CycleMLP由香港大学、商汤科技研究院和上海人工智能实验室共同开发,在2022年ICLR上发布。
MLP-Mixer, ResMLP和gMLP,其架构与图像大小相关,因此在目标检测和分割中是无法使用的。而CycleMLP有两个优点。(1)可以处理各种大小的图像。(2)利用局部窗口实现了计算复杂度与图像大小的线性关系。
Cycle FC
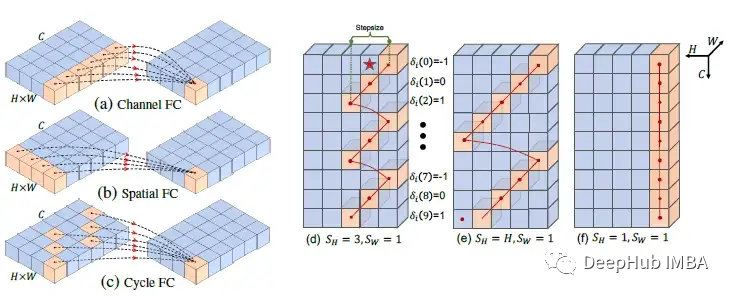
Cycle Fully-Connected Layer (Cycle FC) 和 Channel FC 、Spatial FC比较
- Channel FC:在空间大小为“1”的通道维度上聚合特征。它可以处理各种输入尺度,但不能学习空间上下文。
- Spatial FC (MLP-Mixer, ResMLP, & gMLP):在空间维度上有一个全局感受野。但是它的参数大小是固定的,并且对图像尺度具有二次计算复杂度。
- 论文的Cycle FC:具有与通道FC相同的线性复杂度和比通道FC更大的感受野。
- (d)-(f)为三个不同步长示例:橙色块表示采样位置。F表示输出位置。为了简单起见省略了批处理尺寸,并将特征的宽度设置为1。
在保持计算效率的同时,扩大mlp类模型的接受域,以应对下游密集的预测任务。
Cycle FC引入(SH, SW)的感受野,其中SH和SW分别为步长,随高度和宽度维数变化。基本的Cycle FC算子可以表述为:
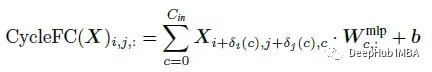
大小为 Cin×Cout 的 Wmlp 和大小为 Cout 的 b 是Cycle FC的参数。δi©和δj©为第c通道上两轴的空间偏移量,定义如下:
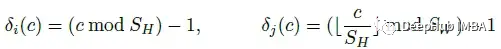
上图中(d)表示SH=3时沿两轴的偏移量,即δj©=0, δi©={- 1,0,1, - 1,0,1,…},当c= 0,1,2,…,8时。(e)表示当SH=H时,周期FC具有全局感受野。(f)表示当SH=1时,沿任何轴都没有偏移,因此Cycle FC退化为Channel FC。
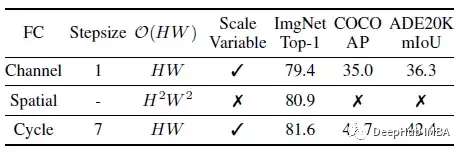
上表所示,更大的感受野带来了对语义分割和对象检测等密集预测任务的改进。同时,Cycle FC在输入分辨率上仍然保持了计算效率和灵活性,flop和参数数均与空间尺度呈线性关系。
与Transformer中的MHSA比较
受 Cordonnier ICLR’20 的启发,具有 Nh 个头的多头自注意力 (MHSA) 层可以表示如下,类似于具有以下内核大小的卷积:
