python提取COCO,VOC数据集中特定类,实现xml转coco(voc转coco)格式
主要是踩坑(搜索)记录,已使用成功。
参考博客和github链接贴在文章末尾。如果使用过程中有问题,请留言告知,感谢各位大佬指正。
1.实现python提取COCO2017特定类别,适用于之前版本
原始coco2017 train文件数量为:118287
原始coco2017 val文件数量为:5000
指定需要提取的类别时注意不要写错类别名称,否则会得到许多object为None的xml文件,也可以通过提取之后的文件数量检查是否提取成功(应少于原始数量)
完整代码如下:
from pycocotools.coco import COCO
import os
import shutil
from tqdm import tqdm
import skimage.io as io
import matplotlib.pyplot as plt
import cv2
from PIL import Image, ImageDraw
#the path you want to save your results for coco to voc
savepath="/data/dataset/My_coo2017/COCO/" #保存提取类的路径
train_dir=savepath+'train2017/'
val_dir=savepath+'val2017/'
train_anno_dir=savepath+'train_Annotations/'
val_anno_dir=savepath+'val_Annotations/'
# datasets_list=['train2014', 'val2014']
# 记得修改名称
datasets_list=['train2017','val2017']
# datasets_list=['val2017']
classes_names = ['person', 'bicycle']
#coco有80类,这里写要提取类的名字,以person和bicyle为例,继续添加列表即可,但要注意不要写错类别,会导致出现很多没有object的文件
#Store annotations and train2014/val2014/... in this folder
dataDir= '/data/dataset/coco2017/' #原coco数据集
headstr = """
<annotation>
<folder>VOC</folder>
<filename>%s</filename>
<source>
<database>My Database</database>
<annotation>COCO</annotation>
<image>flickr</image>
<flickrid>NULL</flickrid>
</source>
<owner>
<flickrid>NULL</flickrid>
<name>company</name>
</owner>
<size>
<width>%d</width>
<height>%d</height>
<depth>%d</depth>
</size>
<segmented>0</segmented>
"""
objstr = """
<object>
<name>%s</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>%d</xmin>
<ymin>%d</ymin>
<xmax>%d</xmax>
<ymax>%d</ymax>
</bndbox>
</object>
"""
tailstr = '''
</annotation>
'''
#if the dir is not exists,make it,else delete it
def mkr(path):
if os.path.exists(path):
# shutil.rmtree(path)
# os.mkdir(path)
pass
else:
os.mkdir(path)
def id2name(coco):
classes=dict()
for cls in coco.dataset['categories']:
classes[cls['id']]=cls['name']
return classes
def write_xml(anno_path,head, objs, tail):
f = open(anno_path, "w")
f.write(head)
for obj in objs:
f.write(objstr%(obj[0],obj[1],obj[2],obj[3],obj[4]))
f.write(tail)
def save_annotations_and_imgs(coco,dataset,filename,objs,is_train=True):
#eg:COCO_train2014_000000196610.jpg-->COCO_train2014_000000196610.xml
img_path=dataDir+dataset+'/'+filename
# print(img_path)
#我这里 默认不需要复制图片,如果需要将以下9行取消注释即可
# if is_train:
# dst_imgpath=train_dir+filename
# else:
# dst_imgpath=val_dir+filename
img=cv2.imread(img_path)
# #if (img.shape[2] == 1):
# # print(filename + " not a RGB image")
# # return
# shutil.copy(img_path, dst_imgpath)
head=headstr % (filename, img.shape[1], img.shape[0], img.shape[2])
tail = tailstr
if is_train:
anno_path=train_anno_dir+filename[:-3]+'xml'
else:
anno_path=val_anno_dir+filename[:-3]+'xml'
write_xml(anno_path,head, objs, tail)
def showimg(coco,dataset,img,classes,cls_id,show=True):
global dataDir
I=Image.open('%s/%s/%s'%(dataDir,dataset,img['file_name']))
#通过id,得到注释的信息
annIds = coco.getAnnIds(imgIds=img['id'], catIds=cls_id, iscrowd=None)
# print(annIds)
anns = coco.loadAnns(annIds)
# print(anns)
# coco.showAnns(anns)
objs = []
for ann in anns:
# import pdb;pdb.set_trace()
class_name=classes[ann['category_id']]
if class_name in classes_names:
print(class_name)
if 'bbox' in ann:
bbox=ann['bbox']
xmin = int(bbox[0])
ymin = int(bbox[1])
xmax = int(bbox[2] + bbox[0])
