文章目录
- 0 背景
- 1 大数据
- 2 相关公司
- 3 Hadoop
- 3.1 各个历史版本
- 3.2 Hadoop发展历史
- 3.3 Hadoop往后的发展
- 4 数据处理发展历史
- 5 数据湖和数据仓库的区别
- 6 大数据处理架构
- 7 数据湖技术
- 8 Spark流式处理/微批处理:
- 9 kv数据库
- 10 专业名字或术语
- Trino
- 中心化和分布式
- DevOps
- BSON与JSON的区别
- NoSQL【join不合适】
- 数据库事务ACID
- 即席分析(Ad Hoc)
- yarn
- 大数据四大阵营
- 后续不断更新补充
0 背景
做大数据开发有一段时间了,但是很多专业术语、概念、行业的发展情况都不是很清楚,本文的目的就是总结大数据的发展历程,让自己更清晰这个行业的发展潜力,以及值不值得继续留在这个行业。
1 大数据
全球最具权威的IT研究与顾问咨询公司高德纳对它的解释是海量、高增长率和多样化的信息资产,同时它价格是平民化的,处理模式也是创新性的。它在处理流程经过了优化,可以帮助公司利用数据发现隐藏在数据背后的价值和规律,然后使用这些挖掘到的信息帮助公司在事务处理上做更好的决策。
大数据的海量是指至少接近TB级别的数据量,高增长率是指【每天几十G数据量的增量】,多样化是指它可以存储结构化、半结构化、非结构化的数据。我们使用的大数据存储分析技术是hadoop,主要处理的数据是结构化和半结构化数据,虽然非结构化数据也可以存储、处理,但是不是它的优势,现在处理非结构化数据主要是使用对象存储(oss)。
推动力:
- 数据存储问题:
- 从共享存储到不共享存储:横向扩展,
- 分布式文件系统( HDFS/GFS ),
- 使用公有云的对象存储:Snowflake
- 数据处理速度问题:
- 分布式环境的数据处理:MapReduce
- 提升查询速度:交互式查询工具,Presto/Impana
- MapReduce的局限和处理速度:Spark
- 减小数据处理量来提升速度:增量处理,Apache Hudi
- 数据及时性问题:
- 微脚本:Spark
- Hadoop增删改:Apache Hudi
- 系统可维护性问题:
- 商业发行版:Cloudera…
- 公有云:BigQuery/Snowflake
2 相关公司
- 雅虎:最早开始做大数据的。
- 谷歌:三篇论文Google File System(2003), MapReduce(2004), BigTable(2006) 开启了大数据时代。
- Uber【优步】:美国科技公司,打车软件,开发了数据湖技术Hudi。
- DataBricks:开发了spark,开发了数据湖技术Delta Lake。
- 美国奈飞公司【网飞】:一家会员订阅制的流媒体播放平台 ,总部位于美国加利福尼亚州洛斯盖图,开发了数据湖技术Apache Iceberg。
3 Hadoop
3.1 各个历史版本
- 1、2代之间最大的区别在于增加了Yarn(资源调度器);
- 2、3代区别在于增加了命名节点(Name Node)的多活集群模式(单节点最大文件数量3000亿),此外,它支持部分服务的容器化部署、使用“抹除码”【EC】将原来三副本存储利用率不到30%提升到50%多,还增加了GPU支持来方便深度学习算法。