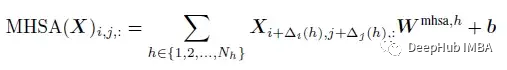
Wmlp与Wmhsa的关系可以表述为:
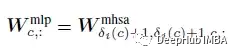
Cycle FC中的参数size为Cin×Cout, Wmhsa为K×K×Cin×Cout。Cycle FC还引入了一个归纳偏差,即MHSA中的权重矩阵应该是稀疏的。
CycleMLP
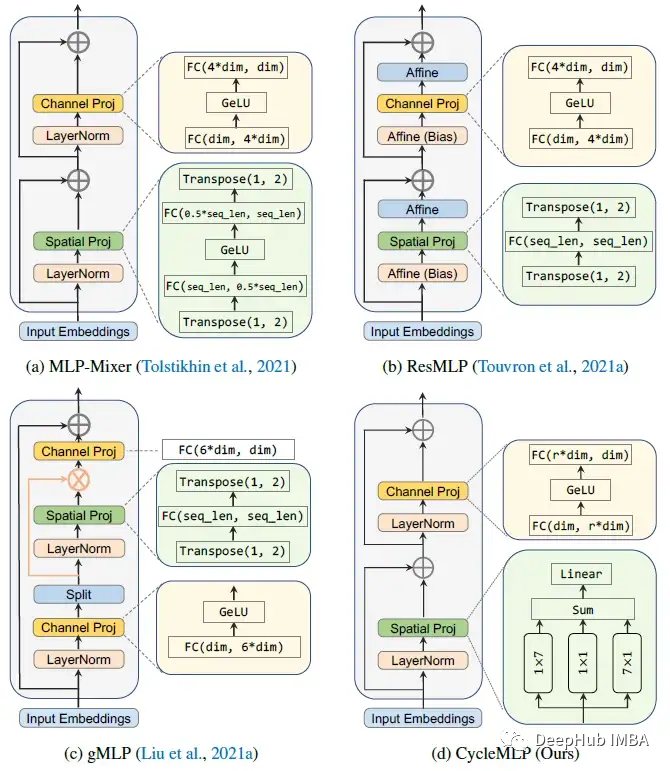
CycleMLP在MViT和PVTv2的基础上,采用了窗口大小为7,步幅为4的重叠补丁嵌入模块。这些原始补丁通过线性嵌入层依次应用几个Cycle FC 块进一步投影到更高维度(表示为 C)。。
Cycle FC块由三个并行的Cycle FC组成,它们的步长为1×7、7×1和1×1的SH×SW。该设计的灵感来自卷积的分解(Inception-v3)和交叉注意(CCNet)。
然后是一个通道 MLP,它有两个线性层,中间使用GELU激活。在并行Cycle FC 层和通道 MLP 模块之前应用 Layer Norm (LN) 层。在每个模块之后应用残差连接 (ResNet)。
在每个阶段转换中,所处理的令牌的通道容量被扩展,而令牌的数量被减少。总共有4个阶段。
模型参数如下
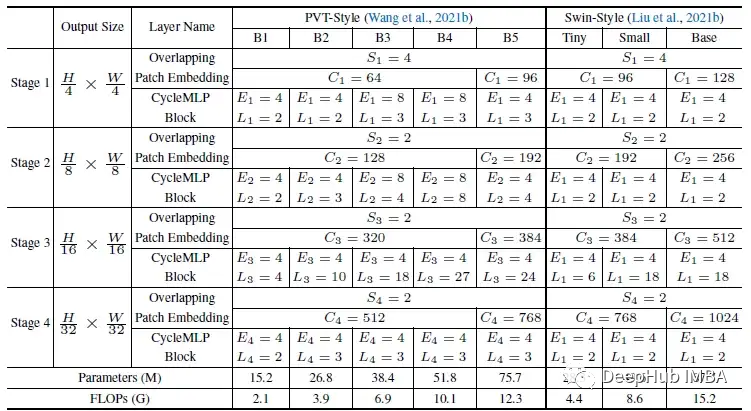
两个模型遵循两种广泛使用的Transformer架构PVT和Swin构建,如上图,其中Si、Ci、Ei、Li分别代表transition的步长、token通道维度、block数量、 第I阶段的膨胀率。
PVT-style 中的模型命名为 CycleMLP-B1 至 CycleMLP-B5,Swin-Style 中的模型命名为 CycleMLP-T、-S 和 -B,分别代表 tiny、small 和 base 尺寸的模型。
结果
ImageNet
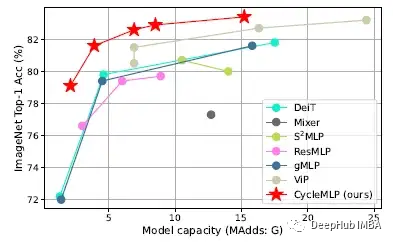
下图是mlp类模型的ImageNet-1K分类(左)。与没有额外数据的ImageNet-1K上的SOTA模型的比较(右)。
CycleMLP的精度- flop权衡始终优于现有的类似mlp的模型。并且实现了与Swin Transformer相当的性能。
在ImageNet-1K分类中,GFNet具有与CycleMLP相似的性能。打不世故GFNet与输入分辨率相关,这可能会影响密集预测的性能。
消融实验
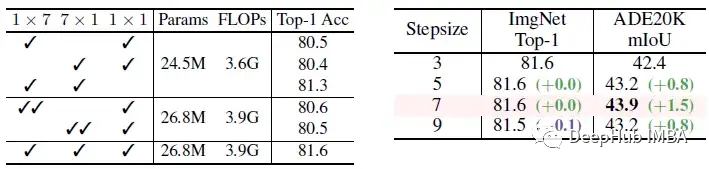
