关注并星标
从此不迷路
计算机视觉研究院

公众号ID|ComputerVisionGzq
学习群|扫码在主页获取加入方式
链接: https://pan.baidu.com/s/1C_9AS3czjhpx_hffNAPRgg 密码: oow3
计算机视觉研究院专栏
作者:Edison_G
不同特征尺度的不一致是基于特征金字塔的single-shot检测器的主要限制。
01

前言

金字塔特征表示是解决目标检测中尺度变化挑战的常见做法。然而,不同特征尺度的不一致是基于特征金字塔的single-shot检测器的主要限制。在这项工作中,研究者提出了一种新颖的数据驱动的金字塔特征融合策略,称为自适应空间特征融合 (ASFF)。它学习了空间过滤冲突信息以抑制不一致性的方法,从而提高了特征的尺度不变性,并引入了free inference overhead。
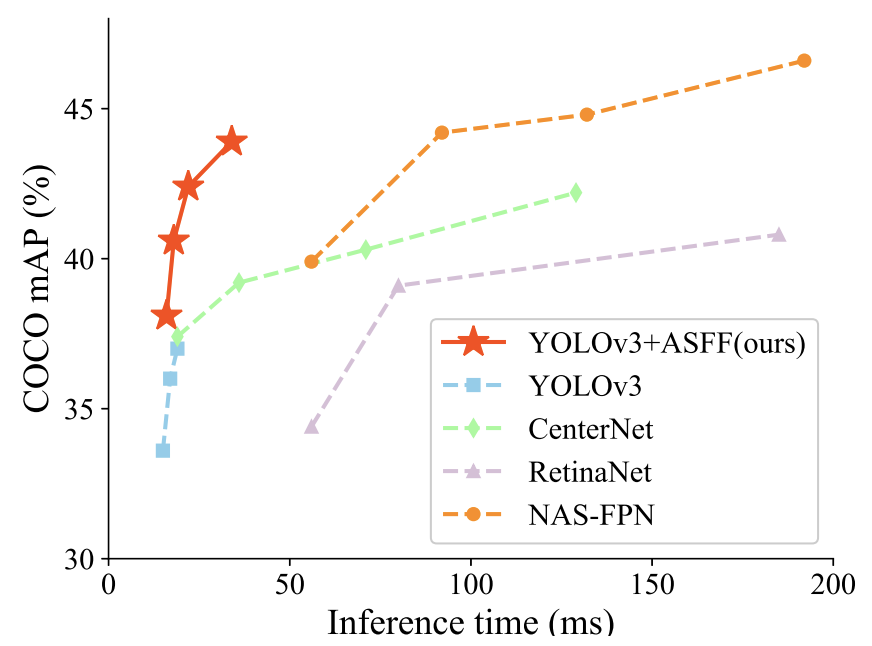
借助ASFF策略和YOLOv3的可靠基线,在MS COCO数据集上实现了最佳速度-准确度权衡,60FPS时AP为38.1%,45FPS时AP为42.4%,29FPS时AP为 43.9%。
02

