Strong-Weak Distribution Alignment for Adaptive Object Detection
Code: https://github.com/VisionLearningGroup/DA_Detection
Introduction
对于目标检测任务而言,简单地对源域和目标域之间整张图的分布进行对齐往往并不是很有效,因为不同地图像包含有多种目标。然而对局部特征如纹理、颜色等进行对齐,这样不会改变类别层次的语义,往往很有效。
传统的方法是对利用对抗的方法来利用两个域之间的距离限制泛化误差,但是这种strong对齐的方式比较适合一些closed problem。例如分类问题。对于open-set分类以及partial domain adaption就不太可行了。
对于目标检测任务来说,对齐全局的特征意味着不仅要对齐目标,同时要对齐背景和场景层面。
Our key contribution is the weak global alignment model, which focuses the adversarial alignment loss toward images that are globally similar, and away from images that are globally dissimilar.
Additionally, we achieve strong local alignment by constructing a domain classifier designed to look only at local features and to strictly align them with the other domain.
Method
Weak Global Feature Alignment
对于全局特征利用weakly对齐的方式进行对齐,只关注源域和目标域中hard-clasify的样本,为了域判别器能够更好地关注hard-clasify的样本,作者对于分类损失采用了focal-loss,使得在训练过程中中能够更加关注hard-clasify的样本,从而实现对局部特征的weakly align。
