上周去纽约参加了O'Reilly举办的数据分析展示会--Strata Data Conference 2019 New York。在开场的Keynote环节,O'Reilly的Chief Data Scientist,Ben Lorica先生简单介绍了目前大数据分析的现状和发展趋势,以及各个公司在此领域所做的努力。这本文章把Ben Lorica先生的演讲内容进行整理,同时把我在会议中获得的情报和在会后查阅的资料和大家分享。
作者:Kyle
1. Strata Data Conference
参考链接:https://conferences.oreilly.com/strata
O'Reilly Media大家都知道,出版了很多AI,数据科学方面的书,封面通常是标题+某个动物:

Strata Data Conference是O'Reilly Media举办的数据分析/科学展示会,每年举办三次,分别在湾区,伦敦和纽约。参加会议的大多数企业代表和员工,内容主要是各个企业展示自己最新开发的分析工具,或者介绍自己的一些成功事例。
会议持续四天,形式有以下几种:
- Keynote:所有人在一个大会场听大佬演讲
- Booth:参会企业展示自己的平台
- Session:在会议室里做事例分享
- Training:工具和相关技术的培训
关于参会者的一些统计信息:
- 从事工作最多的前三名师是:数据科学/分析师,技术经理和软件工程师
- 10年以上工作经验的人占42%
- 从事行业的前三名是:软件,金融和咨询
2. 大数据分析的工作流程和发展现状
"There is no AI without IA (information architecture)"
因为直观而且贴近用户,很多客户甚至部分从业者都以为分析建模就是数据处理的全部,其实一个强大的数据收集/管理/存储平台才是这一切的保障。
具体来说,一个完整的大数据分析工作流程大致包括以下几方面:
数据收集与导入 → 数据清洗与质量控制 → 数据管理与存储 → 数据分析与可视化 → 数据建模与模型管理
2-1.数据收集与导入
数据的收集与导入就是把数据写入数据库。
这目前为止的系统开发中,这都是数据库自带的功能,根本算不上什么课题。
因为在深度学习兴起之前,“数据”大多是结构化数据(表格);而到了大数据时代,“数据”不只是结构化数据,更多的是非结构化数据(图片,声音,视频)。随着需要收集的数据量的增大,数据的实时收集、实时处理变得不是那么容易。
为了解决这些问题,目前流行的工具有以下几种:

Spark和Kafka等依然是最流行的开源数据接入(data ingestion, data processing and ETL)工具。尤其是Kafka,在本次会议中有大量关于Kafka的实例介绍。
其次就是日渐崛起的Pulsar,发源于Yahoo,现在也是Apache家族的一员,因其卓越的性能受到越来越多的公司的青睐。
为什么已有Kafka,我们最终却选择了Apache Pulsar?
同时,在Data Catalog、Data Governance和Data Lineage方面,很多公司也在寻找合适的解决方案帮助他们了解:自己都有些什么数据,有谁可以接触到这些数据以及这些的数据是从哪里来的。
2-2. 数据质量控制
The Data is NEVER Clean, Projections Will Never Be Perfect.
脏数据和错误数据是数据分析工作的主要瓶颈,数据清理和修复约占数据科学家工作的60%。
为此很多人投入到使用ML技术,自动清洗数据的相关研究开发之中。在这之中,最受瞩目的当属HoloClean。
HoloClean/holoclean
HoloClean 关键特性:
- 它是第一个整体数据清理框架,在统一的框架中结合了各种异构信号,例如完整性约束,外部知识(词典)和定量统计
- 它是由概率推理驱动的第一个数据清理框架。用户只需提供要清理的数据集并描述高级域特定信号
- 它可以扩展到大型真实世界的脏数据集,并执行比最先进的方法还要准确两倍的自动修复功能
详细参照:https://www.oschina.net/p/holoclean
2-3. 数据管理与存储
这是永远的课题,一直都有很多StartUp和公司热衷于研究提高数据的管理和存储的相关技术。
在数据库方面本次会议的主角是memSQL,最大的特点就是处理数据的速度快!很快!非常快!世界第一快!!

