文章目录
- 1、nn.Parameter() 模型参数包装
- 2、torch.Variable
- 3、torch.Tensor
- 4、Buffer
- 参考链接
1、nn.Parameter() 模型参数包装
Tensor的一种,常被用于模块参数(module parameter)。Parameters(参数) 是 Tensor 的子类。
A kind of Tensor that is to be considered a module parameter.
- Paramenters和Modules一起使用的时候会有一些特殊的属性,即:当Paramenters赋值给Module的属性的时候,他会自动的被加到 Module的 参数列表中(即:会出现在 parameters() 迭代器中)。
- 将Varibale赋值给Module属性则不会有这样的影响。 这样做的原因是:我们有时候会需要缓存一些临时的状态(state), 比如:模型中RNN的最后一个隐状态。如果没有Parameter这个类的话,那么这些临时变量也会注册成为模型变量。
- Variable 与 Parameter的另一个不同之处在于,Parameter不能被 volatile(即:无法设置volatile=True)而且默认requires_grad=True。Variable默认requires_grad=False。
Parameters:
- data (Tensor) – parameter tensor.
- requires_grad (bool, optional) – 是否在BP的过程中会对其求微分,默认为True
import torch
import torch.nn as nn
class LinerModel(nn.Module):
def __init__(self, ndim):
super(LinerModel ,self).__init__()
self.ndim = ndim
self.weight = nn.Parameter(torch.randn(ndim,1)) # 权重 w
self.bias = nn.Parameter(torch.randn(1)) # 偏置 b
