按照时间线查看超大规模数据处理的重要技术以及它们产生的年代:
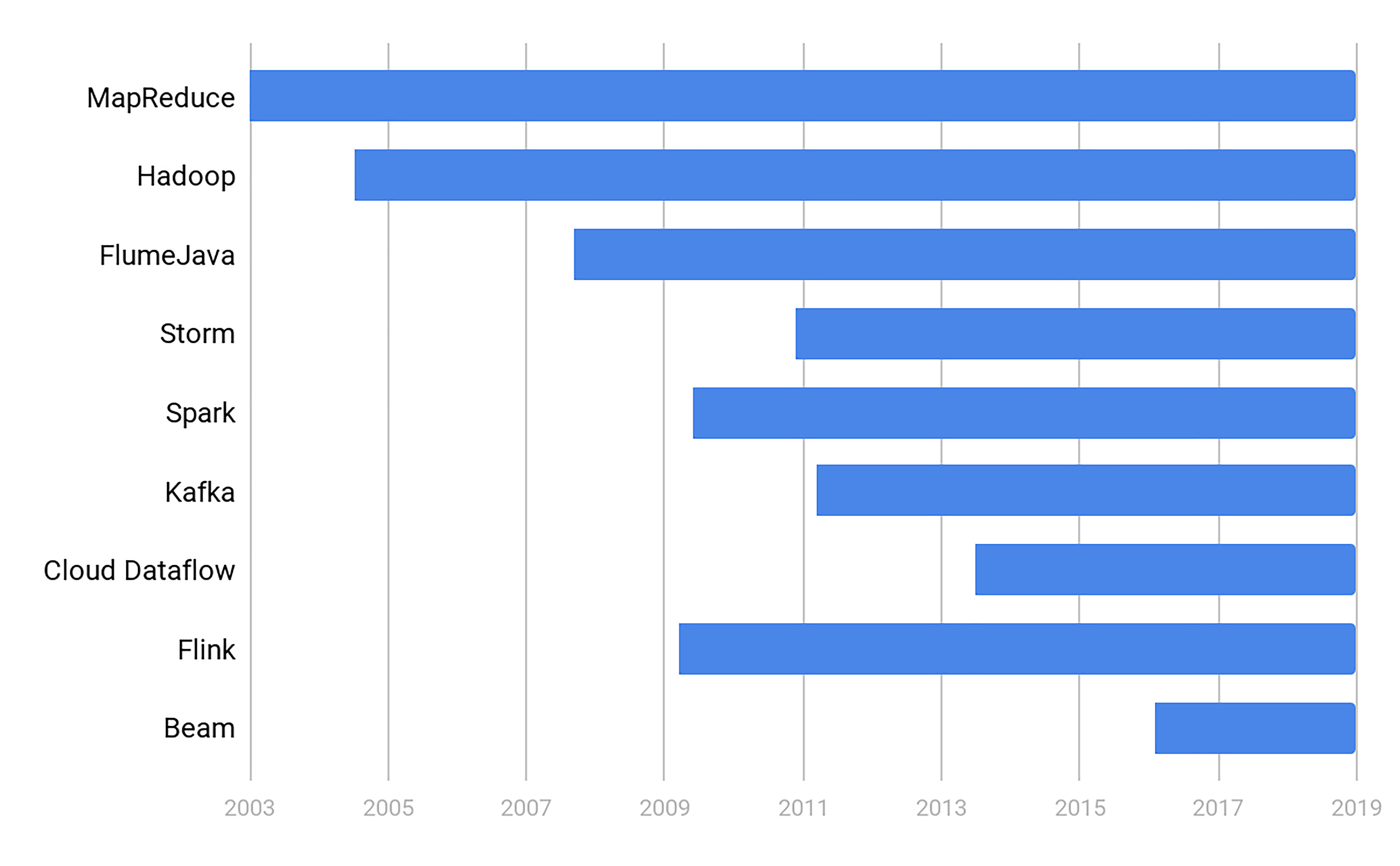
可以把超大规模数据处理的技术发展分为三个阶段:石器时代,青铜时代,蒸汽机时代。
石器时代
石器时代”来比喻MapReduce诞生之前的时期。
数据的大规模处理问题早已存在。早在2003年的时候,Google就已经面对大于600亿的搜索量。
但是数据的大规模处理技术还处在彷徨阶段。当时每个公司或者个人可能都有自己的一套工具处理数据。却没有提炼抽象出一个系统的方法。
青铜时代
2003年,MapReduce的诞生标志了超大规模数据处理的第一次革命,而开创这段青铜时代的就是下面这篇论文《MapReduce: Simplified Data Processing on Large Clusters》。
杰夫(Jeff Dean)和桑杰(Sanjay Ghemawat)从纷繁复杂的业务逻辑中,为我们抽象出了Map和Reduce这样足够通用的编程模型。后面的Hadoop仅仅是对于GFS、BigTable、MapReduce 的依葫芦画瓢。
蒸汽机时代
到了2014年左右,Google内部已经几乎没人写新的MapReduce了。
2016年开始,Google在新员工的培训中把MapReduce替换成了内部称为FlumeJava(不要和Apache Flume混淆,是两个技术)的数据处理技术。
这标志着青铜时代的终结,同时也标志着蒸汽机时代的开始(跳过“铁器时代”之类的描述,是因为只有工业革命的概念才能解释从MapReduce进化到FlumeJava的划时代意义)。
参考文章:《大规模数据处理实战》(蔡元楠)
最后
以上就是愉快小蘑菇最近收集整理的关于大数据处理的重要技术发展小结的全部内容,更多相关大数据处理内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复