同时还有其他一些明星产品:
比如基于时间序列的数据库: Timscale, InfluxDB
和图数据库(Graph Database):Tigergraph

另外一个很火的词就是:数据湖(Data Lake)
从前几年开始数据湖就一直是strata会议的一个主题。核心思想是把所有数据(结构,非结构)都保存在同一个地方,这样数据分析师就能用BI工具或者ML解锁数据的价值。
但问题是数据有时候非常混乱,早期的数据湖在数据管理方面有很大问题,而且插入修改数据等功能也存在不完善。为此,Cloudera(会议最大赞助商)、Cueball和Snowflake等公司正在对数据湖进行改进。

会议中和其他Data Scientist闲聊的时候发现有人弄不太清楚数据库、数据仓库和数据湖的区别。
简单来说数据库和数据仓库的区别在于Online和Offline,数据湖和前两个的区别在于Structured和Unstructured。
2-4. 数据分析与可视化
在实际工作中,我们需要把数据做成表格或者图表来展示数据的价值,
一些可视化的工具:

不过相比于以上这些,更让我眼前一亮的是Anaconda Booth里展出的PyViz和HoloViz,能用代码画出各种绚丽的图案,非常强大。

2-5. 数据建模与模型管理
这一块的热点是“自动”建模。现在几乎所有云平台都提供机器学习的功能(比如AWS的Sagemaker,GCP的CLOUD MACHINE LEARNING ENGINE),虽然精度和灵活性依然存在不足,但是简单易用,点点鼠标就搞定,不需要任何编程基础。而且其功能越来越强大,越来越完善,值得广大Python数据分析师提高警惕。
这些分析平台大多提供以下功能:

通过和各个Booth的人聊天,总结了一下目前各大分析平台的功能特点(遗憾本次展会没有DataRobot和最近被Salesforce收购的Tableau):
SAP Data Hub:功能单一,界面略丑,从技术角度讲优势真的很不明显。。。但是SAP的ERP毕竟有极其强大的市场占有率。Data Hub作为ERP的功能加强,有很大的营销优势,同时又能大大降低导入风险,力量不容小觑。
IBM Watson:功能很完善 ,界面很舒服,建模之后可以生成API即刻发表(开始以为是优势,后来发现好多平台都有这个功能)。模型监视模块做的尤其好,可以按时间轴选择不同时期模型的表现,而且可以监视具体变量的变化。
Keyence KI:日本平均工资最高的制造企业居然在数据科学方面有如此大的投入,令人有些意外。KI最有意思的地方是:模型完成后,可以通过调整变量值测试模型的输出分数。
SAS:老牌企业,中规中矩,没什么优点也没什么缺点。多云联动,数据共享算是一个亮点。
Dataiku:虽然是第一次听说这个公司,但产品确实最强大的。不但支持通常的数据库,云数据库的数据导入,还可以直接从Facebook,instagram等SNS导入数据。最强大的功能是支持代码修改,这样灵活性就大大增强了,既是分析工具又是IDE。

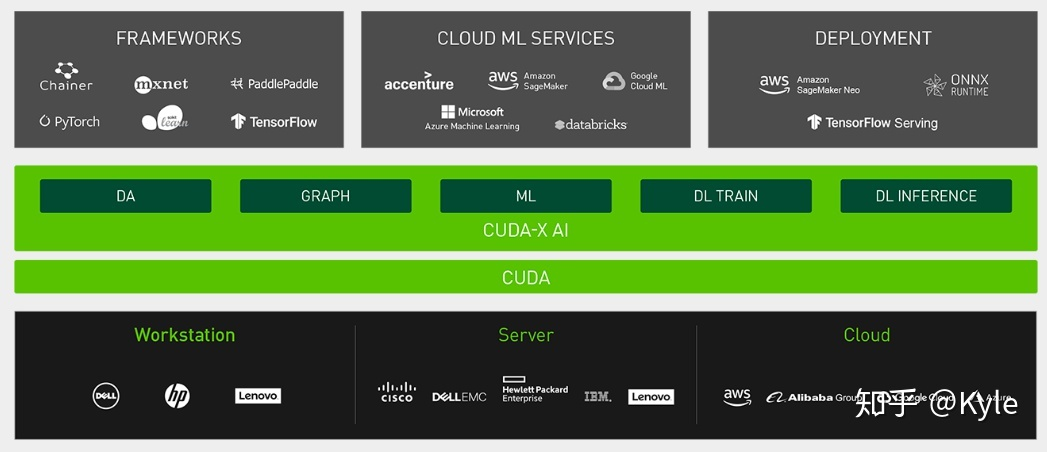
NVIDIA Cuda-X AI:这个有点特殊,不是分析工具,应该算是硬件平台。专门拿出来讲是因为NVIDIA宣称Cuda-X AI的处理速度惊人,沃尔玛之前需要一个月的训练,用cuda-X AI只需要两天。
附:Ben Lorica演讲视频完整版(好像是YouTube的平台,不知道国内能不能放):
Recent trends in data and machine learning technologies
最后
以上就是激昂芝麻最近收集整理的关于大数据分析软件的现状与发展趋势的全部内容,更多相关大数据分析软件内容请搜索靠谱客的其他文章。








发表评论 取消回复