文章目录
- 前言
- 1.Abstract(摘要)
- 2.Introduction(引言)
- 3.Object detection with R-CNN(基于R-CNN的目标检测)
- 提取候选框
- 提取特征
- 训练细节
- 4.Visualization, ablation, and modes of error(可视化,消融,错误模式)
- 可视化
- 对照试验(消融实验)
- 错误模型
- 5.Semantic segmentation(语义分割)
- 为什么用SVM不用softmax?
- 小总结
前言
今天看一下大名鼎鼎的目标检测算法 R-CNN。
R-CNN系列推演:
- R-CNN 论文解读
- SSPnet 论文解读
- Fast R-CNN 论文解读
- Faster R-CNN 论文解读
- FPN 论文解读
- Mask R-CNN 论文解读
这篇R-CNN是后续的基础,得好好看看。
论文下载地址:https://arxiv.org/pdf/1311.2524v5.pdf
这个论文有很多版本,这里是V5版本,其实每个版本之间核心内容差距不大,有的可能只是个别单词的差别,原始版本和这个V5版本第四章不一样,V5版本新加了一章(非重点内容),所以用那个版本都行。
论文题目:Rich feature hierarchies for accurate object detection and semantic segmentation
R-CNN是两阶段目标检测算法的开山鼻祖。
两阶段:
- 先从目标图片中提取候选框
- 再对候选框进行分类
两阶段或多阶段目标检测的推演:
- R-CNN(2013)
- SPPNet(2014)
- Fast R-CNN(2015)
- Faster R-CNN(2015)
- FPN(2016)
- Mask R-CNN(2017)
1.Abstract(摘要)
作者在摘要中说,传统的计算机视觉已经瓶颈了,所以作者在深度学习上来提出一些方法和思想来打破这个瓶颈,就是先提候选框,然后再对候选框逐个分类。改进之后的算法模型在VOC 2012上比之前的平均精度(mAP)提升了30%。作者先在imagenet上进行训练,然后迁移学习,在VOC上微调,作者也做了很多实验可以证明该模型确实学习到了很多特征。
region proposals :候选框提取
因为候选框提取是这个模型的主要功能,所以取名 R-CNN ,其中R对应region 。
最后放的那个连接,里面就是相关的代码。
关于 PASCAL VOC 数据集:
PASCAL VOC挑战赛 (The PASCAL Visual Object Classes )是一个世界级的计算机视觉挑战赛, PASCAL全称:Pattern Analysis, Statical Modeling and Computational Learning,是一个由欧盟资助的网络组织。
