目标检测创新:一种基于区域的半监督方法,部分标签即可 ,研究表明,当训练数据缺少注释(即注释稀疏的数据)时,目标检测器的性能会显着下降。
论文地址:https://arxiv.org/pdf/2201.04620v1.pdf
研究表明,当训练数据缺少注释(即注释稀疏的数据)时,目标检测器的性能会显着下降。现在的方法侧重于以伪标签的形式或通过在训练期间重新加权未标记框的梯度来解决缺失真实标注的问题。
在这项工作中,研究者重新审视了稀疏注释目标检测的公式。研究者观察到稀疏注释的目标检测可以被认为是区域级别的半监督目标检测问题。基于这一见解,研究者们提出了一种基于区域的半监督算法,该算法可以自动识别包含未标记前景对象的区域。然后,提出的算法以不同方式处理标记和未标记的前景区域,这是半监督方法中的常见做法。为了评估所提出方法的有效性,对PASCAL-VOC和COCO数据集上稀疏注释方法常用的五个分割进行了详尽的实验,并实现了最先进的性能。除此之外,还表明新提出的方法在标准半监督设置上实现了竞争性能,证明了新方法的强度和广泛适用性。
传统的目标检测方法假设训练数据集被详尽地标记。这种检测器的性能对标记数据的质量很敏感。用于训练目标检测器的数据中的噪声可能是由于噪声类标签或不正确/丢失的边界框而产生的。在这项工作中,研究者处理了缺少类标签和边界框注释的更难的问题,即稀疏注释的存在。稀疏注释目标检测(SAOD)是在训练数据中存在缺失注释的情况下提高目标检测鲁棒性的问题。这个问题在当前至关重要,因为获取众多数据集可能既昂贵又费力。另一种方法是使用计算机辅助协议来收集注释。然而,这些方法受到嘈杂/缺失标签的影响。因此,必须调整当前的目标检测器来解决稀疏注释的问题。

问题的症结在于训练期间分配标签的方式。稀疏注释减少了真正的正样本并将假负样本引入训练,从而降低了网络性能。虽然这过于简单化了,但它可以更好地了解正在处理的问题。研究者建立在一个简单的观察之上,即SAOD是区域级别的半监督目标检测(SSOD)。然而,未标记的数据,在我们的例子中是包含前景对象的区域,是先验未知的,必须被识别。因此,SSOD方法不能直接应用于SAOD,因为当前的方法假设一个已知的未标记集以及一个详尽标记的训练集。同样,最近提出的SAOD方法在训练期间丢弃所有没有单个注释的图像,并且不能像SSOD方法那样真正利用未标记数据的力量。分别在上图的第1行和第2行中说明了SSOD和SAOD。
假设稀疏注释的目标检测方法应该是一个很好的半监督学习器,因为SSOD中的未标记图像可以被视为SAOD的缺失注释。我们在上图的第3行展示了这个公式。
所提出的方法如下图所示,由一个标准的骨干网络组成,该网络从图像的原始视图和增强视图中提取特征。
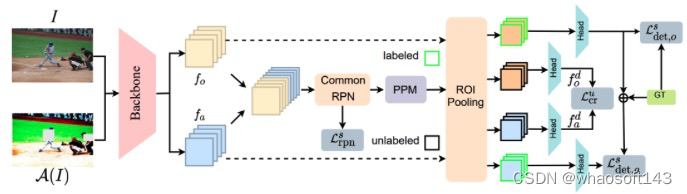 一个通用的RPN将骨干网络提取的特征连接起来,生成一组通用的候选区域。候选区域b可以属于三个组之一,即:
一个通用的RPN将骨干网络提取的特征连接起来,生成一组通用的候选区域。候选区域b可以属于三个组之一,即:
-
标记区域b∈ Bl
-
未标记区域b∈Bul
-
背景区域b∈ Bbg
对于给定的一组真实标注,可以自动识别第一组,即标记区域。然后问题就变成了从背景区域中识别和分离第二组,即未标记区域。给定所有候选区域,pseudo-positive mining(PPM)步骤识别未标记区域并将它们与背景区域分离。受半监督方法的启发,标记和未标记区域分别受到监督和非监督损失的监督。我们在下面详细描述每个阶段。 whaosoft aiot http://143ai.com
Feature Extraction
