预训练-微调方法指的是首先在大数据集上训练得到一个具有强泛化能力的模型(预训练模型),然后在下游任务上进行微调的过程。
预训练-微调方法属于基于模型的迁移方法(Parameter/Model-based TransferLearning)。
该大类方法旨在从源域和目标域中找到它们之间共享的参数信息以实现迁移。
此迁移方式要求的假设条件是:源域中的数据与目标域中的数据可以共享一些模型的参数。
下图形象地表示了基于模型的迁移学习方法的基本思想。
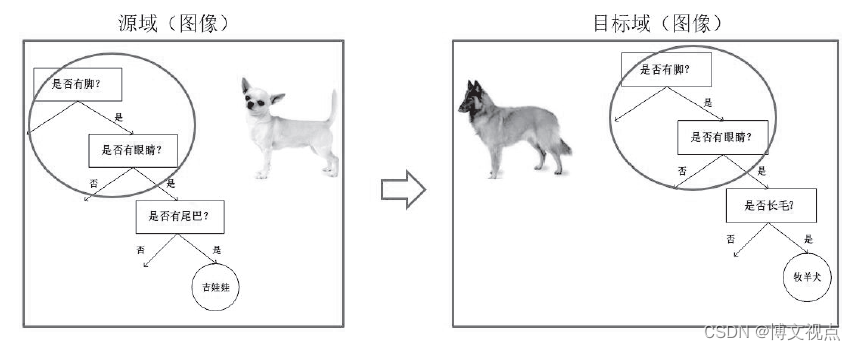
预训练-微调的模式为何重要
因为其他任务上训练好的模型可能并不完全适用于自己的任务:可能上游训练数据与下游数据不服从同一个分布;可能已有的预训练网络较复杂、而我们的任务比较简单,等等。
例如,对训练一个猫狗图像二分类的神经网络最有参考价值的便是在CIFAR-100上训练好的神经网络。
然而,CIFAR-100 有100个类别,此任务只需2个类别。此时便需要针对自己的任务固定原始网络的相关层且修改网络的输出层,以使结果更符合我们的需要。
综上,微调具有如下优势:
不需要针对新任务从头开始训练网络,节省了时间成本;
预训练好的模型通常都是在大数据集上进行的,无形中扩充了我们的训练数据,使得模型更鲁棒、泛化能力更好;
微调实现简单,使我们只关注自己的任务即可。
一些学者着眼于重新思考预训练模型的有效性。何恺明等人发表于ICCV2019 的工作就对计算机视觉领域的ImageNet 预训练进行了大量的实验。他们通过实验得到结论:在相同的任务上,预训练模型与从头开始训练(Train fromscratch)相比,大大缩短了训练时间且加快了训练的收敛速度。在结果的提升上,他们的结论是,预训练模型只会对最终的结果有着微小的提升。
另一项工作则深入思考了预训练模型对于迁移任务的作用并得出以下结论:
在大型数据集(如ImageNet)上,预训练的性能决定了下游迁移任务的下限,即预训练模型可以作为后续任务的基准模型;
在细粒度(Fine-grained)任务上,预训练模型无法显著提高最终的结果;
与随机初始化相比,当训练数据集显著增加时预训练带来的提升会越来越小。即当训练数据较少时预训练能够带来较为显著的性能提升。
另一些学者则在模型的鲁棒性等方面继续探索预训练模型带来的提升。Using pre-training can improve model robustness and uncertainty做了一系列预训练模型的实验,最终认为预训练模型可以在以下场景中提高模型的鲁棒性:
对于标签损坏(Label Corruption)的情况,即噪声数据,预训练模型可以提高最终结果的AUC(Area Under Curve);
对于类别不均衡任务,预训练模型提高了最终结果的准确性;
对于对抗扰动(Adversarial Perturbation)的情况,预训练模型可以提高最终结果的准确性;
对于不同分布的数据(Out-of-distribution),预训练模型带来了巨大的效果提升;
对于校准(Calibration)任务,预训练模型同样能提升结果置信度。
预训练-微调的应用
预训练模型已经在计算机视觉、自然语言处理和语音识别等任务上得到了广泛的应用。
预训练模型可以获得大量任务的通用表现特征,那么能否直接将预训练模型作为特征提取器,从新任务中提取特征从而可以进行后续的迁移学习呢?
这种方法类似于从一个强大的模型中提取特征表达嵌入(Embedding),继而利用这些特征开展进一步的工作。
例如,计算机视觉中著名的DeCAF方法就为视觉任务提供了一种从预训练模型中提取高级特征的通用方法。在小样本学习中,特征嵌入+ 模型构建的两阶段方法在近年来取得了不错的效果。
这促使我们重新思考预训练模型的使用方法:如果将从源域数据中学到的模型在目标域上直接提取特征,然后利用源域和目标域的特征构建模型,能否取得更好的效果?
令人惊奇的是,通过深度网络提取的特征配合传统机器学习方法在领域自适应任务上竟然可以取得比端到端的深度迁移学习更好的结果。
Wang等人提出了一种叫做EasyTL(Easy Transfer Learning)的迁移方法。该方法首先利用在有标记源域数据上微调的预训练模型分别在源域和目标域上提取有表现力的高阶特征,然后基于这些提取好的特征进行后续的特征变换和简单的分类器构建。
令人欣喜的是,尽管EasyTL 方法并未涉及相对重量级的深度迁移策略,却在当时取得了很好的效果。例如,EasyTL 方法采用基于ImageNet数据集预训练的ResNet-50 网络进行特征提取,取得了比绝大多数基于ResNet进行深度迁移的方法更好的效果,如下图所示。

