目录
- Ⅰ. 数据读取器
- 1. 训练集
- 2. 验证集和测试集
- Ⅱ. 搭建网络
- Ⅲ. 模型训练
- 1. 开始训练
- 2. 模型验证
- Ⅲ. 模型测试
- Ⅳ. 绘制图像
- Ⅴ. 完整代码
MNIST 数据集,其包含70000 个28×28 的手写数字的数据集,其中又分为60000 个训练样本与10000 个测试样本。
Ⅰ. 数据读取器
import torch
from torch import nn
from torch import optim
from torch.nn.parameter import Parameter
import torchvision
import torchvision.transforms as transforms
import torch.nn.functional as F
import random
# 在需要生成随机数的程序中,确保每次运行程序所生成的随机数都是固定的,使得实验结果一致
torch.manual_seed(1)
batch_size_train = 64
batch_size_valid = 64
batch_size_test = 1000
1. 训练集
下载训练集
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])
trainset = torchvision.datasets.MNIST(root='./data', train=True, download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=batch_size_train)
2. 验证集和测试集
官方的MNIST 数据集当中是没有划分验证集的,但为了使训练结果更加直观,我选择将10000 个测试样本当中的5000 个划分为验证集,剩下5000 个依然为测试集。在此需要使用torch.utils.data.sampler.SubsetRandomSampler() 函数进行抽样。
首先获取测试样本的索引
testset = torchvision.datasets.MNIST(root='./data', train=False, download=True, transform=transform)
indices = range(len(testset))
然后对该索引进行划分,前5000 个样本作为验证集,后5000 个作为测试集
# 测试集中再取出一半作为验证集
indices_valid = indices[:5000]
sampler_valid = torch.utils.data.sampler.SubsetRandomSampler(indices_valid)
validloader = torch.utils.data.DataLoader(testset, batch_size=batch_size_valid, sampler=sampler_valid)
indices_test = indices[5000:]
sampler_test = torch.utils.data.sampler.SubsetRandomSampler(indices_test)
testloader = torch.utils.data.DataLoader(testset, batch_size=batch_size_test, sampler=sampler_test)
为了对MNIST 手写数字样本有一个更加直观的了解,在此我们输出部分样本来看看
import matplotlib.pyplot as plt
examples = enumerate(trainloader)
batch_idx, (example_data, example_targets) = next(examples)
fig = plt.figure()
for i in range(6):
plt.subplot(2, 3, i+1)
plt.tight_layout()
plt.imshow(example_data[i][0], cmap='gray', interpolation='none')
plt.title('Ground Truth: {}'.format(example_targets[i]))
plt.xticks([])
plt.yticks([])
plt.show()
print(example_data.shape)

Ⅱ. 搭建网络
我们需要搭建一个卷积神经网络,其对于训练这种像素间具有一定空间位置关系的图片样本来说非常合适。
class CNNNet(nn.Module):
def __init__(self):
super(CNNNet, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(1, 10, kernel_size=3),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(10, 20, kernel_size=4),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2)
)
self.classifier = nn.Sequential(
nn.Dropout(),
nn.Linear(500, 50),
nn.ReLU(),
nn.Dropout(),
nn.Linear(50, 10),
nn.LogSoftmax(dim=1)
)
def forward(self, x):
x = self.features(x)
x = torch.flatten(x, 1)
x = self.classifier(x)
return x
由于我们的训练样本是灰度图,其只有一个通道,因此第一个卷积层输入为一个维度,输出为十个维度,卷积核大小为3。图像经过第一个卷积层后输出的特征图大小为26×26,一共有十个维度。然后经过池化层后大小变成13×13。又经过一个输入十个维度,输出二十个维度,卷积核大小为4的卷积层与一个池化层后,输出的特征图大小为5×5,一共有20个维度,此时特征图一共包含5×5×20=500个特征。
随后这500个特征经过两个全连接层输出为10个维度,即对应0-9十个数字的分类结果。
Ⅲ. 模型训练
net = CNNNet()
if torch.cuda.is_available():
device = torch.device('cuda')
else:
device = torch.device('cpu')
net.to(device)
trainloader, validloader, testloader = get_data()
在训练模型之前,我们还需要做几件事情:1)定义损失函数;2)定义优化器。
# 损失函数——交叉熵损失
loss_fn = nn.CrossEntropyLoss()
# 优化器——Adam 优化器,学习率为0.01
optimizer = optim.Adam(net.parameters(), lr=0.01)
1. 开始训练
- 获取输出;
- 梯度清零;
- 计算损失;
- 反向传播;
- 参数优化
for epoch in range(1, epochs+1):
model.train()
for train_idx, (inputs, labels) in enumerate(train_loader, 0):
inputs = inputs.to(device)
labels = labels.to(device)
# 1.获取输出
outputs = model(inputs)
# 2.梯度清零
optimizer.zero_grad()
# 3.计算损失
loss = loss_fn(outputs, labels)
# 4.反向传播
loss.backward()
# 5.参数优化
optimizer.step()
# 打印训练信息
if train_idx % 10 == 0:
train_losses.append(loss.item())
counter_index = train_idx * len(inputs) + (epoch-1) * len(train_loader.dataset)
train_counter.append(counter_index)
print('epoch: {}, [{}/{}({:.0f}%)], loss: {:.6f}'.format(
epoch, train_idx*len(inputs), len(train_loader.dataset), 100*(train_idx*len(inputs)+(epoch-1)*len(train_loader.dataset))/(len(train_loader.dataset)*(epochs)), loss.item()))
2. 模型验证
# validation
if train_idx % 300 == 0:
model.eval()
valid_loss = []
for valid_idx, (inputs, labels) in enumerate(valid_loader, 0):
inputs = inputs.to(device)
labels = labels.to(device)
outputs = model(inputs)
loss = loss_fn(outputs, labels)
valid_loss.append(loss.item())
# 平均损失
valid_losses.append(np.average(valid_loss))
valid_counter.append(counter_index)
print('validation loss: {:.6f} counter_index: {}'.format((np.average(valid_loss)), counter_index))
print('training ended')
train(net, optimizer, loss_fn, trainloader, validloader, epochs=2)
部分输出结果