ymax = int(bbox[3] + bbox[1])
obj = [class_name, xmin, ymin, xmax, ymax]
objs.append(obj)
draw = ImageDraw.Draw(I)
draw.rectangle([xmin, ymin, xmax, ymax])
if show:
plt.figure()
plt.axis('off')
plt.imshow(I)
plt.show()
return objs
if __name__ == "__main__":
mkr(savepath)
# mkr(train_dir)
# mkr(val_dir)
mkr(train_anno_dir)
mkr(val_anno_dir)
for dataset in datasets_list:
#./COCO/annotations/instances_train2014.json
annFile='{}/annotations/instances_{}.json'.format(dataDir,dataset)
#COCO API for initializing annotated data
coco = COCO(annFile)
#show all classes in coco
classes = id2name(coco)
print(classes)
#[1, 2, 3, 4, 6, 8]
classes_ids = coco.getCatIds(catNms=classes_names)
print(classes_ids)
for cls in classes_names:
#Get ID number of this class
cls_id=coco.getCatIds(catNms=[cls])
# import pdb
# pdb.set_trace()
img_ids=coco.getImgIds(catIds=cls_id)
# print(cls,len(img_ids))
# imgIds=img_ids[0:10]
for imgId in tqdm(img_ids):
img = coco.loadImgs(imgId)[0]
filename = img['file_name']
# print(filename)
objs=showimg(coco, dataset, img, classes,classes_ids,show=False)
# print(objs)
save_annotations_and_imgs(coco, dataset, filename, objs, dataset=='train2017')
如果想要保存图片需要将这些代码取消注释
# mkr(train_dir)
# mkr(val_dir)
以及
#我这里 默认不需要复制图片,如果需要将以下9行取消注释即可
# if is_train:
# dst_imgpath=train_dir+filename
# else:
# dst_imgpath=val_dir+filename
img=cv2.imread(img_path)
# #if (img.shape[2] == 1):
# # print(filename + " not a RGB image")
# # return
# shutil.copy(img_path, dst_imgpath)
2. python从VOC2012提取对应类别,也适用之前版本
原始VOC2012图片数量为 17125 张
尤其需要注意代码第74行
if((file[2:4]=='09') | (file[2:4]=='10') | (file[2:4]=='11') | (file[2:4]=='12')):
由于voc2009-2012的size部分在xml文件的末尾,如果对生成的xml文件尾部不做处理会导致丢失size信息,完整代码如下:
# -*- coding: utf-8 -*-
# @Function:There are 20 classes in VOC data set. If you need to extract specific classes, you can use this program to extract them.
import os
from tqdm import tqdm
import shutil
ann_filepath='/data/VOC_data/VOCdevkit/VOC2012/Annotations'
img_filepath='/data/VOC_data/VOCdevkit/VOC2012/JPEGImages'
img_savepath='/data/xuhui/dataset/My_voc2012/JPEGImages/'
ann_savepath='/data/xuhui/dataset/My_voc2012/Annotations/'
if not os.path.exists(img_savepath):
os.mkdir(img_savepath)
if not os.path.exists(ann_savepath):
os.mkdir(ann_savepath)
names = locals()
classes = ['aeroplane','bicycle','bird', 'boat', 'bottle',
'bus', 'car', 'cat', 'chair', 'cow','diningtable',
'dog', 'horse', 'motorbike', 'pottedplant',
'sheep', 'sofa', 'train', 'tvmonitor', 'person']
for file in sorted(os.listdir(ann_filepath)):
print(file)
fp = open(ann_filepath + '/' + file) #打开Annotations文件
ann_savefile=ann_savepath+file
fp_w = open(ann_savefile, 'w')
lines = fp.readlines()
ind_start = []
ind_end = []
lines_id_start = lines[:]
lines_id_end = lines[:]
# 想要保存的类别名称
classes1 = 'tt<name>bicycle</name>n'
classes2 = 'tt<name>bus</name>n'
classes3 = 'tt<name>car</name>n'
classes4 = 'tt<name>motorbike</name>n'
classes5 = 'tt<name>person</name>n'
#在xml中找到object块,并将其记录下来
while "t<object>n" in lines_id_start:
a = lines_id_start.index("t<object>n")
ind_start.append(a) #ind_start是<object>的行数
lines_id_start[a] = "delete"
while "t</object>n" in lines_id_end:
b = lines_id_end.index("t</object>n")
ind_end.append(b) #ind_end是</object>的行数
lines_id_end[b] = "delete"
#names中存放所有的object块