背景

目标检测是各种下游视觉任务中最基本的组成部分之一。近年来,由于深度卷积神经网络(CNN)和注释良好的数据集的快速发展,目标检测器的性能得到了显着提高。然而,在大范围内处理多个对象仍然是一个具有挑战性的问题。为了实现尺度不变性,最近最先进的检测器构建了特征金字塔或多级特征塔。
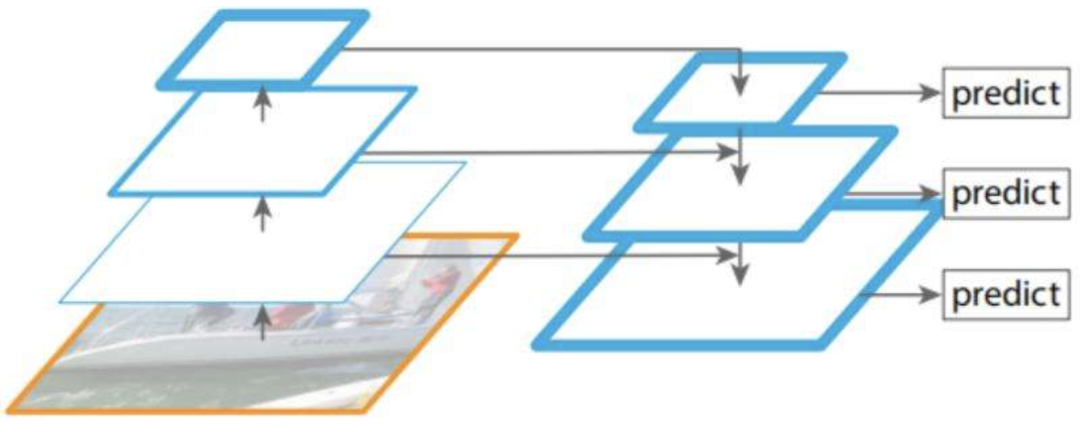
尽管这些高级研究提供了更强大的特征金字塔,但它们仍然为尺度不变预测留下了空间。SNIP给出了一些证据,它采用尺度归一化方法,在多尺度图像金字塔的每个图像尺度上选择性地训练和推断适当大小的目标,具有多尺度测试的探测器,实现了基于金字塔特征的结果的进一步改进。然而,图像金字塔解决方案急剧增加了推理时间,这使得它们不适用于实际应用。
同时,与图像金字塔相比,特征金字塔的一个主要缺点是在不同尺度上的不一致,特别是对于single-shot检测器。具体来说,当检测具有特征金字塔的目标时,采用启发式引导特征选择:大实例通常与上层特征图相关联,小实例与下层特征图相关联。当一个对象在某一层的特征图中被分配并被视为正样本时,其他层的特征图中的相应区域被视为背景。因此,如果图像中同时包含小物体和大物体,则不同层次的特征之间的冲突往往会占据特征金字塔的主要部分。这种不一致会在训练期间干扰梯度计算,并降低特征金字塔的有效性。一些模型采用了几种尝试性的策略来处理这个问题。比如将相邻级别的特征图的相应区域设置为忽略区域(即零梯度),但这种缓解可能会增加相邻级别特征的较差预测。TridentNet创建了多个具有不同感受野的特定尺度分支,用于尺度感知训练和推理。它脱离了特征金字塔以避免不一致,但也错过了重用其更高分辨率的地图,从而限制了小实例的准确性。
03

新框架分析

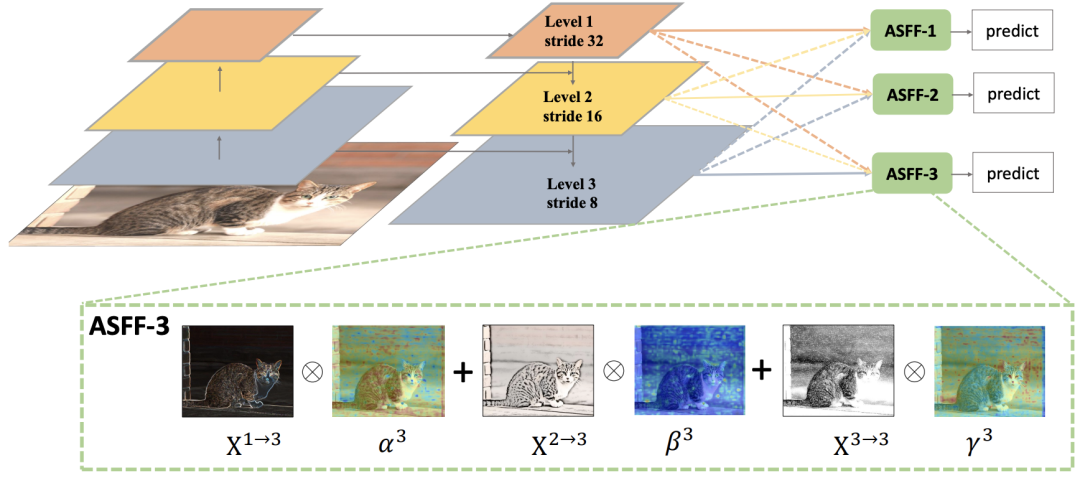
新框架采用YOLOv3框架,因为它简单高效。在YOLOv3中,有两个主要组件:一个高效的骨干网(DarkNet-53)和一个三层的特征金字塔网络。
此外,许多研究表明,anchor-free pipeline通过更简单的设计有助于显着提高性能。为了更好地证明提出的ASFF方法的有效性,基于这些先进技术构建了一个比原点强得多的基线。
Adaptively Spatial Feature Fusion
与以前使用元素总和或连接来集成多级特征的方法不同,关键思想是自适应地学习每个尺度的特征图融合的空间权重。该pipeline如上图所示,它由两个步骤组成:identically rescaling和adaptively fusing。
Feature Resizing
由于YOLOv3中三个层次的特征具有不同的分辨率和不同的通道数,我们相应地修改了每个尺度的上采样和下采样策略。对于上采样,首先应用一个1×1的卷积层将特征的通道数压缩到第l级,然后分别通过插值来提升分辨率。对于1/2比率的下采样,我们只需使用步长为2的3×3卷积层来同时修改通道数和分辨率。对于1/4的比例,我们在2-stride卷积之前添加了一个2-stride最大池化层。
Adaptive Fusion
令x表示从第n级调整到第l级的特征图上位置(i, j)处的特征向量。建议将相应级别l的特征融合如下:
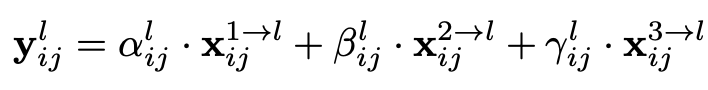
04