EC:
Erasure coding纠删码技术简称EC,是一种数据保护技术。最早用于通信行业中数据传输中的数据恢复,是一种编码容错技术。他通过在原始数据中加入新的校验数据,使得各个部分的数据产生关联性。在一定范围的数据出错情况下,通过纠删码技术都可以进行恢复。
纠删码(Erasure Code)与 Reed Solomon码:在存储系统中,纠删码技术主要是通过利用纠删码算法将原始的数据进行编码得到校验,并将数据和校验一并存储起来,以达到容错的目的。其基本思想是将k块原始的数据元素通过一定的编码计算,得到m块校验元素。对于这k+m块元素,当其中任意的m块元素出错(包括数据和校验出错),均可以通过对应的重构算法恢复出原来的k块数据。生成校验的过程被成为编码(encoding),恢复丢失数据块的过程被称为解码(decoding)。
Reed-Solomon(RS)码是存储系统较为常用的一种纠删码,它有两个参数k和m,记为RS(k,m)。如图1所示,k个数据块组成一个向量被乘上一个生成矩阵(Generator Matrix)GT从而得到一个码字(codeword)向量,该向量由k个数据块和m个校验块构成。如果一个数据块丢失,可以用(GT)-1乘以码字向量来恢复出丢失的数据块。RS(k,m)最多可容忍m个块(包括数据块和校验块)丢失。
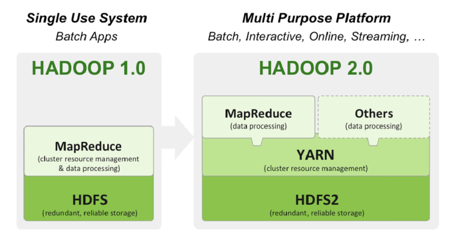
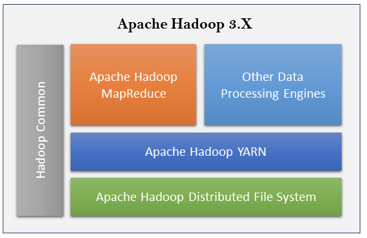
3.2 Hadoop发展历史
Google的三篇论文开启了大数据时代:Google File System(2003), MapReduce(2004), BigTable(2006);
2006.4.1 Hadoop发行第一个版本(包括HDFS和MapReduce算法)
2008.3.28 Hbase发布第一个版本 (源自BigTable论文 ,分布式KV数据库)
三个主要发行版公司诞生:Cloudera(2008), Hortonworks(2011), MapR(2009)
2010.10.1 Hive发布第一个版本(facebook,使用SQL对Hadoop进行查询)。
2010 Google关于Dremel的论文开启了交互式查询时代,Impala、Drill等引擎随后面世。
2013.10.16 Hadoop 2.2 RC发布,增加了Yarn – Hadoop资源调度。
2014.5.26 作为对Hive MapReduce的优化,Apache Spark首次发布。
2014.10 Snowflake 首次对外发售其云数据仓库产品。
2017.11.15 Hadoop 3.0 RC发布,增强了命名节点性能扩展能力。
2019.1 Cloudera与Hortonworks正式合并,2019.8 MapR被惠普企业收购。
2020.06.04 Uber Hudi(Hadoop Upserts Deletes and Incrementals)成为Apache顶级项目。
2021.06 Snowflake市值783亿美金,Cloudera市值46亿美金
关键点:
2004年谷歌的三篇论文分别对应Hadoop的三个核心组件:hdfs(分布式文件系统)、mapreduce(大数据并行处理的计算模型、框架和平台)、HBase(分布式存储系统)。两年后第一个Hadoop版本诞生,到了2010年hive(低延迟分析处理)的发布,让开发者摆脱了自己编写繁杂的mapreduce程序,也是这时开始hadoop才能用。
13、14年,Hadoop和其组建进一步进行了优化,加入了yarn,来解决工作管理和集群资源调度【hadoop1.0版本中当集群规模上升到一定JobTracker,同时部署多个时只有一个是处于 active 状态,受次负载上线的限制,整个集群的管理上限约为4k 台机器】,加入了spark(可以看作是mapreduce的升级版【在比较短的作业确实能快上100倍,但是在真实的生产环境下,一般只会快 2.5x ~ 3x!】)
2020年Hudi(Hadoop Upserts Deletes and Incrementals)的出现解决了高频Upsert、Deletes操作以及解决了增量数据处理的问题。
3.3 Hadoop往后的发展
- 使用对象存储,对象存储伪装成HDF(不会立即生效,但是会最终生效);
- 价格便宜,大概只有hdfs的1/3,不用担心数据的丢失维护硬件 ,但是丧失了文件系统的特点;
4 数据处理发展历史
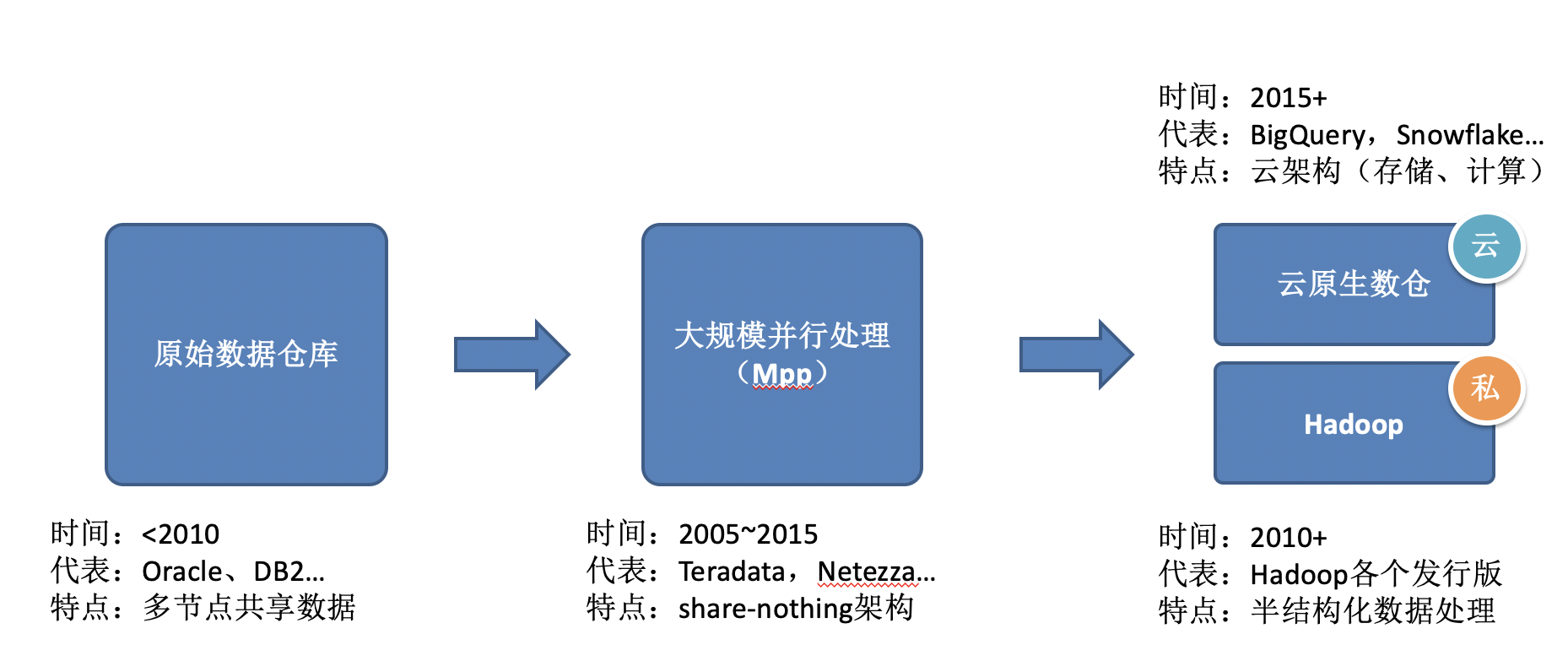
-
多节点共享数据:share-memory【共享同一片内存】、share-disk【每一个cpu使用自己的私有内存区域】),问题是interference:当添加更多的cpu,系统反而减慢,因为增加了对内存访问(memroy access)和网络带宽(network bandwidth)的竞争。
-
Shared nothing架构的大规模并行处理,降低了竞争资源的等待时间,从而提高了性能。代表的软件为Teradata,Netezza。但是MPP自身存在一些缺点:可扩展性差【很容易受到慢worker(它是最长路径)和interconnect的影响,集群规模在十几个节点后就没有性能提升了,甚至还可能下降】
-
云原生数仓:收费高、国内不成熟、数据放在云上不安全。
5 数据湖和数据仓库的区别
数据湖和数据仓库实际上都是一种技术,与特定的软件、系统没有必然的关联。
数据仓库做法:ETL(Extract-Transform-Load),实现将数据从一个系统抽取出来,经过转换,最终再加载到其他数据库或数据仓库中。
数据湖做法:ELT,直接将数据从一个系统抽取出来,加载到其他数据库或数据仓库中,在进行处理。
二者的区别是于先清洗数据还是先入库的区别。
数据仓库的缺点:
- 1,单节点,价格贵,大约10万元/1TB;
- 2,灵活性差,由于过程长;
6 大数据处理架构
- 1,离散数据源
缺点:
-
结构复杂:各个数据库之间都是独立的,为了减少数据冗余,方便删、改,大部分都遵循3N范式,这就导致了分析业务状况时,需要通过多层表的关联来达到,这就增加了很大的复杂度。例如分析用户还款情况时,需要订单表、门店表、地域表。【对比数仓:由于数据的输入是高度可控的,所以不需要尽可能地减少数据冗余,不遵循3NF范式。】
-
数据混乱:业务数据库中存在大量源数据中矛盾,如字段的同名异义、异名同义、单位不统一、字长不一致。
-
缺少历史:出于节约空间的考虑,业务数据库通常不会记录状态流变历史,这就使得某些基于流变历史的分析无法进行。【对比数仓:数据仓库可通过拉链表的形式来记录业务状态变化,甚至可以设计专用的事实表来记录。】