给定图像I,计算表示为A(I)的I的增强版本。在这项工作中,我们使用随机对比度、亮度、饱和度、光照和边界框以级联方式擦除以生成A(I)。 一个检测器骨干网络用于分别从I和A(I)中提取两个特征fo和fa。
Common RPN (C-RPN)
传统的两阶段目标检测器使用区域提议网络(RPN)来生成感兴趣区域(ROI)。fo和fa这两个特征使用RPN生成两组不同的ROI。对两组ROI进行操作增加了识别标记区域、未标记区域和背景区域的难度,同时增加了处理时间。此外,对于关联,必须执行匹配算法,如基于IoU)分数的Kuhn-Munkres算法,以获得输入图像的一组通用标记、未标记和背景框。由于不完美的匹配,此过程可能会很嘈杂。为了避免这种情况,提出了一种连接fo和fa以获得ROI的C-RPN。
![]()
Pseudo Positive Mining
给定来自C-RPN的ROI,下一步是从标记区域和背景区域中识别未标记区域。基于我们的观察,即使在使用稀疏注释进行训练时,RPN也可以可靠地区分前景和背景区域,我们广泛依赖RPN的分数来识别未标记区域。
首先,根据可用的Ground Truth,所有分配为正的ROI都从C-RPN的输出中删除。接下来,所有具有大于阈值(本工作中为0.5和IoU小于阈值(本工作中为0.2)且具有任何GT的ROI都被视为未标记区域。剩余的ROI分配给负样本。我们稍后会证明这个简单的步骤可以提高RPN的召回率。请注意,由于阈值不同,一些未标记的区域可能会被错误地分配给负样本。这些地区将在后续阶段得到照顾。
Losses
在pseudo positive mining步骤之后,来自C-RPN的ROI被分为标记、未标记和背景区域。首先,ROI池化层从特征fo中提取标记区域和背景区域的区域特征,然后将其馈送到检测头。检测头预测每个区域的类别概率和边界框。稀疏GT用于监督这些预测,方法是将交叉熵损失应用于标记和背景区域的分类,以及平滑L1用于标记区域的边界框回归:
![]()
最后,对未标记区域执行与类别无关的NMS,以删除导致Nu唯一区域的重复项。Nu未标记区域与fo和fa一起通过ROI池化层和检测头,分别获得fdo和fda。应用了如下所示的一致性正则化损失,它强制原始区域和增强区域的特征彼此一致。
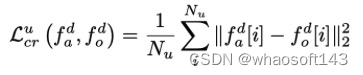
实验
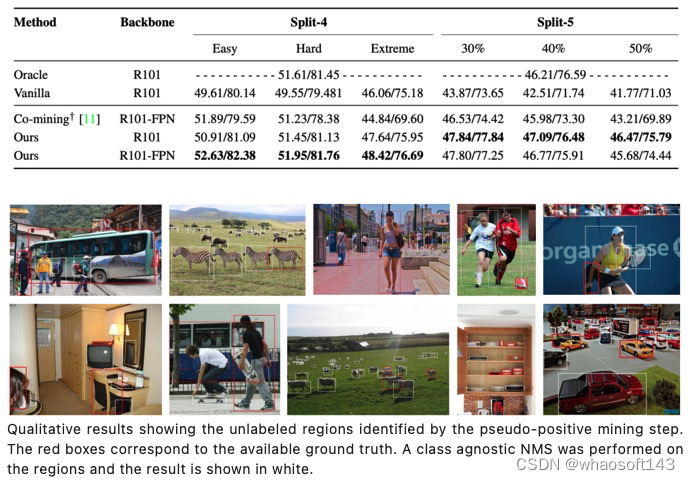
Sparsely annotated object detection在COCO的结果
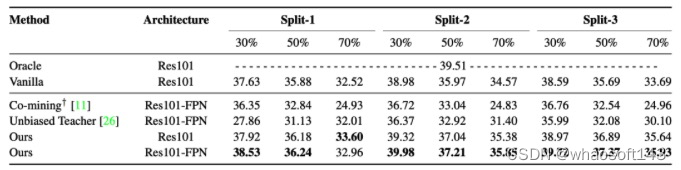 Sparsely annotated object detection在VOC结果
Sparsely annotated object detection在VOC结果
 将使用可用的GT(顶部)训练的“普通”模型的输出与使用新提出的方法训练的模型(底部)进行比较的定性结果。显示类别置信度分数大于0.9的预测。红色:人,青色:狗,紫色:马,黄色:时钟,绿色:停车标志,蓝色:停车计时器,紫色:长颈鹿,橙色:盆栽,黑色:冲浪板,深绿色:船。
将使用可用的GT(顶部)训练的“普通”模型的输出与使用新提出的方法训练的模型(底部)进行比较的定性结果。显示类别置信度分数大于0.9的预测。红色:人,青色:狗,紫色:马,黄色:时钟,绿色:停车标志,蓝色:停车计时器,紫色:长颈鹿,橙色:盆栽,黑色:冲浪板,深绿色:船。
最后
以上就是沉默烤鸡最近收集整理的关于SAOD~的全部内容,更多相关SAOD~内容请搜索靠谱客的其他文章。








发表评论 取消回复