Ⅲ. 模型测试
# 平均测试损失
test_loss_avg = 0
def test(model, test_loader, loss_fn, device='cpu'):
correct = 0
total = 0
test_loss = []
with torch.no_grad():
for train_idx, (inputs, labels) in enumerate(test_loader, 0):
inputs = inputs.to(device)
labels = labels.to(device)
outputs = net(inputs)
loss = loss_fn(outputs, labels)
test_loss.append(loss.item())
index, value = torch.max(outputs.data, 1)
total += labels.size(0)
correct += int((value==labels).sum())
test_loss_avg = np.average(test_loss)
print('Total: {}, Correct: {}, Accuracy: {:.2f}%, AverageLoss: {:.6f}'.format(total, correct, (correct/total*100), test_loss_avg))
test(net, testloader, loss_fn)
结果
Total: 5000, Correct: 4940, Accuracy: 98.80%, AverageLoss: 0.035709
一共测试了5000 个样本,其中预测正确的样本数量为4940,下面是部分预测结果
examples = enumerate(testloader)
batch_idx, (inputs, targets) = next(examples)
with torch.no_grad():
outputs = net(inputs)
fig = plt.figure()
for i in range(0, 50):
# 在前一百个测试样本当中找寻预测结果与标签不一致的样本
#if(targets[i].item() != outputs.data.max(1, keepdim=True)[1][i].item()):
print(i)
plt.subplot(5, 10, i+1)
plt.imshow(inputs[i][0], cmap='gray', interpolation='none')
plt.title('GroundTruth: {} Prediction: {}'.format(targets[i], outputs.data.max(1, keepdim=True)[1][i].item()))
plt.xticks([])
plt.yticks([])
plt.show()

可以看到中间那个“6” 被错误预测成了“0”。
我们也可以输入自己的手写数字进行识别
import cv2
import os
rootdir = 'C:/my_handwriting'
list = os.listdir(rootdir) # 列出文件夹下所有的目录与文件
for i in range(0, len(list)):
path = os.path.join(rootdir, list[i])
img = cv2.imread(path, 0)
height,width=img.shape
dst=np.zeros((height,width),np.uint8)
# 像素反转
for i in range(height):
for j in range(width):
dst[i,j]=255-img[i,j]
# 修改尺寸
if height != 28 or width != 28:
img = cv2.resize(dst, (28, 28))
# 保存图片
cv2.imwrite(path, dst)


输入模型:
from torch.autograd import Variable
import torch.nn.functional as F
img = cv2.imread('C:/my_handwriting/53.jpg', 0)
img = np.array(img).astype(np.float32)
img = np.expand_dims(img, 0)
img = np.expand_dims(img, 0)
img = torch.from_numpy(img)
img = img.to(device)
output = net(Variable(img))
prob = F.softmax(output, dim=1)
prob = Variable(prob)
prob = prob.cpu().numpy()
print(prob)
pred = np.argmax(prob)
print(pred.item())
Ⅳ. 绘制图像
import matplotlib.pyplot as plt
fig = plt.figure()
plt.plot(train_counter, train_losses, color='blue')
plt.plot(valid_counter, valid_losses, color='red')
plt.scatter(train_counter[-1], test_loss_avg, color='green')
plt.legend(['Train Loss', 'Valid Loss', 'Test Loss'], loc='upper right')
plt.xlabel('Training images number')
plt.ylabel('Loss')
plt.show()
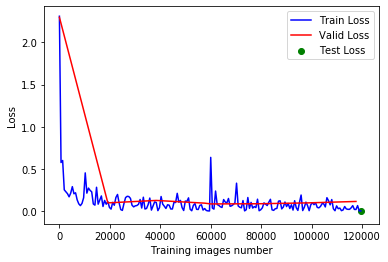
从图像中可以观察到,模型训练结果还是不错的,至少从验证集的结果来看并没有很明显的过拟合现象。而且最终的测试结果也较为理想。
Ⅴ. 完整代码
handwriting_detection.py
最后
以上就是苹果棒棒糖最近收集整理的关于PyTorch——手写数字识别Ⅰ. 数据读取器Ⅱ. 搭建网络Ⅲ. 模型训练Ⅲ. 模型测试Ⅳ. 绘制图像Ⅴ. 完整代码的全部内容,更多相关PyTorch——手写数字识别Ⅰ.内容请搜索靠谱客的其他文章。








发表评论 取消回复