-
大规模查询缓慢:当业务数据量较大时,查询就会变得缓慢。尤其需要同时关联好几张大表,比如还款表关联订单表再关联用户表。【对比数仓:使用维度模型(星型、雪花模型),在查询上更快 (所有可能的查询方案的结果都保存起来,用空间换时间)】
-
2,传统的批处理架构
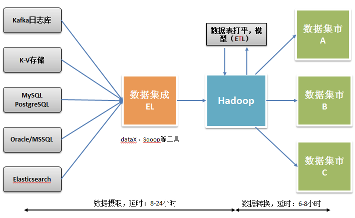
缺点:虽然可以处理大批量数据,但是数据以及性差。
- 3,批流分离的架构
架构解释:批可以慢一点,但是结果全面准确,而流处理就是用最快的时间对最新增量产生结果。然后将批和流的结果汇总,产生一个全局的结果。
缺点:需要同时运营两个不同的 pipeline,并且额外资源消耗也大幅增多,运营的人力和资源成本都大幅提高。
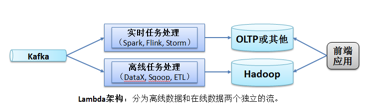
- 4,数据胡架构
结构解释:只有一个数据流,可以处理增量数据。解决了Hadoop无法处理的少批次,高频数据增、删、改操作。
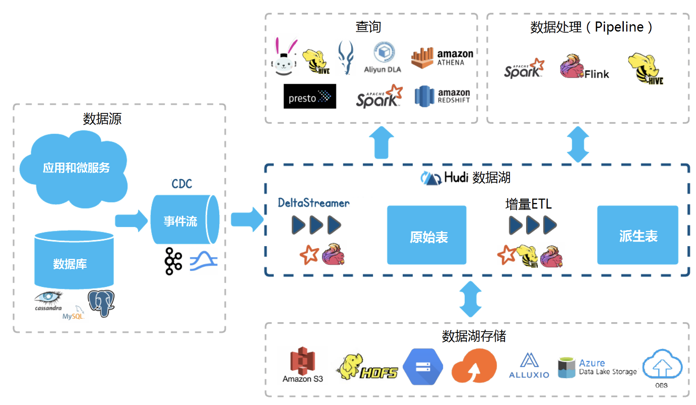
7 数据湖技术

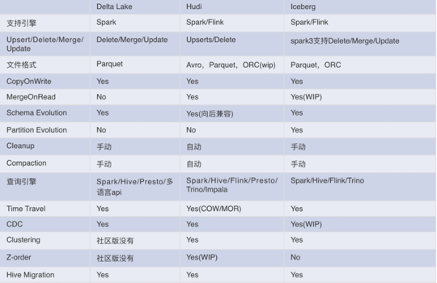
Dleta lake的文档和培训方面是最齐全的,社区发展情况较好,技术难度较低,但是社区版本被阉割了一些功能,商业版价格比较贵。Iceberg的软件成熟度、社区活跃度都不及hudi和Delta Lake。Hudi虽然技术相对复杂,但是软件开源,社区活跃度也高。
8 Spark流式处理/微批处理:
- 微批处理【最低的延迟可以搞到 100ms(主要是面向吞吐量进行设计,而且可以满足绝大部分应用场景,比如ETL和准实时监控)】:默认使用微批模式,spark 引擎会定期检查是否有新数据到达,然后开启一个新的批次进行处理;
- 持续流处理【可以满足延迟在10ms的场景】:在持续流模式下,spark不是定期调度新批次的任务,而是启动一直运行的驻守在 executor 上的任务,源源不断的进行读取处理输出数据;
9 kv数据库
指Key-value数据库,是一种以键值对存储数据的一种数据库,类似java中的map。这是一种NoSQL(非关系型数据库)模型,其数据按照键值对的形式进行组织、索引和存储。KV存储非常适合不涉及过多数据关系业务关系的业务数据,同时能有效减少读写磁盘的次数,比SQL数据库存储拥有更好的读写性能。
- 特点:
- 不使用SQL查询语言
- 可能不对ACID规范【可靠数据库管理系统(DBMS)中,事务(transaction)所应该具有的四个特性:原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)、持久性(Durability)】提供完全支持
- 原子性(Atomicity)原子性是指事务是一个不可分割的工作单位,事务中的操作要么都发生,要么都不发生。
- 一致性(Consistency)
事务前后数据的完整性必须保持一致。 - 隔离性(Isolation)
事务的隔离性是多个用户并发访问数据库时,数据库为每一个用户开启的事务,不能被其他事务的操作数据所干扰,多个并发事务之间要相互隔离。 - 持久性(Durability)
