来自 | 专知&知乎
链接 | mp.weixin.qq.com/s/QpwExdQi_lLvH26wvWqmEA
链接 | https://zhuanlan.zhihu.com/p/181677461
编辑 | 机器学习与推荐算法公众号
第29届国际计算机学会信息与知识管理大会CIKM2020将于2020年10月19日-10月23日在线上召开。CIKM是CCF推荐的B类国际学术会议,是信息检索和数据挖掘领域顶级学术会议之一。本届CIKM会议共收到投稿920篇,其中录用论文193篇,录取率约为21%。此次整理的论文大部分来自人大、清华和华为。

1
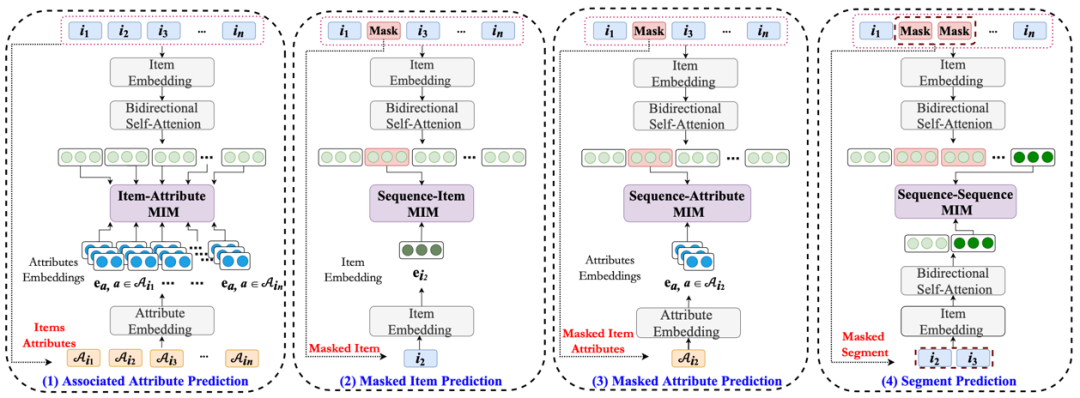
题目:S3-Rec: Self-Supervised Learning for Sequential Recommendation with Mutual Information Maximization
作者:周昆,王辉,赵鑫,朱余韬,王思睿,张富铮,王仲远,文继荣
概述:近年来,深度学习在序列化推荐领域取得了巨大成功,已有的序列化推荐模型通常依赖于商品预测的损失函数进行参数训练。但是该损失函数会导致数据稀疏和过拟合问题,其忽视了上下文数据与序列数据之间的关联,使得数据的表示学习的并不充分。为解决该问题,本文提出了S3-Rec这一模型,该模型基于自注意力模型框架,利用四个额外的自监督训练函数来学习属性、商品、序列之间的特殊关系。在这里,本文采用了互信息最大化技术来构造这些自监督函数,以此来统一这些关系。在六个数据集上的充分实验表明本文提出的模型能够取得State-of-the-art的效果,其在数据量受限和其他推荐模型上也能带来较大的提升。关于自监督学习可参考Self-Supervised Learning论文整理。
2
题目:Diversifying Search Results using Self-Attention Network
作者:秦绪博,窦志成,文继荣
概述:搜索结果多样化的目标是使得检索得到的结果能够尽量覆盖用户提出问题的所有子话题。已有的多样化排序方法通常基于贪心选择(Greedy Selection)过程,独立地将每一个候选文档与已选中的文档序列进行比较,选择每一个排序位置的最佳文档,生成最后的文档排序。而相关研究证明由于各候选文档的边际信息收益并非彼此独立,贪心选择得到的各个局部最优解将难以导向全局最佳排序。本文介绍了一种基于自注意力网络(Self-Attention Network)的方法,可以同步地衡量全体候选文档间的关系,以及候选文档对不同用户意图的覆盖程度,有效地克服原有方法受限于贪心选择过程的局限性,并在TRECWebTrack09-12数据集上获得更好的性能。

3
题目:PSTIE: Time Information Enhanced Personalized Search
作者:马正一,窦志成,边关月,文继荣
