文章目录
- COCO提取自己需要的类生成新的json文件
- 文件目录
- 目录说明
- 代码
COCO提取自己需要的类生成新的json文件
文件目录
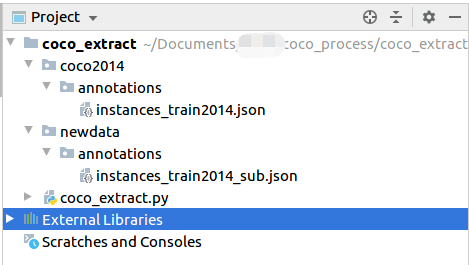
目录说明
coco2014/annotations - 用于存放coco数据集原本的json文件
newdata/annotations用于存放新生成的json文件
代码
from pycocotools.coco import COCO
import os
import shutil
import json
'''
路径参数
'''
#原coco数据集的路径
dataDir= '/home/capal/Documents/BoNi/coco_process/coco_extract/coco2014'
#用于保存新生成的数据的路径
savepath = "newdata/"
#最后生产的json文件的保存路径
anno_save = savepath+'annotations/'
'''
数据集参数
'''
#coco有80类,这里写自己需要提取的类的名称
classes_names = ['person', 'bicycle', 'car', 'motorcycle', 'bus', 'train', 'traffic light', 'fire hydrant', 'stop sign']
datasets_list=['train2014']
#生成保存路径
def mkr(path):
if os.path.exists(path):
shutil.rmtree(path)
os.mkdir(path)
else:
os.mkdir(path)
#获取并处理所有需要的json数据
def process_json_data(annFile):
#获取COCO_json的数据
coco = COCO(annFile)
#拿到所有需要的图片数据的id
classes_ids = coco.getCatIds(catNms = classes_names)
#加载所有需要的类别信息
classes_list = coco.loadCats(classes_ids)
#取所有类别的并集的所有图片id
#如果想要交集,不需要循环,直接把所有类别作为参数输入,即可得到所有类别都包含的图片
imgIds_list = []
for idx in classes_ids:
imgidx = coco.getImgIds(catIds=idx)
imgIds_list += imgidx
#去除重复的图片
imgIds_list = list(set(imgIds_list))
#一次性获取所有图像的信息
image_info_list = coco.loadImgs(imgIds_list)
#获取图像中对应类别的分割信息,由catIds来指定
annIds = coco.getAnnIds(imgIds = [], catIds = classes_ids, iscrowd=None)
anns_list = coco.loadAnns(annIds)
return classes_list,image_info_list,anns_list
#保存数据到json
def save_json_data(json_file,classes_list,image_info_list,anns_list):
coco_sub = dict()
coco_sub['info'] = dict()
coco_sub['licenses'] = []
coco_sub['images'] = []
coco_sub['type'] = 'instances'
coco_sub['annotations'] = []
coco_sub['categories'] = []
#以下非必须,为coco数据集的前缀信息
coco_sub['info']['description'] = 'COCO 2017 sub Dataset'
coco_sub['info']['url'] = 'https://www.cnblogs.com/lhdb/'
coco_sub['info']['version'] = '1.0'
coco_sub['info']['year'] = 2020
coco_sub['info']['contributor'] = 'smh'
coco_sub['info']['date_created'] = '2020-7-1 10:06'
sub_license = dict()
sub_license['url'] = 'https://www.cnblogs.com/lhdb/'
sub_license['id'] = 1
sub_license['name'] = 'Attribution-NonCommercial-ShareAlike License'
coco_sub['licenses'].append(sub_license)
#以下为必须插入信息,包括image、annotations、categories三个字段
#插入image信息
coco_sub['images'].extend(image_info_list)
#插入annotation信息
coco_sub['annotations'].extend(anns_list)
#插入categories信息
coco_sub['categories'].extend(classes_list)
#自此所有该插入的数据就已经插入完毕啦٩( ๑╹ ꇴ╹)۶
#最后一步,保存数据
json.dump(coco_sub, open(json_file, 'w'))
if __name__ == '__main__':
mkr(anno_save)
#按单个数据集进行处理
for dataset in datasets_list:
#获取要处理的json文件路径
annFile='{}/annotations/instances_{}.json'.format(dataDir,dataset)
#存储处理完成的json文件路径
json_file = '{}/instances_{}_sub.json'.format(anno_save,dataset)
#处理数据
classes_list,image_info_list,anns_list = process_json_data(annFile)
#保存数据
save_json_data(json_file,classes_list,image_info_list,anns_list)
print('instances_{}_sub.json'.format(dataset))
最后
以上就是怕孤单外套最近收集整理的关于COCO数据集处理系列(一)提取自己所需的类并生成新的json文件COCO提取自己需要的类生成新的json文件的全部内容,更多相关COCO数据集处理系列(一)提取自己所需内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复