我们给出深度学习中可能的预训练模型的应用方法:
用法1:预训练网络直接应用于新任务;
用法2:预训练-微调,此即使用最广泛的方法;
用法3:预训练网络充当新任务的特征提取器,例如DeCAF等;
用法4:预训练提取特征加分类器构建,以专注于利用高阶特征来构建后续的分类器。
以上内容出自《迁移学习导论(第2版)》,更多相关内容欢迎阅读此书。

本书第1版一经上市便引起极大反响,好评如潮。



在第2版中,作者们基于初版读者的反馈对初版进行了大刀阔斧的修改:添加了新的内容、调整了内容结构使其更易阅读、加入了新的应用实践代码使其更易上手、重新整理修改了所有代码从而保证了可复现性。
新版升级了哪些内容?
首先,第2版包含了第1版的所有内容。
其次,在此基础上,经过众多读者火眼金睛的审视,作者听取建议、不断修改,打磨出了更好的结构、更多的升级内容。
新增:“安全和鲁棒的迁移学习”一章,包括安全迁移学习、无需源数据的迁移学习等新主题和联邦学习等更丰富的内容,在新版第12 章;
新增:“复杂环境中的迁移学习”一章,包括类别非均衡的迁移学习、多源迁移学习等内容,在新版第13 章;
新增:“低资源学习”一章,包括新增的迁移学习模型压缩、半监督学习、自监督学习等主题,并修改了初版“元学习”一章的内容,在新版第14 章;
新增:迁移学习在计算机视觉、自然语言处理、语音识别、行为识别、医疗健康五个方面的代码实践,在新版第15 章至第19 章。
新增:迁移学习模型选择,在新版第7 章;
新增:迁移学习中的正则,在新版第8 章;
新增:基于最大分类器差异的对抗迁移方法,在新版第10章;
新增:更全面的领域泛化的方法,在新版第11 章;
新增:领域泛化的理论介绍,在新版第11 章;
调整:全新整理的每章代码和数据集仓库,更好地上手实践复现;
调整:将初版的第2 章、第3 章、第4 章部分内容合并为一章,在新版第2 章;
调整:将初版的第15 章调整到第1 章的应用部分;
调整:将初版第4 章“迁移学习理论”部分与第14 章“迁移学习模型选择”部分合并为一章,在新版第7 章;
调整:为方便参考,将每章的参考文献单独放在章节之后;
修改:修改了所有之前的内容表述和存在的错误。
因此,第2版可以完全取代第1版。

最后
以上就是拼搏自行车最近收集整理的关于了解“预训练-微调”,看这一篇就够了的全部内容,更多相关了解“预训练-微调”内容请搜索靠谱客的其他文章。








发表评论 取消回复