极限 limitation
极限存在的充要条件:
lim
x
−
>
x
0
f
(
x
)
=
A
的
充
要
条
件
是
lim
x
−
>
x
0
−
f
(
x
)
=
lim
x
−
>
x
0
+
f
(
x
)
=
A
lim _{x->x_0}f(x)=A的充要条件是lim _{x->x_0^-}f(x)=lim _{x->x_0^+}f(x)=A
x−>x0limf(x)=A的充要条件是x−>x0−limf(x)=x−>x0+limf(x)=A,即左极限=右极限.
- 连续
f ( x ) 在 x = x 0 f(x)在x=x_0 f(x)在x=x0处连续的定义为: lim x − > x 0 f ( x ) = f ( x 0 ) lim _{x->x_0}f(x)=f(x_0) x−>x0limf(x)=f(x0)
导数 derivative
对于函数
y
=
f
(
x
)
y=f(x)
y=f(x),导数的定义是
f
′
(
x
0
)
=
lim
Δ
x
−
>
0
f
(
x
0
+
Δ
x
)
−
f
(
x
0
)
Δ
x
(1)
f'(x_0)=lim_{Delta x->0} frac {f(x_0+Delta x)- f(x_0)} {Delta x} tag 1
f′(x0)=Δx−>0limΔxf(x0+Δx)−f(x0)(1)
可以看到它本质是一个极限, 是标量, 其几何意义为 点
x
0
x_0
x0处的斜率.
偏导数
自变量扩展为多元 x mathbb x x 时, 可对某一维 x i x_i xi 单独计算其导数 ∂ f ∂ x i frac {partial f} {partial x_i} ∂xi∂f, 称为 偏导数.
方向导数
directional derivative. 很多时候, 仅有坐标轴方向上的偏导数是不够的, 我们还想知道任意方向上的导数, 称为 方向导数. 方向导数是矢量.
空间中的任意方向, 是可以用各坐标轴对应的基向量, 通过线性组合表示的. 同理, 方向导数可由各个维度的偏导数组合而来.
梯度
梯度是矢量, 指向函数增长最快的方向. 其模表示斜率的大小.
深度学习中要求的是损失函数的最小值, 就是要沿着梯度的反方向迭代.
求导法则
-
函数的 加,减,积,商 求导
u , v u,v u,v 分别是两个可导函数.
( u ± v ) ′ = u ′ ± v ′ (upm v)'=u'pm v' (u±v)′=u′±v′
( u v ) ′ = u ′ v + v ′ u (uv)'=u'v+v'u (uv)′=u′v+v′u
( u v ) ′ = u ′ v − v ′ u v 2 ( frac u v)'=frac {u'v-v'u} {v^2} (vu)′=v2u′v−v′u -
反函数的导数
略 -
复合函数的导数
如果 u = φ ( x ) u=varphi (x) u=φ(x) 在点 x 0 x_0 x0 处可导, y = f ( u ) y=f (u) y=f(u) 在点 u 0 = φ ( x 0 ) u_0=varphi (x_0) u0=φ(x0) 处可导, 那么复合函数 y = f [ φ ( x ) ] y=f[varphi (x)] y=f[φ(x)] 在点 x 0 x_0 x0 处可导, 导数为:
d y d x = d y d u ⋅ d u d x frac{dy}{dx}=frac{dy}{du} cdot frac{du}{dx} dxdy=dudy⋅dxdu
复合函数的求导法则亦称为链式法则.
例题:
d [ ( 1 − 2 x ) 100 ] d x = d [ ( 1 − 2 x ) 100 ] d ( 1 − 2 x ) ⋅ d ( 1 − 2 x ) d x = − 200 ( 1 − 2 x ) 99 frac {d[(1-2x)^{100}] }{dx} =frac {d[(1-2x)^{100}] }{d(1-2x)} cdot frac {d(1-2x)}{dx} =-200(1-2x)^{99} dxd[(1−2x)100]=d(1−2x)d[(1−2x)100]⋅dxd(1−2x)=−200(1−2x)99
常用公式
(
x
a
)
′
=
a
x
a
−
1
(x^a)'=ax^{a-1}
(xa)′=axa−1
(
a
x
)
′
=
a
x
l
n
a
(a^x)'=a^xlna
(ax)′=axlna
(
sin
x
)
′
=
cos
x
(sin x)'=cos x
(sinx)′=cosx
二阶偏导
如果函数f连续,则二阶偏导数的求导顺序没有区别,即 ∂ ∂ x ( ∂ f ∂ y ) = ∂ ∂ y ( ∂ f ∂ x ) frac{partial}{partial x}(frac{partial f}{partial y})=frac{partial}{partial y}(frac{partial f}{partial x}) ∂x∂(∂y∂f)=∂y∂(∂x∂f)
- 梯度
∇ f ( x ) = ( ∂ f ( x ) ∂ x 1 , . . . , ∂ f ( x ) ∂ x n ) T nabla f( x)=(frac {partial f( x) }{partial x_1}, ... ,frac {partial f( x) }{partial x_n} )^T ∇f(x)=(∂x1∂f(x),...,∂xn∂f(x))T - 黑塞矩阵
黑塞矩阵为n阶方阵 ∇ 2 f ( x ) nabla^2 f(mathbf x) ∇2f(x),第ij元 [ ∇ 2 f ( x ) ] i j = ∂ 2 f ( x ) ∂ x i ∂ x j [nabla^2 f(mathbf x)]_{ij}=frac {partial^2 f( mathbf x) }{partial x_i partial x_j} [∇2f(x)]ij=∂xi∂xj∂2f(x), 展开后见下:
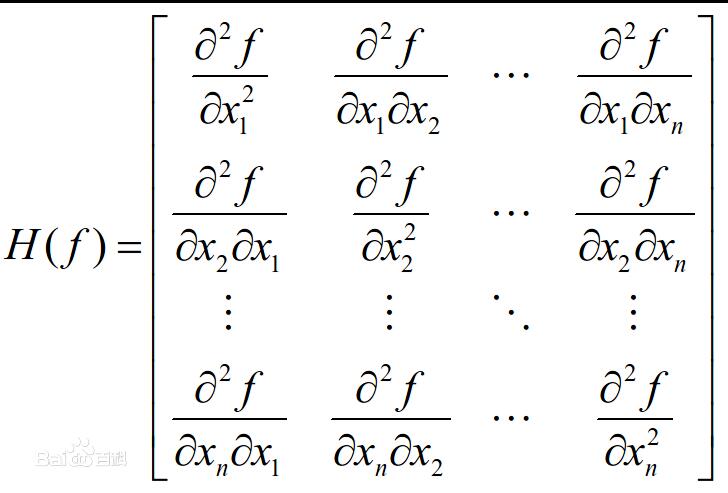
机器学习中的梯度计算
见参考[1].
参考
- 机器学中的梯度下降与最优化求解
最后
以上就是自由冷风最近收集整理的关于极限, 微分,导数与梯度极限 limitation导数 derivative求导法则常用公式二阶偏导机器学习中的梯度计算参考的全部内容,更多相关极限,内容请搜索靠谱客的其他文章。








发表评论 取消回复