概述:基于深度学习的个性化搜索模型通过序列神经网络(例如RNN)对用户搜索历史进行序列建模,归纳出用户的兴趣表示,取得了当前最佳的效果。但是,这一类模型忽略了用户搜索行为之间细粒度的时间信息,而只关注了搜索行为之间的相对顺序。实际上,用户每次查询之间的时间间隔可以帮助模型更加准确地对用户查询意图与文档兴趣的演化进行建模。同时,用户历史查询与当前查询之间的时间间隔可以直接帮助模型计算用户的重查找(re-finding)行为概率。基于此,本文提出了一个时间信息增强的个性化搜索模型。我们设计了两种时间感知的LSTM结构在连续时间空间中对用户兴趣进行建模,同时直接将时间信息利用在计算用户重查找概率中,计算出了更加准确的用户长短期兴趣表示。我们提出了两种将用户兴趣表示用于个性化排序的策略,并在两个真实数据集上取得了更好的效果。

4
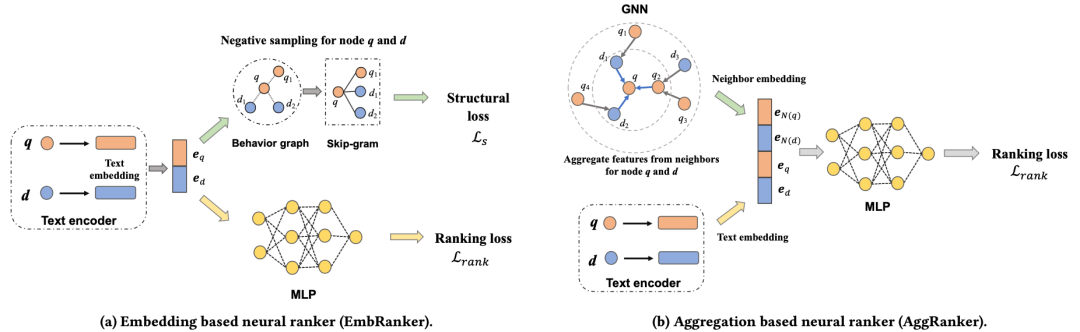
论文:Learning Better Representations for Neural Information Retrieval with Graph Information
作者:李祥圣,Maarten de Rijke, 刘奕群,毛佳昕,马为之,张敏,马少平
概述:目前的检索模型多数基于文本间的匹配。然而,对于一个搜索会话,用户的行为之间是具有联系的,这样的联系可以用图的方式表示出来。例如用户在会话搜索中修改查询的过程可以知道那些查询之间是相似的,用户点击文档后,可以知道查询与文档之间的关联性。利用这样的两个网络,我们可以构建一个由用户行为组成的图网络。在传统的文本匹配模式上,进一步地引入行为图信息帮助检索模型更好地理解用户搜索意图。检索模型可以利用图信息,对输入的查询进行相似节点查询。同理,对于候选文档也可以利用相似节点查询。通过引入邻接节点信息,丰富当前节点的语义表示。
现有的图模型的工作主要分为两种:网络嵌入式表示方法与图神经网络方法。基于这两种方法,我们提出了两种利用图信息改进检索模型的方法,两种方法的示意图如下所示:
5
题目: GraphSAIL: Graph Structure Aware Incremental Learning for Recommender Systems
概述:推荐系统可以帮助用户很方便的从在线服务中获取想要的信息,在提升用户体验方面起着越来越重要的作用,也累计了越来越多的用户数据。随着图神经网络(GNNs)的出现,基于用户-物品二部图来学习用户、物品表达展现出了巨大的优势。但是,GNN模型的训练复杂度很高,难以频繁地更新以提供最新的用户、物品个性化表达。在本研究中,我们提出通过增量的方式更新基于GNN的推荐模型,以大大缩短训练时间,从而可以更频繁地更新模型。我们设计了一种图结构感知增量学习框架GraphSAIL,以克服在增量方式训练模型时常常出现的灾难性遗忘问题。GraphSAIL实现了一种可以保存每个节点的局部结构、全局结构和自信息的图结构信息保存策略,从而在增量更新期间可以更好的保留用户的长期偏好(以及物品的长期属性)。GraphSAIL是首个对基于GNN的推荐模型进行增量更新的框架,在两个公共数据集上与其它增量学习技术的对比展示出了GraphSAIL的优越性。我们进一步在大规模工业数据集上验证了我们的框架的有效性。