i = 0
for k in range(0, len(ind_start)):
names['block%d' % k] = []
for j in range(0, len(classes)):
if classes[j] in lines[ind_start[i] + 1]:
a = ind_start[i]
for o in range(ind_end[i] - ind_start[i] + 1):
names['block%d' % k].append(lines[a + o])
break
i += 1
#print(names['block%d' % k])
#xml头
string_start = lines[0:ind_start[0]]
#xml尾
if((file[2:4]=='09') | (file[2:4]=='10') | (file[2:4]=='11') | (file[2:4]=='12')):
string_end = lines[(len(lines) - 11):(len(lines))]
else:
string_end = [lines[len(lines) - 1]]
#在给定的类中搜索,若存在则,写入object块信息
a = 0
for k in range(0, len(ind_start)):
if classes1 in names['block%d' % k]:
a += 1
string_start += names['block%d' % k]
if classes2 in names['block%d' % k]:
a += 1
string_start += names['block%d' % k]
if classes3 in names['block%d' % k]:
a += 1
string_start += names['block%d' % k]
if classes4 in names['block%d' % k]:
a += 1
string_start += names['block%d' % k]
if classes5 in names['block%d' % k]:
a += 1
string_start += names['block%d' % k]
string_start += string_end
# print(string_start)
for c in range(0, len(string_start)):
fp_w.write(string_start[c])
fp_w.close()
#如果没有我们寻找的模块,则删除此xml,有的话拷贝图片
if a == 0:
os.remove(ann_savepath+file)
# else:
# name_img = img_filepath + os.path.splitext(file)[0] + ".jpg"
# shutil.copy(name_img, img_savepath)
fp.close()
如果想要保存图片需要将这些代码取消注释
# else:
# name_img = img_filepath + os.path.splitext(file)[0] + ".jpg"
# shutil.copy(name_img, img_savepath)
3.VOC转COCO数据格式
import os
import argparse
import json
import xml.etree.ElementTree as ET
from typing import Dict, List
from tqdm import tqdm
import re
def save_xmlpathlist(xml_path):
with open('voc_path_list.txt','w') as f:
path_list = sorted(os.listdir(xml_path))
for line in tqdm(path_list):
xml_file = os.path.join(xml_path, line)
f.write(xml_file + 'n')
def get_label2id(labels_path: str) -> Dict[str, int]:
"""id is 1 start"""
with open(labels_path, 'r') as f:
labels_str = f.read().split()
labels_ids = list(range(1, len(labels_str)+1))
return dict(zip(labels_str, labels_ids))
def get_annpaths(ann_dir_path: str = None,
ann_ids_path: str = None,
ext: str = '',
annpaths_list_path: str = None) -> List[str]:
# If use annotation paths list
if annpaths_list_path is not None:
with open(annpaths_list_path, 'r') as f:
ann_paths = f.read().split()
return ann_paths
# If use annotaion ids list
ext_with_dot = '.' + ext if ext != '' else ''
with open(ann_ids_path, 'r') as f:
ann_ids = f.read().split()
ann_paths = [os.path.join(ann_dir_path, aid+ext_with_dot) for aid in ann_ids]
return ann_paths
def get_image_info(annotation_root, extract_num_from_imgid=True):
path = annotation_root.findtext('path')
if path is None:
filename = annotation_root.findtext('filename')
else:
filename = os.path.basename(path)
img_name = os.path.basename(filename)
img_id = os.path.splitext(img_name)[0]
if extract_num_from_imgid and isinstance(img_id, str):
img_id = int(re.findall(r'd+', img_id)[0])
size = annotation_root.find('size')
print(filename)
width = int(size.findtext('width'))
height = int(size.findtext('height'))
image_info = {
'file_name': filename,
'height': height,
'width': width,
'id': img_id
}
return image_info
def get_coco_annotation_from_obj(obj, label2id):
label = obj.findtext('name')
assert label in label2id, f"Error: {label} is not in label2id !"