实验对比及可视化

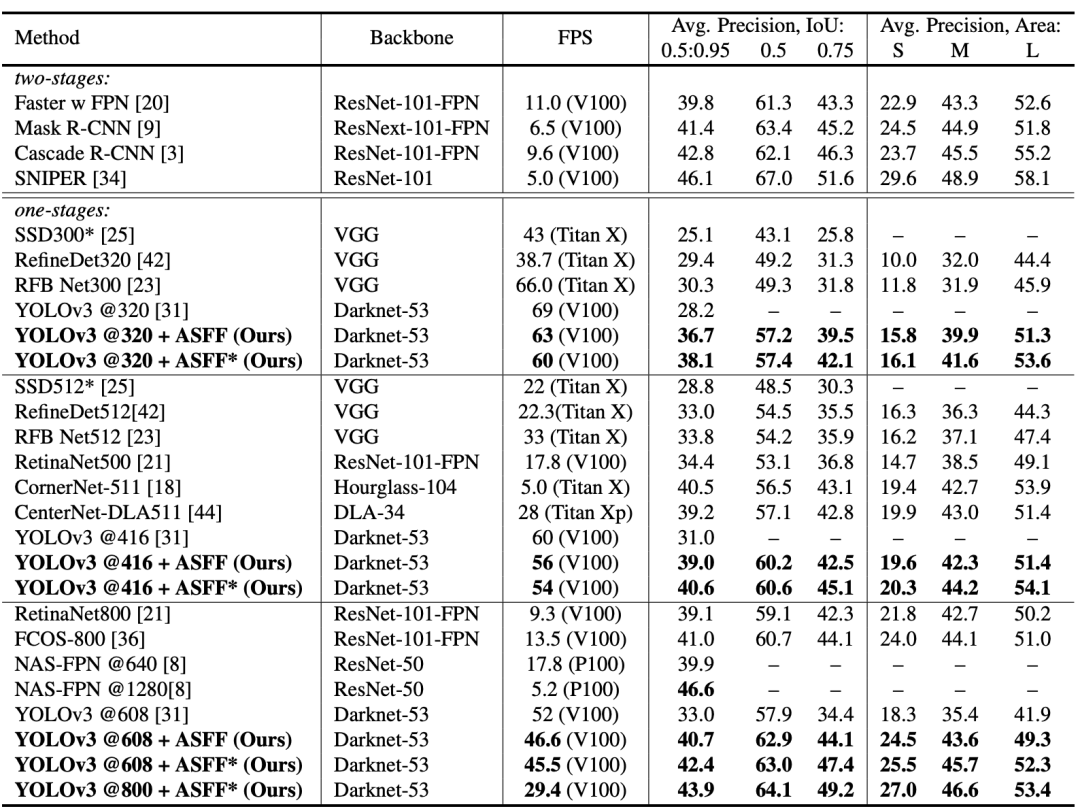
在COCO val-2017数据集上的比较

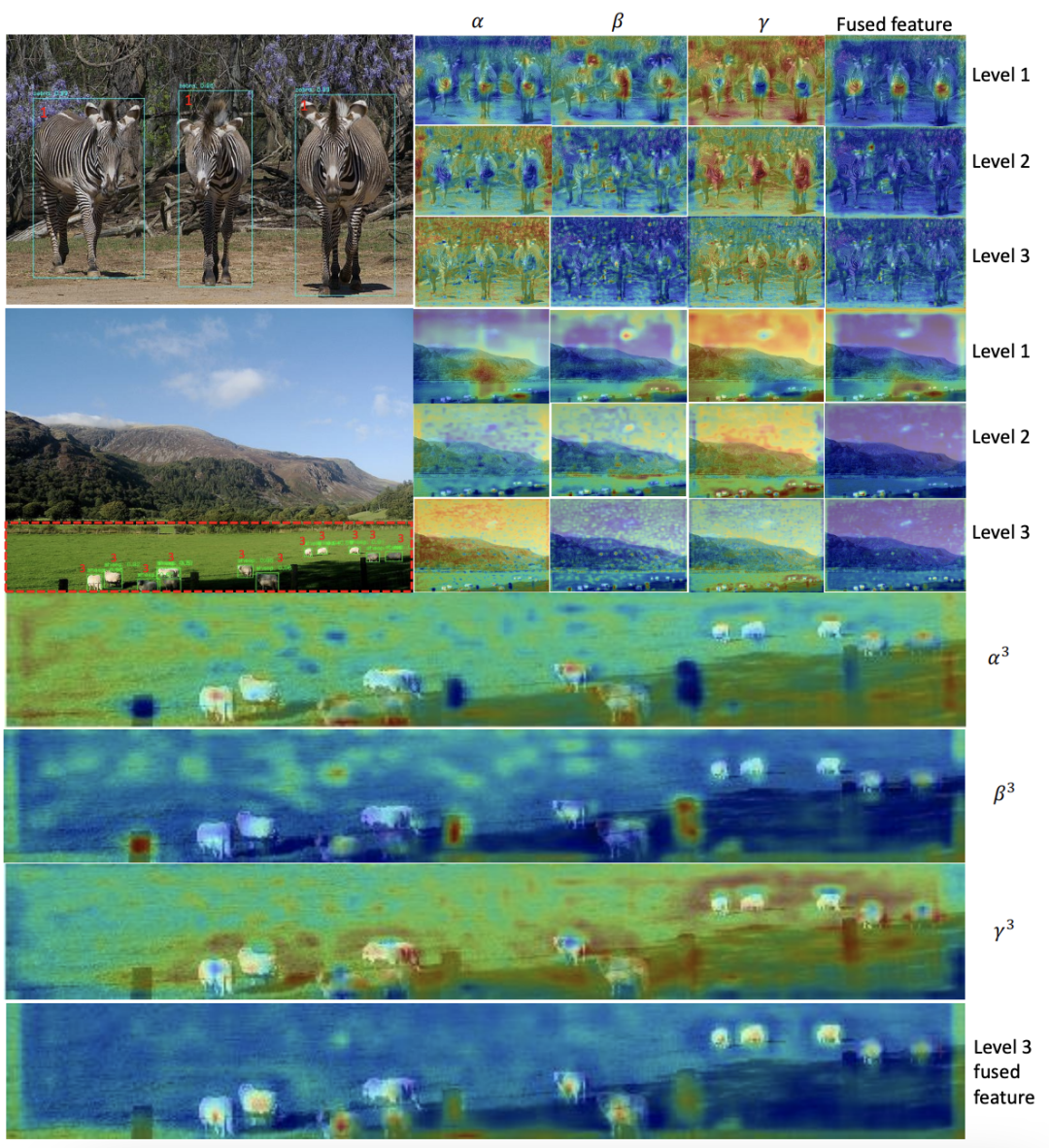
COCO val-2017上检测结果的可视化以及每个级别的学习权重标量图。