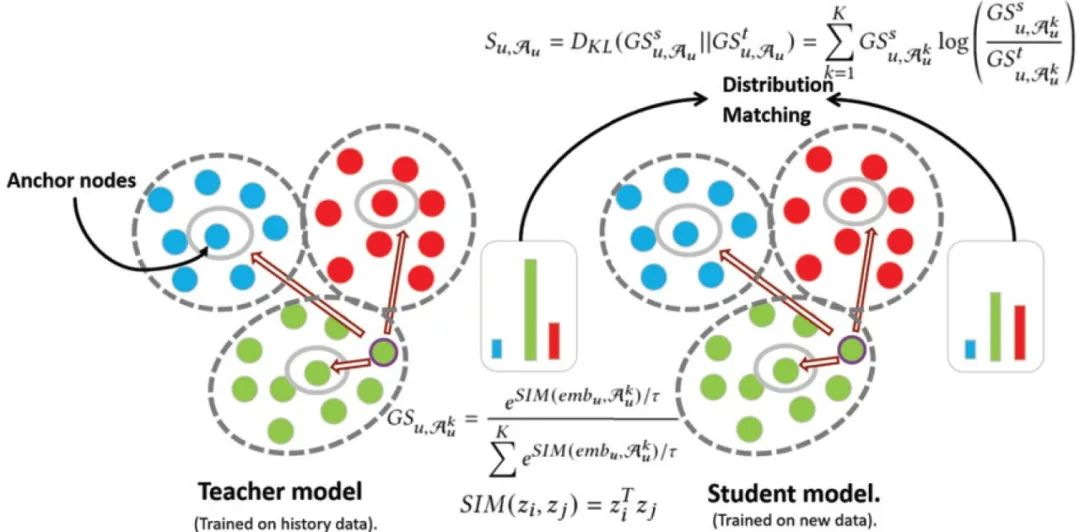
图1:GraphSAIL全局结构蒸馏示例
6
题目:Personalized Re-ranking with Item Relationships for E-commerce
概述:在大规模商用推荐系统中,重排序(re-ranking)是一项非常关键的任务。重排序模型在已有初始排序的基础上,进行更精细的排序建模,以提高最终推荐结果的准确性。但是,现有的推荐重排序模型大多忽略了以下两个问题:(1)忽略了列表中商品与商品之间的相互关系和影响,例如拥有可替代(substitutable)或者互补(complementary)关系的商品出现在同一列表中,会影响到用户对于另一商品的满意度;(2)对所有用户使用单一的重排序策略,而忽略了用户个性化的偏好和意图。为了解决这些问题,我们构造了一个异构图来融合初始排序信息和商品关系信息。我们设计了一个基于图神经网络的框架IRGPR,通过递归的方式逐步聚合来自多跳邻域的依赖关系和结构信息。同时,我们还提出了一个新颖的意图嵌入网络,对个性化的用户意图进行显式建模。大量在真实数据集上的实验证实了IRGPR在重排序任务上的有效性。进一步分析表明,对商品关系和个性化意图建模有助于提升重排序的推荐效果。【诺亚推荐与搜索团队自研成果】
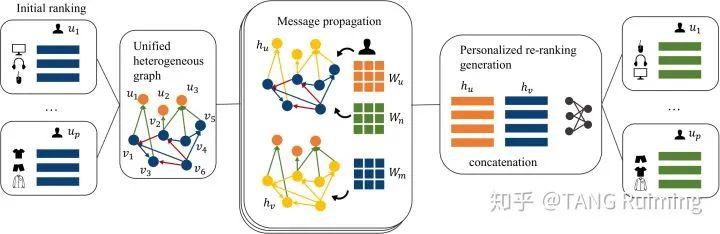
图2:IRGPR模型结构
7
题目:TGCN: Tag Graph Convolutional Network for Tag-Aware Recommendation
概述:标签感知推荐系统 (Tag-aware recommender systems)利用了用户对物品的标注标签作为一种辅助信息来提升推荐性能,传统的基于深度学习的标签感知推荐模型单纯依靠基于标签的特征来表征用户和物品,这种方式难以有效解决标签空间的稀疏性、模糊性和冗余性等弊端。为了解决这个问题,我们将用户的标注记录以无向带权异构图的形式进行组织,通过邻居来提供额外的内容信息。在本工作中,我们提出了一个基于图神经网络的模型TGCN。TGCN针对不同类型的邻居节点采用不同的采样和聚合操作,并利用注意力网络来识别邻居和节点类型的重要性。此外,利用卷积神经网络作为类型聚合方式从而建模多粒度的特征交互。我们在公开数据集和产品数据集进行验证,TGCN模型在各个评价指标上均优于现有的标签感知推荐模型。【诺亚推荐与搜索团队自研成果】
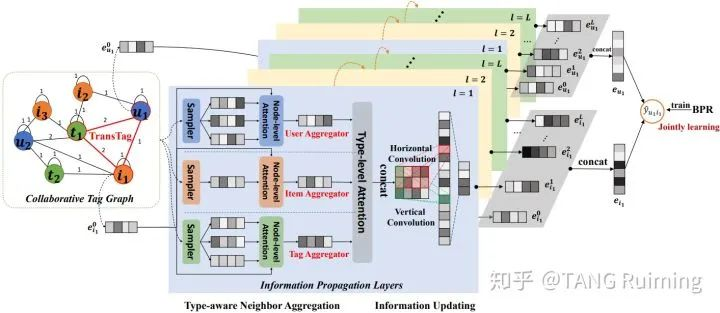
图3:TGCN模型结构
8
题目:U-rank: Utility-oriented Learning to Rank with Implicit Feedback