很多优秀的计算机视觉模型比如分类,定位,检测,分割,动作识别等模型都是基于PASCAL VOC挑战赛及其数据集上推出的,尤其是一些目标检测模型(比如大名鼎鼎的R CNN系列,以及后面的YOLO,SSD等)。
PASCAL VOC从2005年开始举办挑战赛,每年的内容都有所不同,从最开始的分类,到后面逐渐增加检测,分割,人体布局,动作识别(Object Classification 、Object Detection、Object Segmentation、Human Layout、Action Classification)等内容,数据集的容量以及种类也在不断的增加和改善。该项挑战赛催生出了一大批优秀的计算机视觉模型(尤其是以深度学习技术为主的)。
2.Introduction(引言)
最近论文看多了,基本摸清套路了,一个正规的论文引言部分就那么几个点,介绍当前领域的瓶颈和痛点,前人达到的最好的水平,作者能改进的地方和思路。
开头第一句话就是俩单词,Features matter. 上来就告诉你 特征很重要。毕竟要在图片上做操作,模型对图片的认识程度取决于学习到了多少有用的特征,有用的特征越丰富,能做的事就越多,精度就越高。所以作者在这里就是直接强调了一波特征的重要性。作者敢这么提,那说明这个模型在特征提取方面的效率应该是做的非常出色了。
按照套路,引言第一段就介绍 当前计算机视觉领域的痛点和瓶颈,提到了人工设计的特征提取方法SIFT(尺度不变特征变换)和HOG(梯度直方图)。这俩都是19几几年到20年初的东西,通过像素层面的领域信息计算来得出结果的。使用这些方法在VOC上很多年都没有什么大进展。
第二段提到了一个什么V1表皮层区域,我查了查资料,作者这里可能想表达 使用之前的技术像HOG和SIFT都只能学习到图片的表层信息,像灵长类动物的V1表层区域。前面也说了这些老技术只能在局部像素领域上计算,所以类似于深度学习的浅层网络,没有后续的语义信息的整合功能。
作者在第二段已经隐晦的提出了多阶段的处理方案,因为你老技术都是一个阶段嘛,就类似于V1表层区域的阶段,所以应该有很多阶段,比如第一阶段是表层,后续阶段的抽象 整合等,最后变成语义信息。
后面继续介绍前人的工作,其中有意思的是貌似介绍到了LeNet-5的灵感,说是有个日本的科学家做实验发现大脑的多层处理图片信息的情况,然后LeCun把他融合进了深度学习里。
然后又是说了一大堆前人的工作,我就不说了,直到作者提出了两个待研究的问题,第一个是怎么样去训练一个有很好表示能力的神经网络用来定位(目标检测嘛肯定位是非常重要的一步)。第二个就是如何解决VOC数据集的数据量很少的问题。
这里要顺带说一下 图像分类和目标检测的一些区别:
- 图像分类只需要给网络一张图片让他去训练,网络得到N个结果,取其中概率最大的那个就行了,最后得到的是一个图片的所属类别。