在红色框中放大了第3级的热图,以便更好地可视化。
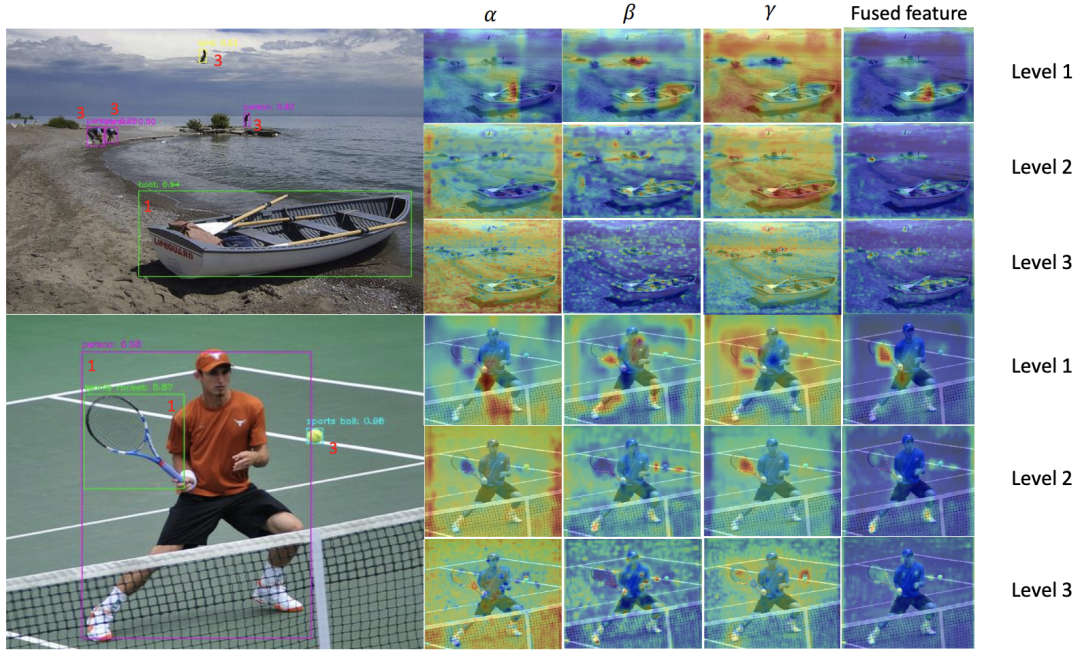
当一张图像具有多个不同大小的对象时,更多的定性示例。
© The Ending
转载请联系本公众号获得授权