概述:使用隐式反馈进行排序学习是许多现有信息系统、推荐系统最重要的任务之一。信息系统、推荐系统一般都有特定的优化目标,例如,增加点击量和提高收入。我们泛称该优化目标为收益。很多时候,我们希望有一个算法能够直接最优化收益。然而,现有的排序算法原则并不能够最大化收益。为此,我们提出了一种新型排序框架,U-rank,将期望收益最大化的问题建模为物品和位置的二分图最大权重匹配问题。该框架考虑位置偏置对收益的影响,通过借助位置感知的深度点击率预测模型,计算二分图的权重为在特定query下该物品被放到某个位置的收益。我们借鉴了有效的Lambdaloss框架来最大化该二分图匹配问题,这个框架得到了理论和经验分析的支持。我们在三个benchmark数据集和二个的私有数据集上进行了大量的实验,充分展示了U-rank在优化收益的目标上表现优于许多state-of-the-arts算法。此外,U-rank已经部署到一个商业推荐系统,线上A/B测试中观察到U-rank相对生产基线大幅提升了点击率和转化率。【诺亚推荐与搜索团队,上海交大Apex实验室俞勇/张伟楠老师团队联合研究成果】
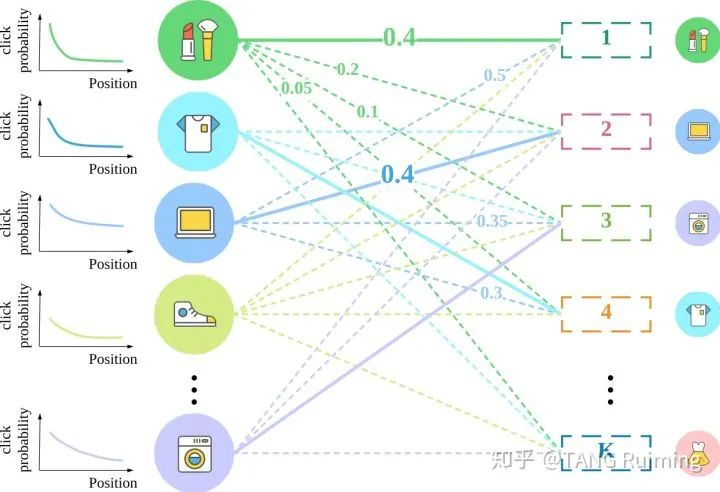
图4:将排序问题建模成二分图最大权重匹配问题
9
题目:AutoFeature: Searching for Feature Interactions and Their Architectures for Click-through Rate Prediction
概述:点击率预测问题是商业推荐系统中一个重要研究课题。而在这个课题中中,如何有效建模特征交互是一个核心研究点。但是,现有的方案要么对于某一阶交互建模了所有可能的特征交互,要么需要人工去选择特征交互。这些模型使用了相同的网络结构或者函数去建模所有的特征交互,从而忽略了不同特征交互之间复杂度的不同。为了解决这些问题,我们提出了一个基于神经网络架构搜索的模型AutoFeature,去自动化的找到潜在有用的特征交互,并且选择合适的神经网络结构去建模不同的特征交互。首先,我们设计了一个灵活的搜索空间,使得覆盖了很多流量的深度推荐模型如PIN,PNN,DeepFM等,并且能够建模高阶特征交互。其次,我们提出了一个高效的神经网络架构检索算法,能够迭代循环的将搜索空间划分成多个子空间,并且从中采样出高质量的神经网络结构。我们在公开数据集上进行了充分的实验,验证了AutoFeature的精度和效率。【诺亚推荐与搜索团队,AI基础理论团队联合研究成果】
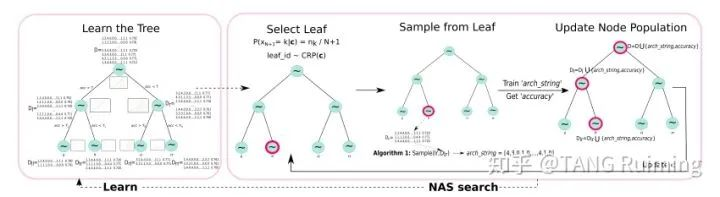
图5:AutoFeature的神经网络架构搜索流程图
参考链接:
http://ai.ruc.edu.cn/newslist/newsdetail/20200818001.html
https://zhuanlan.zhihu.com/p/181677461
喜欢的话点个在看吧????
最后
以上就是幸福白猫最近收集整理的关于CIKM2020 | 最新9篇推荐系统相关论文的全部内容,更多相关CIKM2020内容请搜索靠谱客的其他文章。








发表评论 取消回复