def forward(self , x):
# y = Wx + b
y = x.mm(self.weight) + self.bias
return y
通过 nn.Parameter包装参数,使之成为子模块【仅由参数构成的子模块】,在后续训练的时候需要对参数进行微分优化,只有将张量转换为参数之后才可以在后续的优化过程中被优化器访问到。
首先可以把这个函数理解为类型转换函数,将一个不可训练的类型Tensor转换成可以训练的类型parameter并将这个parameter绑定到这个module里面(net.parameter()中就有这个绑定的parameter,所以在参数优化的时候可以进行优化的),所以经过类型转换这个self.v变成了模型的一部分,成为了模型中根据训练可以改动的参数了。使用这个函数的目的也是想让某些变量在学习的过程中不断的修改其值以达到最优化。
⚠️ 注意
self.v = torch.nn.Parameter(torch.FloatTensor(hidden_size)) 与 torch.tensor([1,2,3],requires_grad=True) 的区别
后者只是将参数变成可训练的,并没有绑定在module的parameter列表中,因此 无法被 optimizer 优化
- 我们可以直接将模型的成员变量 通过nn.Parameter() 创建,会自动注册到 parameters中,可以通过model.parameters() 返回,并且这样创建的参数会自动保存到OrderDict中去;
- 通过 nn.Parameter() 创建普通Parameter对象,不作为模型的成员变量,然后将Parameter对象通过register_parameter()进行注册,可以通model.parameters() 返回,注册后的参数也会自动保存到OrderDict中去
2、torch.Variable
Pytorch 在 0.4版本中 实现了 Tensor 与 Variable 的合并,在此之前的版本中,这两个概念是相互独立的
Variable变量 是可以构建计算图且 能够进行自动求导的张量。