- 而目标检测需要画出来一张图片中的每一个物体的框,并且对每一个框进行分类。
作者后面说目标检测问题可以当作回归问题(regression problem)来解决,但在作者的那个时代。将其当作回归问题来解决是很难的,作者通过实验表明,使用回归mAP在30%左右,没用回归方法达到了58%。
我不知道作者这里说的回归问题是不是机器学习里的那个回归,应该是吧,机器学习里的回归问题就是建模再找数据之间的关系。
顺带一提yolo系列就是把目标检测当作回归问题来解决的。
后面又提到一个方法就是滑动窗口法,该方法需要保持图片的高空间分辨率,空间分辨率就是feature map的长宽,像池化层肯定会减少长宽,所以下采样就不能太狠,网络不能很深,作者的网络比较深,所以用不了这个方法。
总之说来说去就是传统的啥方法也用不了,都有各种各样的缺陷。顺而可以提出作者自己的方法,就是开头说的那种两阶段的方法,作者具体描述了一下这两个阶段,在预测推断的时候先生成2000个与类别无关的候选框,再将每一个候选框送给CNN,CNN将在每一个候选框中提取特定长度的特征向量,也就是说建立一个向量,这个向量里一堆数,这个向量就是他提取出来的特征,然后再将这个向量送给对每个类别进行了单独训练的线性SVM中,这就解决了俩问题中的模型算法的问题,额好吧,恕我直言我不能理解大佬们的想法,这里面的具体操作过程我还没理清,不过也正常,像这种比较重要的论文前几遍都是大面积的不理解,就跟刚开始看LeNet里那个dropout思想的卷积一样,慢慢来吧或许过几个月就能懂了。
解决第二个问题,就是数据量少,lable标签也少的问题,传统方法就是无监督训练+监督微调,作者也是特意的在这个方法前面加上了 conventional这个单词,也就是传统的意思,虽然确实这个无监督+监督方法是传统方法,但是作者这么一加就表明有点low的意思,说明作者肯定不会使用这个方法了,这个问题的解决方法在开头也是说过了,就是迁移学习的方法,先在imagenet数据集上预训练,然后再去VOC数据集上做微调。
用了这两个解决办法之后的精度在54%,那些传统的方法精度为33%。高了21%。
然后作者又说自己的参数量很少,模型很高效,实际上我在查阅资料的时候发现R-CNN并不高效,他有很多的重复计算,并且看上面的操作步骤,先提取2000个候选框,然后给CNN 再给SVM,实际上是一个工作串,比较容易出问题,就这样还说自己高效,当然 他是对比在此之前的模型,而且毕竟在写论文嘛,VGG不是也在自己的论文里说他高效嘛。却不知后面的论文都跟VGG比较,后来流传着一句话 反面教材VGG哈哈。手动狗头。
这时候看开头的这个图:
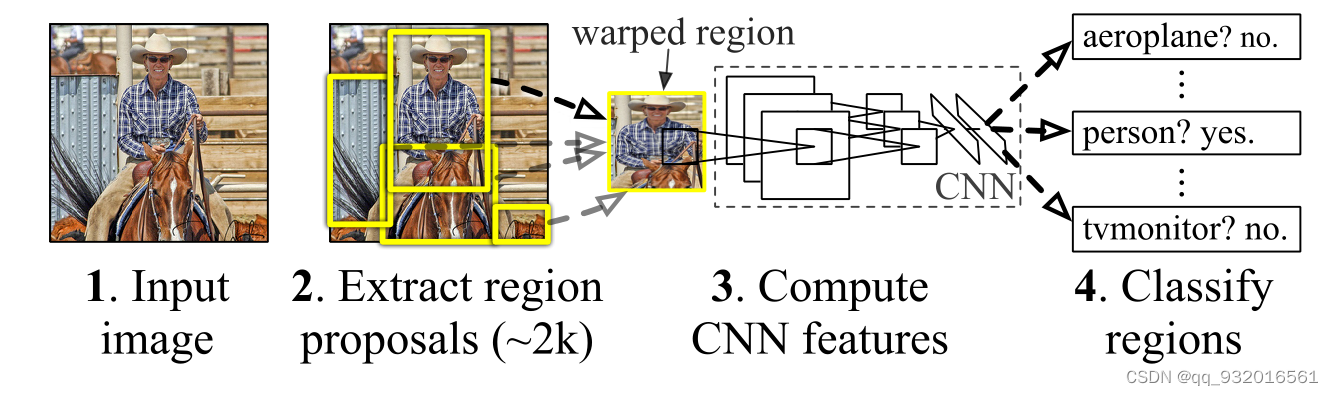
这个图就是在说该模型的步骤,一张图片提取2000张候选框。每一个候选框进行缩放,缩放成227* 227大小的送给CNN里,每一个框都送给CNN,再送给SVM。这里是有多少个类别就有多少个SVM。