左:移除三个平行分支中的一个后,top-1的精度显著下降,特别是在丢弃1×7或7×1分支时。
右:当步长为7时,CycleMLP在ADE20K上的mIoU最高。
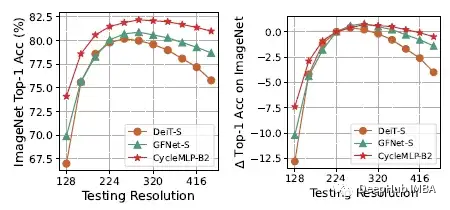
分辨率的适应性。左:绝对top-1精度;右:相对于224测试的精度差异。与DeiT和GFNet相比,CycleMLP在分辨率变化时具有更强的鲁棒性。在较高的分辨率下,CycleMLP的性能下降比GFNet小。
目标检测与实例分割
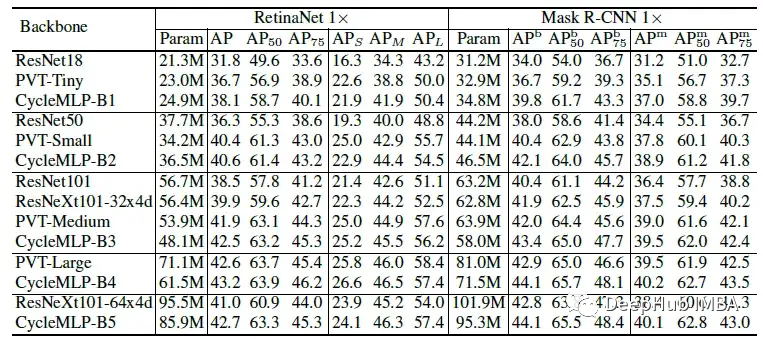
在相似的参数约束下,基于cyclemlp的RetinaNet一直优于基于cnn的ResNet、ResNeXt和基于transformer的PVT。使用Mask R-CNN进行实例分割也得到了相似的比较结果。

CycleMLP还实现了比Swin Transformer稍好的性能。
语义分割
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-anpQFlPn-1674010595616)(http://images.overfit.cn/upload/20230118/332286c358cd4b439852122cbc6bb1fe.png)]
左:ADE20K验证集上使用FPN的语义分割。右:有效感受野(ERF)
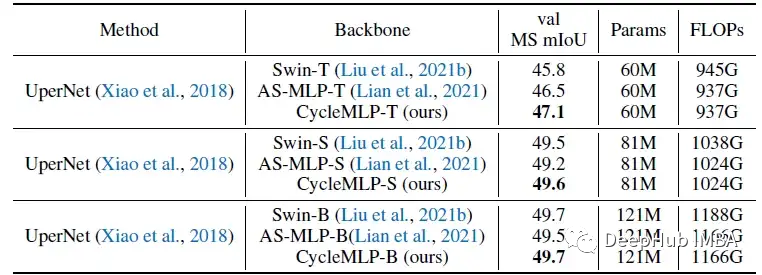
在ADE20K验证集上使用UPerNet对不同主干进行语义分割的结果
在相似参数下,CycleMLP的性能明显优于ResNet和PVT。与Swin Transformer相比,CycleMLP可以获得与Swin Transformer相当甚至更好的性能。虽然GFNet在ImageNet分类上的性能与CycleMLP相似,但在ADE20K上,CycleMLP的性能明显优于GFNet。
鲁棒性
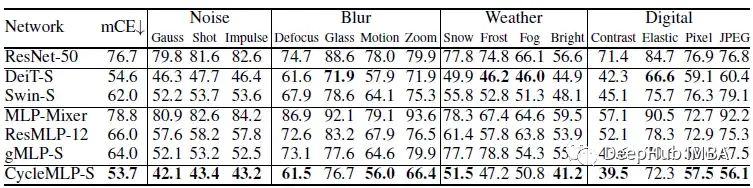
与transformer(如DeiT、Swin)和现有MLP模型(如MLP- mixer、ResMLP、gMLP)相比,CycleMLP具有更强的鲁棒性。
https://avoid.overfit.cn/post/9386a243a3714965ac0f40e8362a7f4d
作者:Sik-Ho Tsang
最后
以上就是生动皮卡丘最近收集整理的关于CycleMLP:一种用于密集预测的mlp架构的全部内容,更多相关CycleMLP:一种用于密集预测内容请搜索靠谱客的其他文章。








发表评论 取消回复