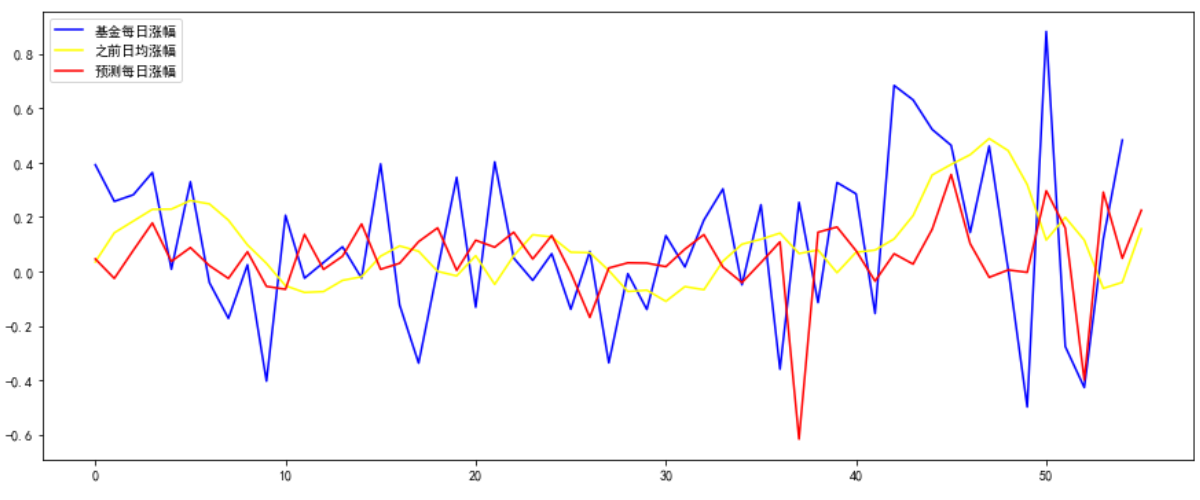
上面这张图,蓝线是每日实际涨跌值,因此最右边少一天数据(NAN值不显示);红线是这次运算得到的每日预测涨跌值;黄线是look_back日均线右移一天。显然,红线效果并不好。
最后再加一段看净值图形的代码:
# 实际净值、预测净值、右移一格的均线净值
y_validation_plot = np.empty_like(testset)
predict_validation_plot = np.empty_like(testset)
y_validation_plot[:, :] = np.nan
predict_validation_plot[:, :] = np.nan
test_mean = np.array(test_mean).reshape(-1, 1)
for i in range(look_back, len(testset)-1):
y = testset[i, 0] * (1 + y_validation[i-look_back, 0] / 100)
p = testset[i, 0] * (1 + predict_validation[i-look_back, 0] / 100)
#注意:test_mean已经向右平移了一天
#print('{:.4f} {:.4f} {:.4f} {:.4f}'.format(testset[i+1,0], y, test_mean[i, 0], p))
y_validation_plot[i, :] = y
predict_validation_plot[i, :] = p
# 图表显示
fig=plt.figure(figsize=(15,6))
plt.plot(y_validation_plot, color='blue', label='基金每日净值')
plt.plot(test_mean, color='yellow', label='之前日均净值')
plt.plot(predict_validation_plot, color='red', label='预测每日净值')
plt.legend(loc='upper left')
plt.show()
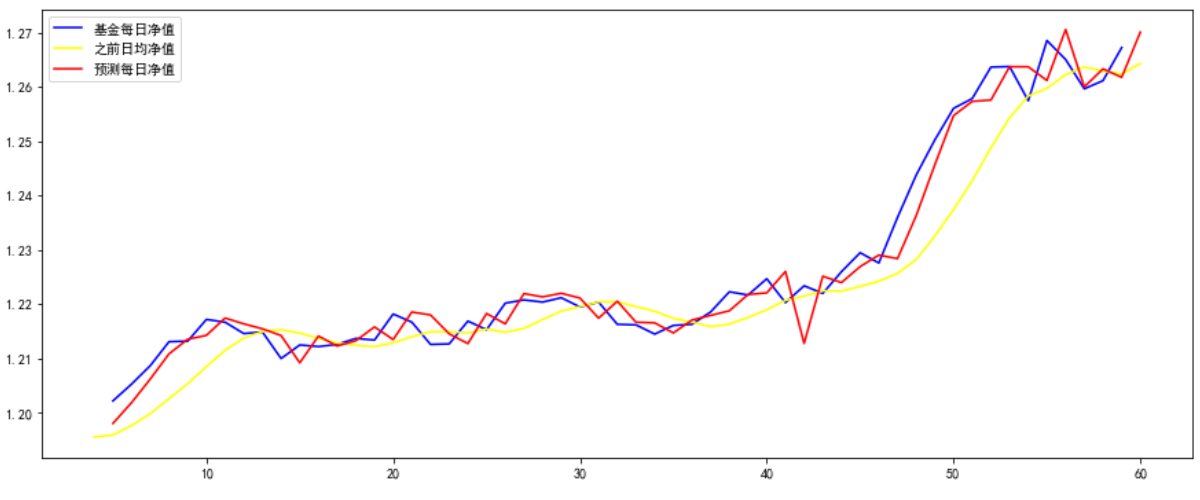
这张图可以作为“以涨跌幅作为数据”,优于“以基金净值作为数据”的一个佐证------虽然涨跌幅预测很差,但是净值不停地修正,图形看起来还不错了。事实上,网络上但凡以基金净值、股票价格或指数作为数据的,其神经网络训练减少loss,必然会有这样的神操作:明日价=今日价(准确地说:约等于今日价),预测线差不多就是实际线向右平移一天。
而且,从现实意义上说,每日涨跌其实更重要;收盘价什么的,除非它是茅台才有意义。
总结
用简单的全连接神经网络,预测明日涨跌幅,表现并不佳。
计划下一篇研究RNN(LSTM),请看下回分解。
剧透一句:大为改善,预测效果不错。
最后
以上就是细心缘分最近收集整理的关于Python预测基金净值:keras神经网络如何搭建神经网络预测基金净值总结的全部内容,更多相关Python预测基金净值内容请搜索靠谱客的其他文章。








发表评论 取消回复