作者在引言的最后说到一个结论,加入回归方法之后可以显著降低定位错误。并且模型用在分割任务上也有很好的性能。
好家伙这篇论文的引言好长,而且很多地方都不能直接略过 就离谱。
3.Object detection with R-CNN(基于R-CNN的目标检测)
这一章节作者就开始详细阐述他R-CNN模型的三个阶段了。
提取候选框
提取候选框的方法-----selective search 。
作者在这里介绍了好几种提取候选框的方法,但是直接选择了selective search,也没说为啥选这个,所以我觉得不必要了解selective search背后的算法原理了。
关于 selective search:
selective search:叫做选择性搜索,顾名思义是有选择的搜索。先对图片聚类产生初始分割区域,根据颜色、纹理、大小、相似度等加权合并产生候选框。
用 selective search 提取出来2000个候选框,然后交给下一步的CNN进行特征提取。
提取特征
这里就接受到上面传过来的候选框,然后使用CNN进行特征提取。
作者这里使用的Alexnet网络进行特征提取,将候选框强行缩放到227 * 227的RGB图像,这里是一刀切式的缩放,就假如是个矮圆形,也给你强行拉伸成椭圆。
后面一段中有两个名词:
non-maximum suppression:
非极大值抑制,简单的说就是一个寻找局部最大值的过程。但候选框被选出后送入分类器得到一个得分,先拿到最大得分的,然后判断其他框于当前最大的分框的重合度(IOU),如果该重合度超过一定阈值则删除,这个也好理解,就是程序通过判断吧可能重复标注的候选框删掉。
IOU:
IoU是一种测量在特定数据集中检测相应物体准确度的一个标准。IoU是一个简单的测量标准,一般指代模型预测的 bbox 和 Groud Truth 之间的交并比。只要是在输出中得出一个预测范围(bounding boxex)的任务都可以用IoU来进行测量。为了可以使IoU用于测量任意大小形状的物体检测,也就是说,这个标准用于测量真实和预测之间的相关度,相关度越高,该值越高。
作者的实验也给出了一个时间,预测一张图片在CPU上需要53秒,在GPU上需要13秒,好家伙,也太慢了,虽然那个时候的GPU还没现在的厉害,不过R-CNN的模型慢也是不可忽视的一部分因素,这要是放到工业上,13秒才能处理好,无人车早不知道撞哪里去了。
特征提取之后得到 2000 * 4096的矩阵, 就是2000个候选框 和每个候选框的4096维特征。让该矩阵和SVM的4096维权重矩阵相乘,这个SVM的权重矩阵是4096 * N的 ,N是类别,最后相乘得到的结果就是每一个候选框在类别上的概率。
在这可以看出来,费时的操作在获取 2000* 4096矩阵这,也就是将每个候选框送到CNN到识别结束这块操作。