持久性是指一个事务一旦被提交,它对数据库中数据的改变就是永久性的,接下来即使数据库发生故障也不应该对其有任何影响
- 可能提供分布式,可容错的架构
- 缺点:如果不知道该从哪查询,需要遍历所有的key值,找到对应的value,对其进行过滤
10 专业名字或术语
Trino
PrestoSQL项目的重命名,该项目原本是由 Facebook 运营的,但 2019 年年初,Presto 团队的三位创始人离开了 Facebook。从此,Presto 项目被一分为二,由 Facebook 维护 PrestoDB,Martin、Dain、David 三位 Presto 项目最早的发起人维护 PrestoSQL。
中心化和分布式
中心化是管理方式,分布式是部署方式。
举例:
ESB中心化,分布式的系统;Datahub:集中式,去中心化。
DevOps
DevOps 强调通过一系列手段来实现既快又稳的工作流程,使每个想法(比如一个新的软件功能,一个功能增强请求或者一个 bug 修复)在从开发到生产环境部署的整个流程中,都能不断地为用户带来价值。
BSON与JSON的区别
BSON着眼于提高存储和扫描效率。 BSON文档中的大型元素以长度字段为前缀以便于扫描。 在某些情况下,由于长度前缀和显式数组索引的存在,BSON使用的空间会多于JSON。
NoSQL【join不合适】
泛指非关系型的数据库。随着互联网web2.0网站的兴起,传统的关系数据库在处理web2.0网站,特别是超大规模和高并发的SNS类型的web2.0纯动态网站已经显得力不从心,出现了很多难以克服的问题,而非关系型的数据库则由于其本身的特点得到了非常迅速的发展。NoSQL数据库的产生就是为了解决大规模数据集合多重数据种类带来的挑战,特别是大数据应用难题。
数据库事务ACID
在写入或更新资料的过程中,为保证事务(transaction)是正确可靠的,所必须具备的四个特性:原子性(atomicity,或称不可分割性)、一致性(consistency)、隔离性(isolation,又称独立性)、持久性(durability)。
即席分析(Ad Hoc)
用户根据自己的需求选择查询条件 (自定义查询条件),并让用户自行设计出报告。
yarn
一个工作调度和集群资源管理的框架。
大数据四大阵营
- OLTP(在线事务、交易处理):RDBMS、NoSQL、NewSQL
- OLAP(在线分析处理):
【MapReduce、Hadoop、Spark等】
- MPP(大规模并行处理):Greenplum、Teradata Aster等
- 流数据管理:CEP/Esper、Storm、Spark Stream、Flume等
后续不断更新补充
最后
以上就是辛勤苗条最近收集整理的关于大数据综述(Hadoop发展历史、大数据处理发展历史、大数据处理架构、数据湖技术等)0 背景1 大数据2 相关公司3 Hadoop4 数据处理发展历史5 数据湖和数据仓库的区别6 大数据处理架构7 数据湖技术8 Spark流式处理/微批处理:9 kv数据库10 专业名字或术语大数据四大阵营后续不断更新补充的全部内容,更多相关大数据综述(Hadoop发展历史、大数据处理发展历史、大数据处理架构、数据湖技术等)0内容请搜索靠谱客的其他文章。








发表评论 取消回复