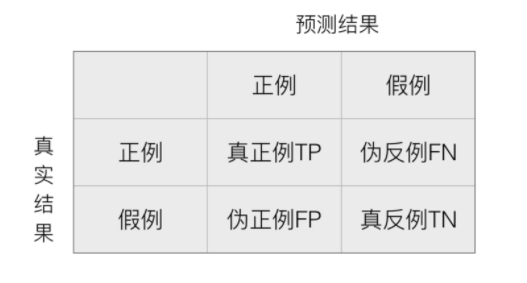
(1)混淆矩阵
在分类任务中,预测结果(Predicted Condition)与正确标记(True Condition)之间存在四种不同的组合,构成混淆矩阵,既适用于二分类任务,又适用于多分类任务。
(2)精确率(Precision)与召回率(Recall)
准确率 =(TP+TN)/ (TP+FP+FN+TN)
精确率:预测结果为正例样本中真实为正例的比例(了解) = TP / (TP + FP)

召回率:真实为正例的样本中预测结果为正例的比例(查得全,对正样本的区分能力) = TP / (TP + FN)

(3)F1-score
F1-score,反映了模型的稳健型, 取值分为为0-1,取值越接近1越好,适用于多分类!
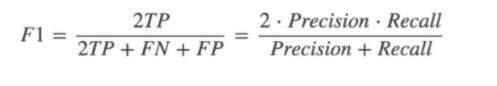
(4)分类评估报告api
- sklearn.metrics.classification_report(y_true, y_pred, labels=[], target_names=None )
-
- y_true:真实目标值
- y_pred:估计器预测目标值
- labels:指定类别对应的数字
- target_names:目标类别名称
- return:每个类别精确率与召回率
(5)ROC曲线与AUC指标
TPR与FPR
- TPR = TP / (TP + FN)
- 所有真实类别为1的样本中,预测类别为1的比例
- FPR = FP / (FP + TN)
- 所有真实类别为0的样本中,预测类别为1的比例
ROC(receiver operating characteristic curve)曲线
- ROC曲线的横轴就是FPRate,纵轴就是TPRate,当二者相等时,表示的意义则是:对于不论真实类别是1还是0的样本,分类器预测为1的概率是相等的,此时AUC为0.5
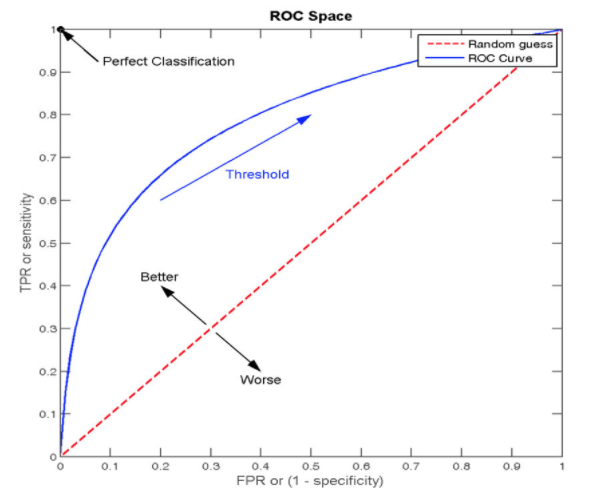
AUC指标
- AUC的概率意义是随机取一对正负样本,正样本得分大于负样本得分的概率
- AUC的范围在[0, 1]之间,并且越接近1越好,越接近0.5属于乱猜
- AUC=1,完美分类器,采用这个预测模型时,不管设定什么阈值都能得出完美预测。绝大多数预测的场合,不存在完美分类器。
- 0.5<AUC<1,优于随机猜测。这个分类器(模型)妥善设定阈值的话,能有预测价值。
- AUC只能用来评价二分类
- AUC非常适合评价样本不平衡中的分类器性能
AUC计算API
from sklearn.metrics import roc_auc_score
- sklearn.metrics.roc_auc_score(y_true, y_score)
- 计算ROC曲线面积,即AUC值
- y_true:每个样本的真实类别,必须为0(反例),1(正例)标记
- y_score:预测得分,可以是正类的估计概率、置信值或者分类器方法的返回值
最后
以上就是暴躁发箍最近收集整理的关于分类模型的评估方法的全部内容,更多相关分类模型内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复