训练细节
在前面也说过了,就是先Imagenet然后迁移学习微调。我也是发现了,在上一节也是,就是提取候选框,提取特征,然后SMV这三步,在论文中好几个地方都出现了,这节也是,微调这个在好几个地方都说一变,写论文奥义是吧,一个东西来回的说,变着法的说。
后面说了一堆的训练细节和微调细节,按照惯例大概看了一下就过了,毕竟DL就是玄学,我觉得这些调参的参数并不能泛化,大概遵守就行。比如微调中的超小学习率等等。
细节里有一个正负样本,简单的说一下,负样本就是与我们要识别的图片主题无关的候选框,比如要识别狗,负样本就是狗叼着的一根骨头,而正样本就是狗本身的那个候选框,实际操作中 负样本的数量很可能远大于正样本,所以要统一采样正负样本规定比率的数量。防止模型光学习负样本了(正样本过采样,负样本下采样)。
至于模型如何分辨正负样本,作者将所有与 ground-truth 框重叠 ≥ 0.5 IoU 的区域建议视为该框类别的正面,其余视为负面。
注意,上面说的0.5 IOU是在CNN中的阈值,当数据送到SVM中,这个阈值变成 <= 0.3 Iou的为负样本,也就是 >=0.7的为正样本。这个阈值是通过预实验得到的(网格搜索预实验)。
在训练SVM分类的时候因为数据太大没法放到内存,所以提到一个方法: hard negative mining method,查阅资料得知,该方法相当于一个错误纠正区,将分错的地方全放进来,然后不断的让其再次训练,再次学习,错题本?
本章最后使用了两节说明了模型在VOC10-12和image2013数据集上的结果,别看了,记住一个字, 好!就完了。
4.Visualization, ablation, and modes of error(可视化,消融,错误模式)
可视化
上来作者先介绍了一下可视化目前的情况,可视化CNN第一层是很容易的,后面就比较难了,可解释性也比较差,然后提到了一下ZFNet的反卷积可视化方法。
然后作者提出了自己的可视化方法,将所有的候选框输入找到能使得某个feature map中的某个值产生最大激活的候选框。
使用下面这个图理解一下这个方法。
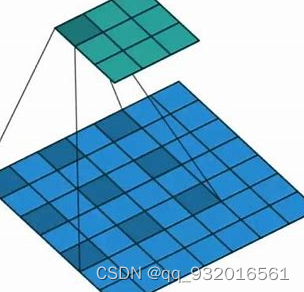
上面的绿色矩形就是卷积之后得到的feature map,现在只关注该feature map中的一个值,然后将全部候选框怼进去,看看那几个框能使得该值最大,则这些框就是当前神经元学习的信息。
作者在后面放了一张图,我就截取其中的一小部分来看看,这一行是一个神经元学习的特征,可以看出来,这个神经元学习的就是 黑点 点阵 这个特征,狗的眼睛也可以看作一个稀疏的 黑点阵嘛。

对照试验(消融实验)
其实就是单一变量的对照试验(Ablation studies)。
3.2节 开头有一个短语 half-wave rectified ,实际上就是Relu激活函数嘛,看后面的公式也能看出来,整这么玄乎还。