在 Pytorch 0.4版本中,通过指定张量支持导数的选项,便不再需要用到 Variable。
# 将旧版本 Variable 改为新版本tensor
Variable(data) ——> tensor( data , requires_grad=True )
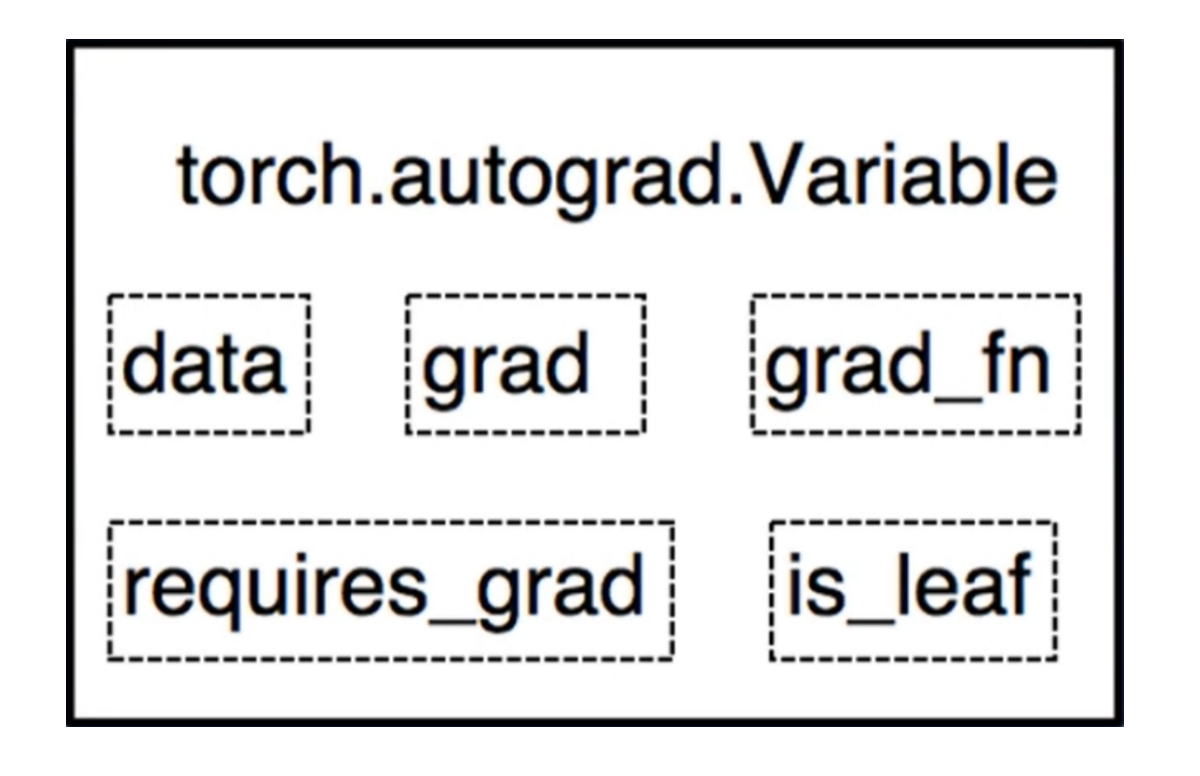
- grad:data 的梯度
- grad_fn:记录 创建该张量 所使用的方法/函数
- requires_grad:是否需要梯度/微分
- is_leaf:是否是叶子结点

3、torch.Tensor
torch.tensor() always copies data. If you have a Tensor data and just want to change its requires_grad flag, use requires_grad_() or detach() to avoid a copy. If you have a numpy array and want to avoid a copy, use torch.as_tensor().
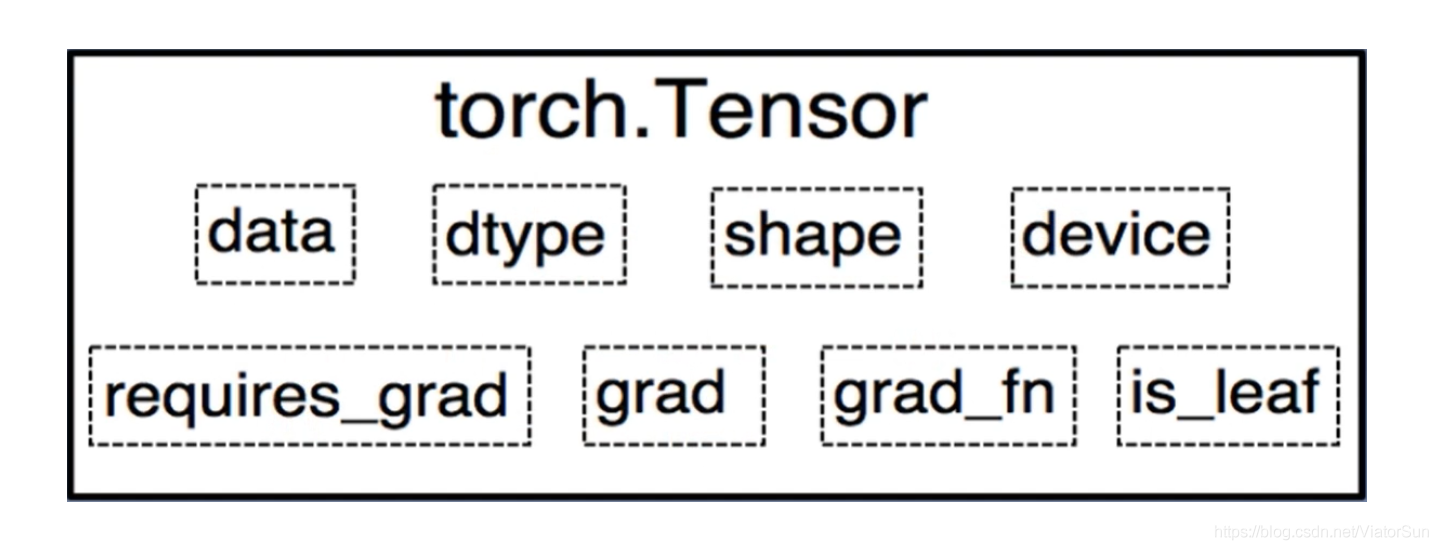
- dtype:data的数据类型
- shape:data的形状
- device:data 存储/运行设备
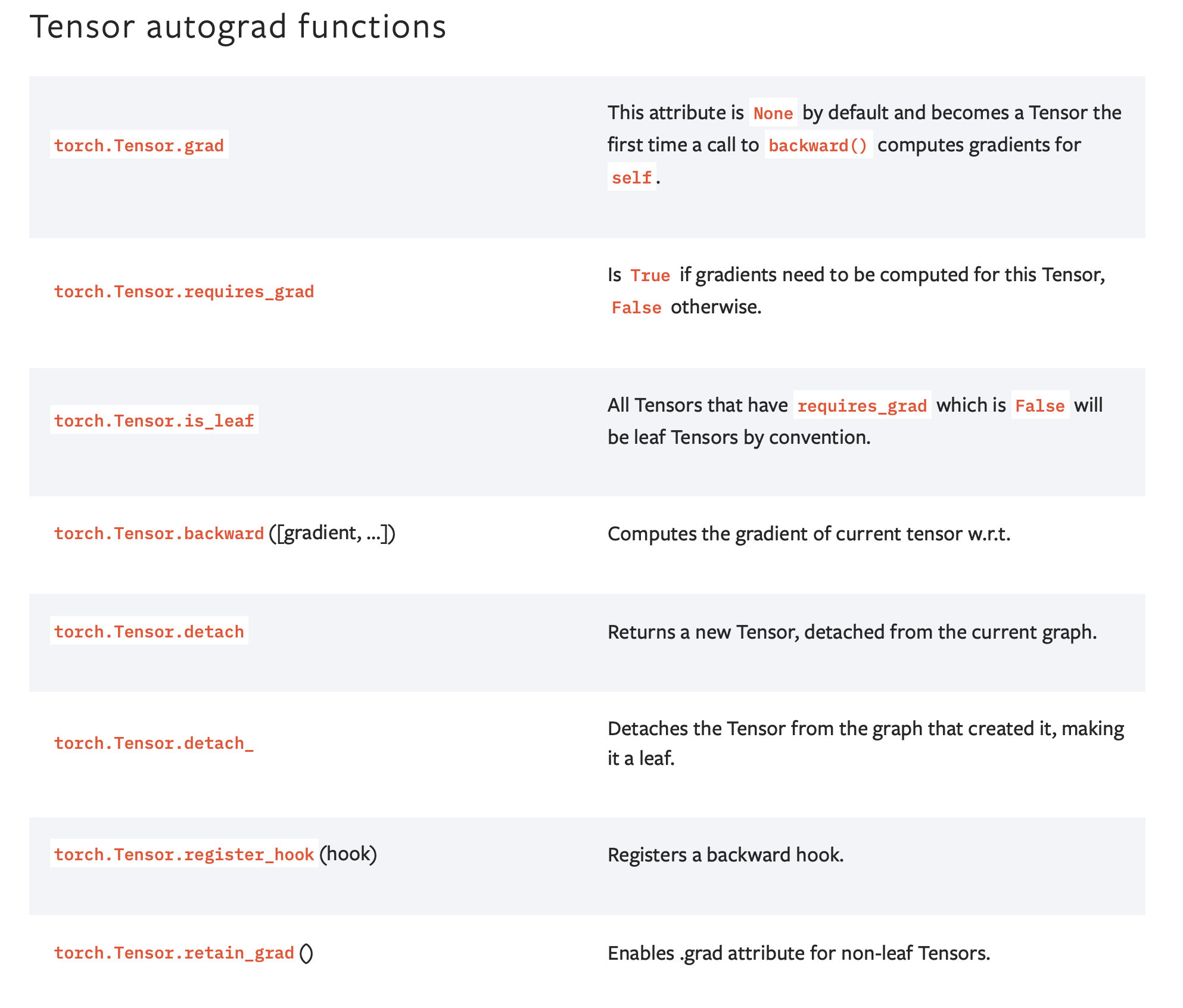
4、Buffer
Buffer: buffer和parameter相对,就是指那些不需要参与反向传播的参数
参考链接
- https://www.jianshu.com/p/d8b77cc02410
最后
以上就是无语裙子最近收集整理的关于【细聊】Pytorch 里面的 Tensor/Parameter/Variable/Buffer1、nn.Parameter() 模型参数包装2、torch.Variable3、torch.Tensor4、Buffer参考链接的全部内容,更多相关【细聊】Pytorch内容请搜索靠谱客的其他文章。








发表评论 取消回复