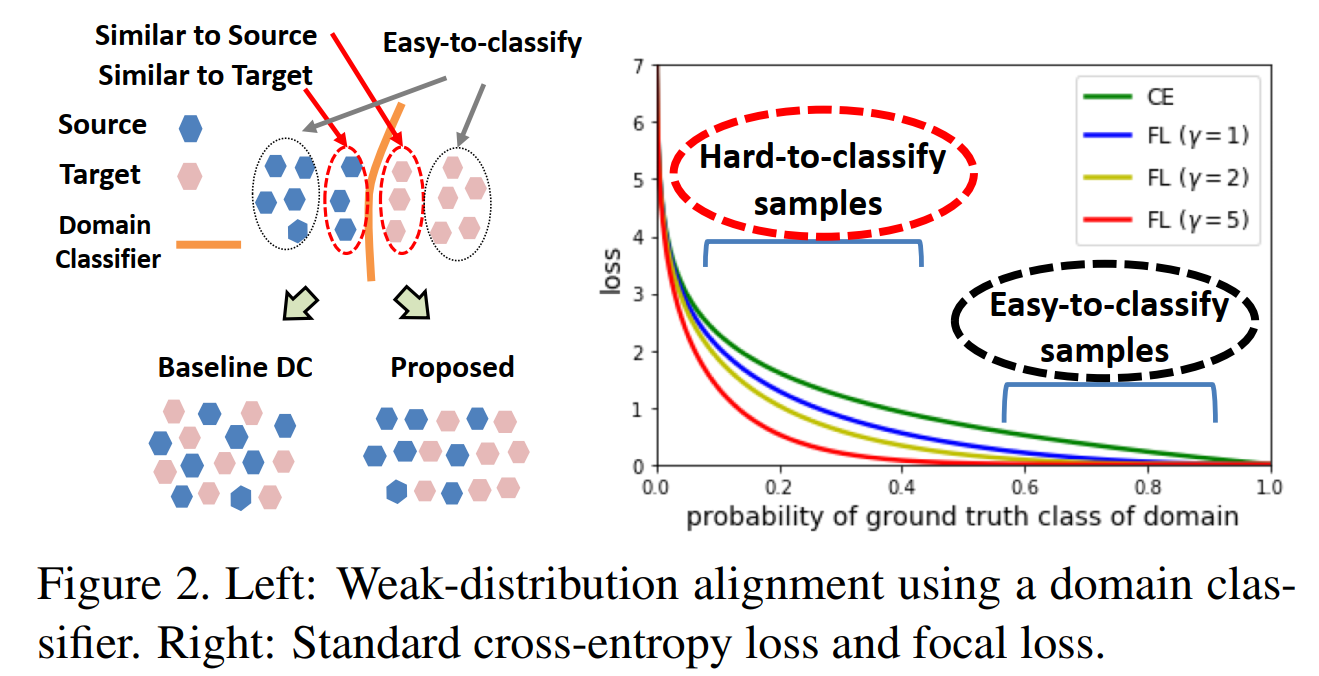
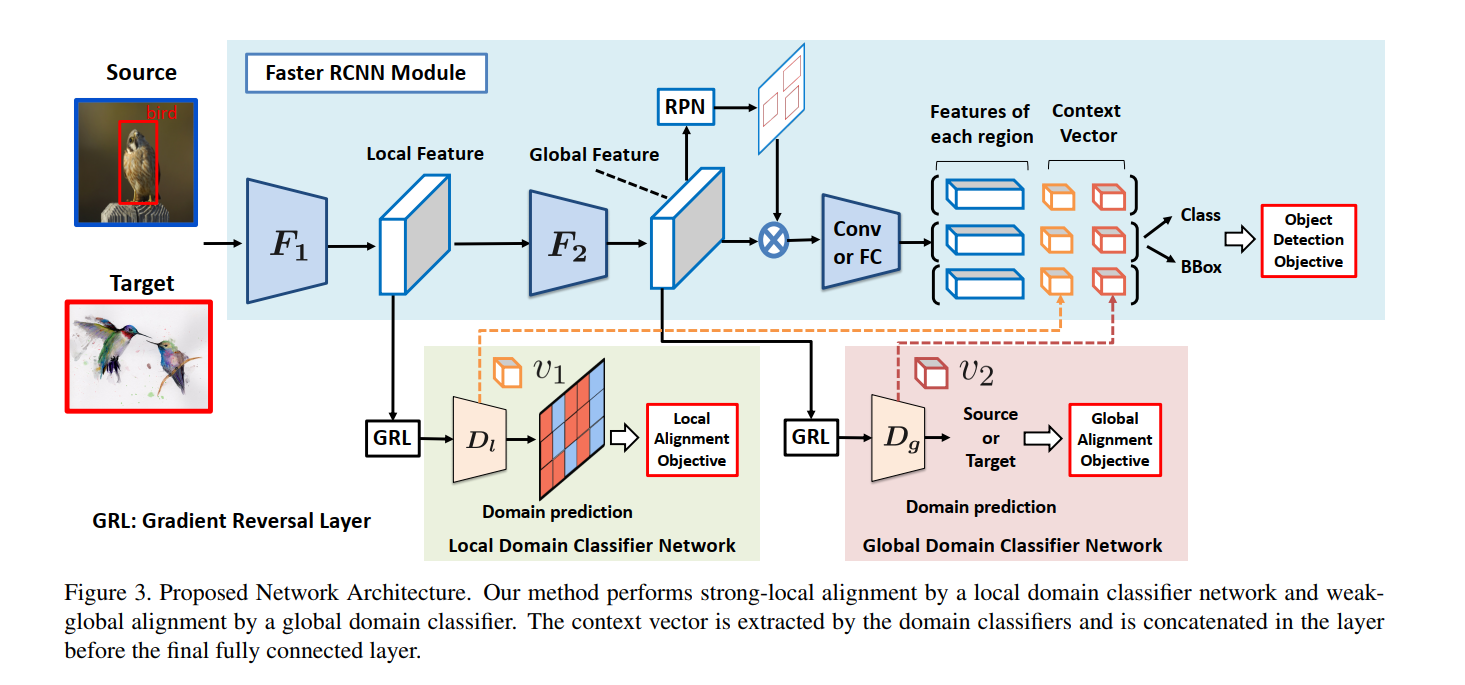
Strong Local Feature Alignment
在深度网络后添加一个判别器,用于局部特征的对齐,损失函数采用最小均方损失。
L
l
o
c
s
=
1
n
s
H
W
∑
i
=
1
n
s
∑
w
=
1
W
∑
h
=
1
H
D
l
(
F
1
(
x
i
s
)
)
w
h
2
(
8
)
L_{loc_{s}}= frac{1}{n_{s}HW} sum_{i=1}^{n_{s}} sum_{w=1}^{W} sum_{h=1}^{H} D_{l}left(F_{1}left({x_{i}}^{s}right)right)_{wh}^{2} qquad(8)
Llocs=nsHW1i=1∑nsw=1∑Wh=1∑HDl(F1(xis))wh2(8)
L l o c t = 1 n t H W ∑ i = 1 n t ∑ w = 1 W ∑ h = 1 H ( 1 − D l ( F 1 ( x i t ) ) w h ) 2 ( 9 ) L_{loc_{t}}= frac{1}{n_{t}HW} sum_{i=1}^{n_{t}} sum_{w=1}^{W} sum_{h=1}^{H} left(1-D_{l}left(F_{1}left({x_{i}}^{t}right)right)_{wh}right)^{2} qquad(9) Lloct=ntHW1i=1∑ntw=1∑Wh=1∑H(1−Dl(F1(xit))wh)2(9)
L l o c ( F , D l ) = 1 2 ( L l o c s + L l o c t ) ( 10 ) L_{loc}left(F,D_{l}right)= frac{1}{2} left(L_{loc_{s}}+L_{loc_{t}}right) qquad(10) Lloc(F,Dl)=21(Llocs+Lloct)(10)
Context Vector based Regularization
正则化方法用于提升模型的表现,对于源域的图像抽取两个域分类器的输出向量v1、v2,并将其concatenate到每个region对应的特征后 ,相当于添加了一个上下文信息。