前几段作者在介绍CNN里各层的作用,用的就是不断切除某些层来看结果,在imagenet数据集上进行操作,就是还没迁移到VOC的那个阶段。
直接看这一块的结论,作者将fc6和fc7砍掉之后性能没什么变化,也就说明预训练的实际性能来源于卷积操作,而不是全连接。
后续又说了一些有的没的非关键点,都是DPM和HOG等传统模型的相互比较,总而言之都是渣渣,而且都是老模型,精度上相差太多,没必要深究。直接来看结论:
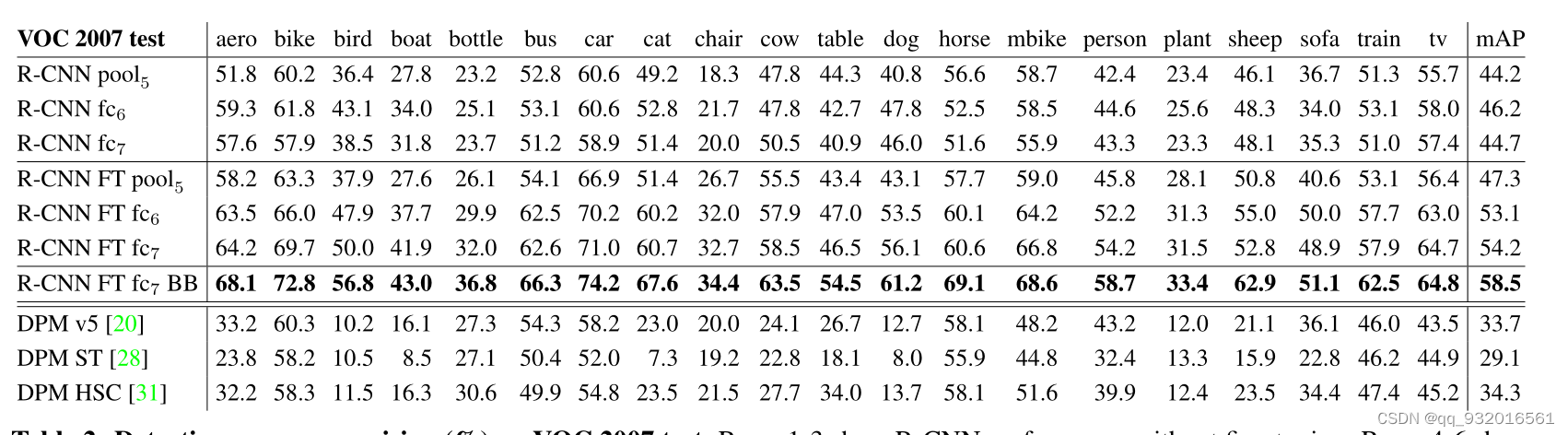
前三行是没有微调,直接在imagenet上训练的结果,中间的四行是加了微调,有加了BB(回归)之后的结果,最后三行就是传统的DPM算法(DPM就是HOG的改进版)。
效果最好的就是加粗哪一行 R-CNN+BB+微调。
从模型精度可以看出加了微调之后,全连接层的作用凸显出来了,这也说明可能CNN提取了通用的特征,微调时全连接FC针对特定领域。
错误模型
错误标号:
- LOC 分类正确 定位误差大。
- SIM 分类为近似类别。
- Dth 分类为非近似类别。
- BG FP背景识别为目标。
原文中有个单词 fired on,开火的意思,可以翻译成激活。在这里应该翻译成‘被识别’。
论文中给了图:
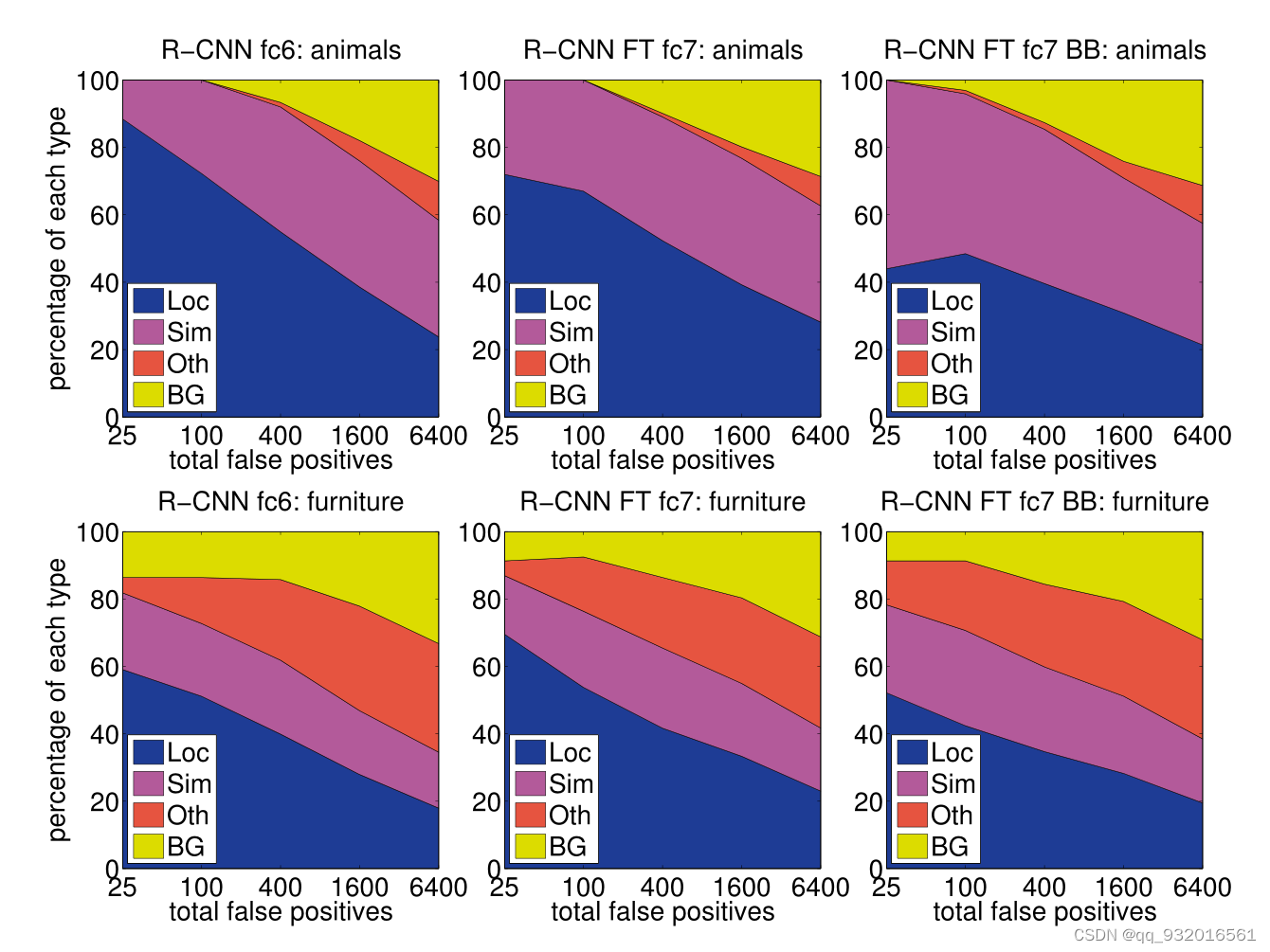
图里也能看出来 其中蓝色的部分 LOC也就是定位出错,在加入BB(bounding box) 回归之后明显降低了,在这也可以直到BB的一个大的用途就是减少定位错误。
所以R-CNN在分类上效果不错,定位上稍差点,暗示所给的2000个候选框效果不好,还有一个导致定位差的原因是CNN中的采样,采样池化带来的平移不变性,这是为啥不太理解,然后去查了查资料,发现有解释说因为不变性导致空间信息丢失从而定位变差,说实话这块不太理解。
后续的一张图,看的我一脸懵。
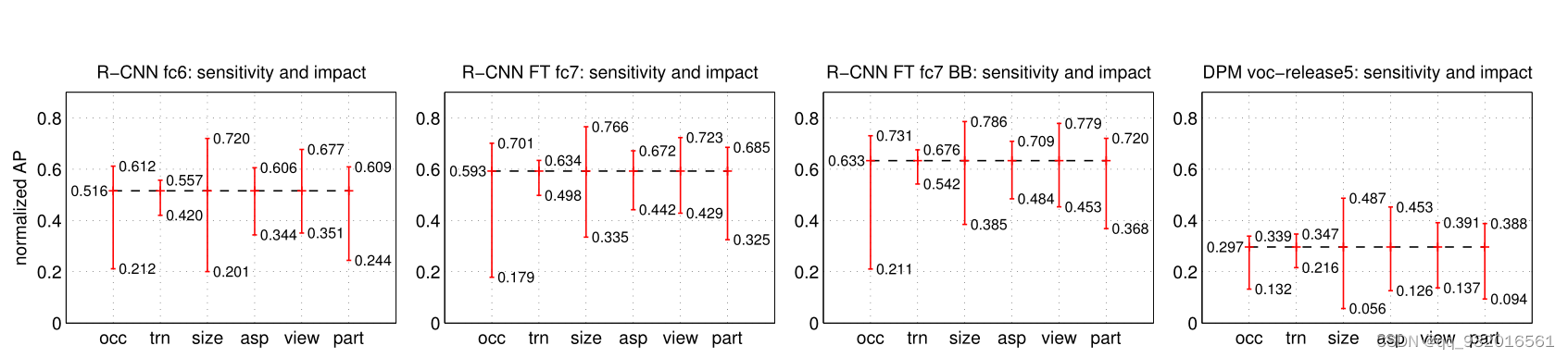
也是看了一下大佬们的解释,对每一张图片定义了如下的几种属性。
- Occlusion 被其他物体遮挡
- truncation 被其他物体截断
- bounding box area 标注框像素数量
- aspect ratio 标注框高宽比
- viewpoint 物体那些面可见
- part visibility 物体所有部分是否都可见
然后将上述这些指标放在图标的横坐标,其中纵坐标表示算法在该指标上的上下限,用红线连接该上下限。这个红线幅度用sensitivity表示。
也可以看出来在不断的改进模型 比如加BB加微调等之后,指标上下限都有所提升,最后的一个 是DPM模型,各项指标上下限都比较差。
所以这是想表明,全连接层学到了有用的东西,加上FN+BB+微调是最好组合?
