文章目录
- DataX概述
- DataX安装配置
- DataX使用案例
DataX概述
- DataX 是阿里巴巴集团内被广泛使用的离线数据同步工具/平台,实现包括 MySQL,Oracle、SqlServer、Postgre、HDFS、Hive、ADS、HBase、TableStore(OTS)、MaxCompute(ODPS)、DRDS 等各种异构数据源之间高效的数据同步功能。
DataX如何解决异构数据源同步问题
- 为了解决异构数据源同步问题,DataX将复杂的网状的同步链路变成了星型数据链路,DataX作为中间传输载体负责连接各种数据源。当需要接入一个新的数据源的时候,只需要将此数据源对接到DataX,便能跟已有的数据源做到无缝数据同步。
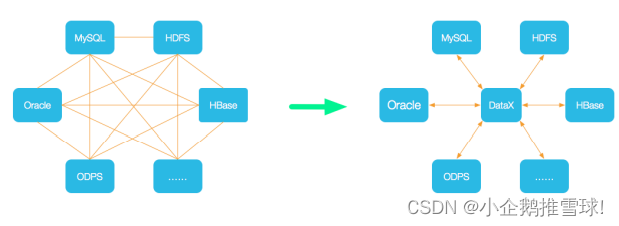
- DataX本身作为离线数据同步框架,采用Framework + plugin架构构建。将数据源读取和写入抽象成为Reader/Writer插件,纳入到整个同步框架中。

- Reader:数据采集模块,负责采集数据源的数据,将数据发送给Framework;
- Writer: 数据写入模块,负责不断向Framework取数据,并将数据写入到目的端;
- Framework:用于连接reader和writer,作为两者的数据传输通道,并处理缓冲,流控,并发,数据转换等核心技术问题。
3.DataX 3.0 开源版本支持单机多线程模式完成同步作业运行,一个DataX作业生命周期的时序图,从整体架构设计非常简要说明DataX各个模块相互关系。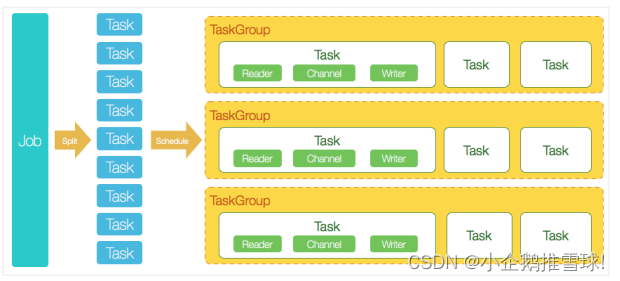
DataX核心模块
- DataX完成单个数据同步的作业,称为Job。DataX接受到一个Job之后,将启动一个进程来完成整个作业同步过程。DataX Job模块是单个作业的中枢管理节点,承担了数据清理、子任务切分(将单一作业计算转化为多个子Task)、TaskGroup管理等功能。
- DataX Job启动后,会根据不同的源端切分策略,将Job切分成多个小的Task(子任务),以便于并发执行。Task便是DataX作业的最小单元,每一个Task都会负责一部分数据的同步工作。
- 切分多个Task之后,DataX Job会调用Scheduler模块,根据配置的并发数据量,将拆分成的Task重新组合,组装成TaskGroup(任务组)。每一个TaskGroup负责以一定的并发运行完毕分配好的所有Task,默认单个任务组的并发数量为5。
- 每一个Task都由TaskGroup负责启动,Task启动后,会固定启动Reader—>Channel—>Writer的线程来完成任务同步工作。
- DataX作业运行起来之后, Job监控并等待多个TaskGroup模块任务完成,等待所有TaskGroup任务完成后Job成功退出。否则,异常退出,进程退出值非0
DataX安装配置
- DataX需要JDK和Python环境JDK(1.8以上,推荐1.8)、Python(推荐Python2.6.X)
- DataX的安装比较简单下载DataX工具包,解压至本地某个目录,进入bin目录,即可运行同步作业
配置环境变量 DATAX_HOME
$ cd {YOUR_DATAX_HOME}/bin
$ python datax.py {YOUR_JOB.json}
$ python $DATAX_HOME/bin/datax.py $DATAX_HOME/job/job.json
DataX使用案例
Reader插件和Writer插件:DataX3.0版本提供的Reader插件和Writer插件,每种读插件都有一种和多种切分策
"reader": {
"name": "mysqlreader", #从mysql数据库获取数据(也支持sqlserverreader,oraclereader)
"name": "txtfilereader", #从本地获取数据
"name": "hdfsreader", #从hdfs文件、hive表获取数据
"name": "streamreader", #从stream流获取数据(常用于测试)
"name": "httpreader", #从http URL获取数据
}
"writer": {
"name":"hdfswriter", #向hdfs,hive表写入数据
"name":"mysqlwriter ", #向mysql写入数据(也支持sqlserverwriter,oraclewriter)
"name":"streamwriter ", #向stream流写入数据。(常用于测试)
}
各种Reader插件、Writer插件的参考文档:https://github.com/alibaba/DataX
json配置文件模板
- json配置文件是一个job的描述;
- job下面有两个配置项,content和setting,其中content用来描述该任务的源和目的端的信息,setting用来描述任务本身的信息;
- content又分为两部分,reader和writer,分别用来描述源端和目的端的信息;
- setting中的speed项表示同时起几个并发执行该任务;
job的基本配置
{
"job": {
"content": [{
"reader": {
"name": "",
"parameter": {}
},
"writer": {
"name": "",
"parameter": {}
}
}],
"setting": {
"speed": {},
"errorLimit": {}
}
}
}
job Setting配置
{
"job": {
"content": [{
"reader": {
"name": "",
"parameter": {}
},
"writer": {
"name": "",
"parameter": {}
}
}],
"setting": {
"speed": {
"channel": 1,
"byte": 104857600
},
"errorLimit": {
"record": 10,
"percentage": 0.05
}
}
}
}
- job.setting.speed(流量控制):Job支持用户对速度的自定义控制,channel的值可以控制同步时的并发数,byte的值可以控制同步时的速度。
- job.setting.errorLimit(脏数据控制):Job支持用户对于脏数据的自定义监控和告警,包括对脏数据最大记录数阈值(record值)或者脏数据占比阈值(percentage值),当Job传输过程出现的脏数据大于用户指定的数量/百分比,DataX Job报错退出。
测试案例
Stream ===> Stream。stream reader/writer
python $DATAX_HOME/bin/datax.py /data/json/stream2stream.json
{
"job": {
"content": [{
"reader": {
"name": "streamreader",
"parameter": {
"sliceRecordCount": 10,
"column": [{
"type": "String",
"value": "hello DataX"
},
{
"type": "string",
"value": "DataX Stream To Stream"
},
{
"type": "string",
"value": "数据迁移工具"
}
]
}
},
"writer": {
"name": "streamwriter",
"parameter": {
"encoding": "GBK",
"print": true
}
}
}],
"setting": {
"speed": {
"channel": 2
}
}
}
}
最后
以上就是可靠毛巾最近收集整理的关于离线数仓数据同步工具DataX——(DataX概述,DataX安装配置,DataX使用案例)的全部内容,更多相关离线数仓数据同步工具DataX——(DataX概述内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复