Overall Objective
L a d v ( F , D ) = L l o c ( F 1 , D l ) + L g l o b a l ( F , D g ) ( 11 ) L_{adv}left(F,Dright)= L_{loc}left(F_{1},D_{l}right)+ L_{global}left(F,D_{g}right) qquad(11) Ladv(F,D)=Lloc(F1,Dl)+Lglobal(F,Dg)(11)
Combined with the loss of detection on source examples, the overall objective is
max
D
min
F
,
R
L
c
l
s
(
F
,
R
)
−
λ
L
a
d
v
(
F
,
D
)
(
12
)
maxlimits_{D}minlimits_{F,R} L_{cls}left(F,Rright)- lambda L_{adv}left(F,Dright) qquad(12)
DmaxF,RminLcls(F,R)−λLadv(F,D)(12)
Result
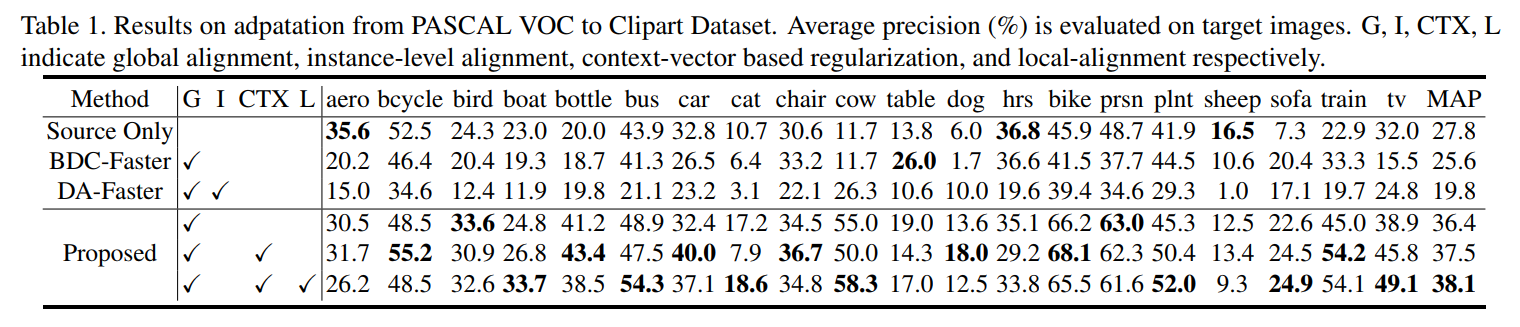
对比得到文章所提出的方法能够很好地实现从PASCAL VOC to Clipart Dataset上的自适应
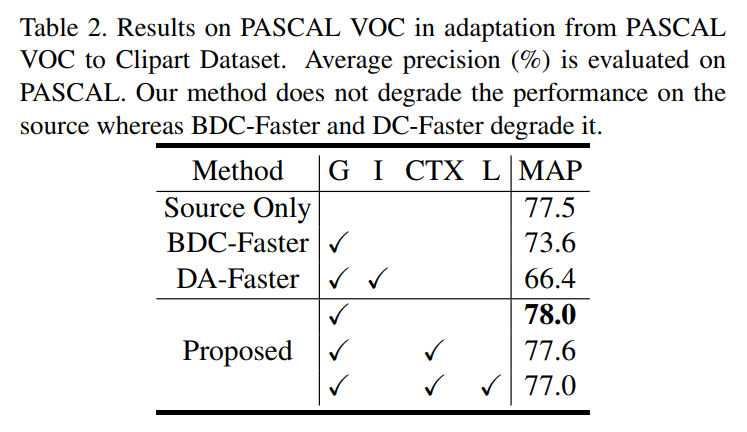
结果显示在PASCAL VOC to Clipart Dataset上的域自适应训练后,文章所提出的网络对比仅在源域上训练上的结果,其效果并未下降,即未降低在源域上的检测能力。
最后
以上就是怕黑手套最近收集整理的关于CVPR2019 Strong-Weak Distribution Alignment for Adaptive Object DetectionStrong-Weak Distribution Alignment for Adaptive Object Detection的全部内容,更多相关CVPR2019内容请搜索靠谱客的其他文章。








发表评论 取消回复