计算机视觉研究院学习群等你加入!
计算机视觉研究院主要涉及深度学习领域,主要致力于人脸检测、人脸识别,多目标检测、目标跟踪、图像分割等研究方向。研究院接下来会不断分享最新的论文算法新框架,我们这次改革不同点就是,我们要着重”研究“。之后我们会针对相应领域分享实践过程,让大家真正体会摆脱理论的真实场景,培养爱动手编程爱动脑思考的习惯!

扫码关注
计算机视觉研究院
公众号ID|ComputerVisionGzq
学习群|扫码在主页获取加入方式
往期推荐
????
目标检测:SmartDet、Miti-DETR和Few-Shot Object Detection
RestoreDet:低分辨率图像中目标检测
Yolo-Z:改进的YOLOv5用于小目标检测(附原论文下载)
零样本目标检测:鲁棒的区域特征合成器用于目标检测(附论文下载)
目标检测创新:一种基于区域的半监督方法,部分标签即可(附原论文下载)
利用先进技术保家卫国:深度学习进行小目标检测(适合初学者入门)
用于精确目标检测的多网格冗余边界框标注
华为诺亚方舟实验室品:加法神经网络在目标检测中的实验研究
多尺度特征融合:为检测学习更好的语义信息(附论文下载)
利用TRansformer进行端到端的目标检测及跟踪(附源代码)
目标检测:用图特征金字塔提升精度(附论文下载)
最后
以上就是俊秀仙人掌最近收集整理的关于自适应特征融合用于Single-Shot目标检测(附源代码下载)的全部内容,更多相关自适应特征融合用于Single-Shot目标检测(附源代码下载)内容请搜索靠谱客的其他文章。








发表评论 取消回复