category_id = label2id[label]
bndbox = obj.find('bndbox')
xmin = int(float(bndbox.findtext('xmin'))) - 1
ymin = int(float(bndbox.findtext('ymin'))) - 1
xmax = int(float(bndbox.findtext('xmax')))
ymax = int(float(bndbox.findtext('ymax')))
assert xmax > xmin and ymax > ymin, f"Box size error !: (xmin, ymin, xmax, ymax): {xmin, ymin, xmax, ymax}"
o_width = xmax - xmin
o_height = ymax - ymin
ann = {
'area': o_width * o_height,
'iscrowd': 0,
'bbox': [xmin, ymin, o_width, o_height],
'category_id': category_id,
'ignore': 0,
'segmentation': [] # This script is not for segmentation
}
return ann
def convert_xmls_to_cocojson(annotation_paths: List[str],
label2id: Dict[str, int],
output_jsonpath: str,
extract_num_from_imgid: bool = True):
output_json_dict = {
"images": [],
"type": "instances",
"annotations": [],
"categories": []
}
bnd_id = 1 # START_BOUNDING_BOX_ID, TODO input as args ?
print('Start converting !')
for a_path in tqdm(sorted(annotation_paths)):
# Read annotation xml
ann_tree = ET.parse(a_path)
ann_root = ann_tree.getroot()
img_info = get_image_info(annotation_root=ann_root,
extract_num_from_imgid=extract_num_from_imgid)
img_id = img_info['id']
output_json_dict['images'].append(img_info)
for obj in ann_root.findall('object'):
ann = get_coco_annotation_from_obj(obj=obj, label2id=label2id)
ann.update({'image_id': img_id, 'id': bnd_id})
output_json_dict['annotations'].append(ann)
bnd_id = bnd_id + 1
for label, label_id in label2id.items():
category_info = {'supercategory': 'none', 'id': label_id, 'name': label}
output_json_dict['categories'].append(category_info)
with open(output_jsonpath, 'w') as f:
output_json = json.dumps(output_json_dict)
f.write(output_json)
def main():
parser = argparse.ArgumentParser(
description='This script support converting voc format xmls to coco format json')
parser.add_argument('--ann_dir', type=str, default='/data/dataset/My_voc2012/Annotations',
help='path to annotation files directory. It is not need when use --ann_paths_list')
parser.add_argument('--ann_ids', type=str, default=None,
help='path to annotation files ids list. It is not need when use --ann_paths_list')
parser.add_argument('--ann_paths_list', type=str, default='voc_path_list.txt',
help='path of annotation paths list. It is not need when use --ann_dir and --ann_ids')
parser.add_argument('--labels', type=str, default='labels.txt',
help='path to label list.')
parser.add_argument('--output', type=str, default='/data/xuhui/dataset/My_voc2012/my_Annotations/Instance_voc2012.json', help='path to output json file')
parser.add_argument('--ext', type=str, default='', help='additional extension of annotation file')
parser.add_argument('--extract_num_from_imgid', action="store_true",
help='Extract image number from the image filename')
args = parser.parse_args()
# 在当前目录下生成ann_paths_list文件
save_xmlpathlist(voc_path_list.txt)
label2id = get_label2id(labels_path=args.labels)
ann_paths = get_annpaths(
ann_dir_path=args.ann_dir,
ann_ids_path=args.ann_ids,
ext=args.ext,
annpaths_list_path=args.ann_paths_list
)
convert_xmls_to_cocojson(
annotation_paths=ann_paths,
label2id=label2id,
output_jsonpath=args.output,
extract_num_from_imgid=args.extract_num_from_imgid
)
if __name__ == '__main__':
main()
其中需要指定一些参数:
- labels.txt 中存放要提取的类别,格式如下
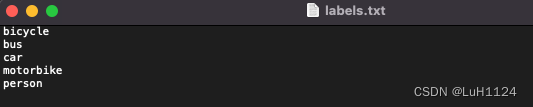
- –ann_dir 指定要转为coco json文件的xml所在文件夹目录
- –ann_paths_list对应的txt文件会自动生成
参考链接(感谢各位大佬)
- https://blog.csdn.net/weixin_38632246/article/details/97141364(之所以没用参考1的xml2coco,是因为size在xml文件末尾,会导致tag读取顺序出问题)
- https://github.com/yukkyo/voc2coco
最后
以上就是清脆仙人掌最近收集整理的关于python提取COCO,VOC数据集中特定类,实现xml转coco(voc转coco)格式的全部内容,更多相关python提取COCO内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复