5.Semantic segmentation(语义分割)
V5版本的论文,就是我在开头放的那个下载地址的版本论文,对比原始版新加入了第四章是介绍imagenet2013数据集的,主要是一些R-CNN配合imagenet数据集的概述,就略了,直接看第五章语义分割(对应原始论文第四章)。
语义分割就是将像素分类,直观到图上就是,目标检测画框是矩形框,而语义分割要做到画出轮廓。
这里就是将R-CNN模型用到了语义分割任务上面,说了一大堆和O2P等算法的对比实验过程,也没什么可看的。直接结论,R-CNN算法可以和O2P匹配,甚至超过一些。
作者最后的结论就是映照开头,说了一下那时候的很多方法对VOC没有什么大的突破,就我们的论文比较厉害,提出的方法对VOC有突破性进展。
附录这个图看一下:

在前面已经说过,送给CNN提取特征时的输入尺寸是227*227,所以对所有图片进行强制缩放, 附录这里给了几种缩放方法,最左边是原始图片,右边第一列是等比例缩放-连带周围像素,第二列是等比例缩放-不带周围像素,第三列是非等比例-不带周围像素。最后使用的连带邻近像素的非等比例缩放的方法(第三列的少许变形,连带周围16个像素)。
后面作者还检测了一下 imagenet和VOC重复的图片,大概有31张图片是重复的(fickr ID方法 ,就是一个图片网站),又换了一种算法 GIST,检测出来有38张重复图片 在imagenet2012和VOC2007,同为2012的情况下 有1.5%相同图片率。
为什么用SVM不用softmax?
作者正在最后的附录也说到这个问题,他们通过实验发现如果最后换成softmax性能相比较SVM会掉很多,原因就在于正负样本,在微调期间,正样本的框和真实框可能并不是重合的(IOU加入后),softmax在随机采样负样本上训练,而SVM加入‘错题本 hard negatives’机制,在错题本上训练,所以效果会好很多。
小总结
- 提出了两阶段目标检测算法。 1.提取候选框 2. 对候选框进行分类。
- 提候选框→CNN提特征→SVM分类。
- 迁移学习微调变成主流,对模型效果的提升是非常明显的。
- 提出了一个新的可视化中间层feature map 的方法 :只关注该feature map中的一个值,然后将全部候选框怼进去,看看那几个框能使得该值最大,则这些框就是当前神经元学习的信息。
- 加入回归方法可以有效降低定位错误。
- 通过预实验加入正负样本和不同IOU的配置(依赖于迁移模型数据,泛化能力差)。
- 微调时的与真实框(GT)的IOU最大且IOU大于0.5的候选框为正样本,其余负样本,训练SVM的时候,真实框(GT)为正样本,与GT的IOU小于0.3为负样本,忽略与GT的IOU大于0.3的候选框
整体看下来R-CNN并不高效,但在当时算是非常有效的一个模型了,这一点有点像VGG,不过R-CNN有非常多的后续版本,我觉得R-CNN要走VGG的老路变成方面教材R-CNN了。
文中所说的ground-truth其实就是人工标注出来的那个框,可以发现,如果人工标注的框lable出现较大偏差 甚至出错的情况下,模型精准度就会直线下降,怪不得说现在DL拼的不是模型而是数据。
最后
以上就是顺心皮皮虾最近收集整理的关于【目标检测 论文精读 】R-CNN (Rich feature hierarchies for accurate object detection and semantic segmentation)前言1.Abstract(摘要)2.Introduction(引言)3.Object detection with R-CNN(基于R-CNN的目标检测)4.Visualization, ablation, and modes of error(可视化,消融,错误模式)5.Semantic segm的全部内容,更多相关【目标检测内容请搜索靠谱客的其他文章。








发表评论 取消回复