用于流感知的实时对象检测
自动驾驶需要模型感知环境并在低延迟内(重新)采取行动以确保安全。虽然过去的工作忽略了处理后环境中不可避免的变化,但提出了流式感知将延迟和准确性联合评估为视频在线感知的单一指标。在本文中,我们没有像以前的工作那样在准确性和速度之间进行权衡,而是指出赋予实时模型预测未来的能力是解决这个问题的关键。我们为流式感知构建了一个简单有效的框架。它配备了一个新颖的双流感知模块 (DFP),其中包括动态和静态流,以捕捉移动趋势和流预测的基本检测功能。此外,我们引入了趋势感知损失 (TAL) 与趋势因子相结合,为具有不同移动速度的对象生成自适应权重。我们的简单方法在 Argoverse-HD 数据集上实现了具有竞争力的性能,与强基线相比,AP 提高了 4.9%,验证了其有效性。我们的代码将在 https://github.com/yancie-yjr/StreamYOLO 上提供。
1. Introduction
自动安全驾驶的一个关键因素是感知其环境并在低延迟内(重新)采取行动。 最近,一些实时检测器 [3, 13, 18, 31, 33, 41-43] 在低延迟限制下实现了竞争性能。 但它们仍在离线环境中进行探索 [26]。 在真实的在线视觉场景中,无论模型变得多快,一旦模型完成处理最新帧,周围环境就会发生变化。 如图 1(a) 所示,感知结果与变化状态之间的不一致可能会触发自动驾驶的不安全决策。 因此,对于在线感知,检测器被要求具有未来预测的能力。
为了解决这个问题,[26]首先提出了一种新的度量标准,称为流准确性,它将延迟和准确性集成到一个实时在线感知的度量中。它在每个时刻联合评估整个感知堆栈的输出,迫使感知预测模型完成处理的状态。有了这个指标,[26] 显示了几个强大的检测器 [6,21,28] 从离线设置到流感知的性能显着下降。此外,[26] 提出了一种名为 Streamer 的元检测器,它可以将任何检测器与决策理论调度、异步跟踪和未来预测相结合,以恢复大部分性能下降。在这项工作之后,自适应流媒体 [16] 采用了许多基于深度强化学习的近似执行来学习更好的在线权衡。这些工作的重点是为一些现有的检测器在速度和准确性之间寻找更好的权衡策略,而一种新颖的流感知模型设计还没有得到很好的研究。
上述工作忽略的另一件事是现有的实时对象检测器 [13, 18]。通过强大的数据增强和精致的架构设计,它们实现了具有竞争力的性能,并且可以运行速度超过 30 FPS。有了这些“足够快”的检测器,就没有空间在流感知上进行准确性和延迟权衡,因为检测器的当前帧结果总是与下一帧匹配和评估。这些实时检测器可以缩小流感知和离线设置之间的性能差距。事实上,Streaming Perception Challenge(CVPR 2021 上的自动驾驶研讨会)的第一名 [59] 和第二名 [20] 的解决方案均采用实时模型 YOLOX [13] 和 YOLOv5 [18] 作为其基础检测器。站在实时模型的肩膀上,我们发现现在的性能差距都来自当前处理帧和下一个匹配帧之间的固定不一致。因此流感知的关键解决方案是在当前状态下预测下一帧的结果
与[26]中采用的启发式方法(如卡尔曼滤波器[25])不同,在本文中,我们直接赋予实时检测器预测下一帧未来的能力。具体来说,我们构建了最后一帧、当前帧和下一帧的三元组进行训练,其中模型将最后一帧和当前帧作为输入,并学习预测下一帧的检测结果。我们提出了两个提高训练效率的关键设计:i)对于模型架构,我们进行双流感知(DFP)模块来融合来自最后一帧和当前帧的特征图。它由动态流和静态流组成。动态流关注对象的移动趋势进行预测,而静态流通过残差连接提供检测的基本信息和特征。 ii)对于训练策略,我们引入了趋势感知损失(TAL)来动态分配不同的权重来定位和预测每个对象,因为我们发现一帧内的对象可能具有不同的移动速度。
我们对 Argoverse HD [5,26] 数据集进行了综合实验,显示了流感知任务的显着改进。 总之,这项工作的贡献有以下三方面:
• 借助实时检测器的强大性能,我们发现流感知的关键解决方案是预测下一帧的结果。 这个简化的任务很容易通过基于模型的算法进行结构化和学习。
• 我们构建了一个简单有效的流式检测器,可以学习预测下一帧。 我们提出了两个适应模块,即双流感知(DFP)和趋势感知损失(TAL),以感知移动趋势并预测未来。
• 我们在Argoverse HD [5, 26] 数据集上实现了具有竞争力的性能,没有花里胡哨。 与实时检测器的强基线相比,我们的方法将 mAP 提高了 +4.9%,并在驾驶车辆的不同移动速度下显示出鲁棒的预测。
2. Related Works
图像对象检测。 在深度学习时代,检测算法可以分为两阶段 [17, 27, 34, 44, 53, 60] 和一阶段 [14, 28, 31, 32, 35, 38, 39、41、51、61] 框架。 一些作品,例如 YOLO 系列 [3, 13, 18, 41-43],采用了一系列训练和加速技巧,以实现具有实时推理速度的强大性能。 我们的工作基于最近的实时检测器 YOLOX [13],它在实时检测器中实现了强大的性能
视频对象检测。 流式感知也与视频对象检测有关。 最近的一些方法 [1, 7, 11, 62] 采用注意力机制、光流和跟踪方法,旨在为复杂的视频变化聚合丰富的特征,例如运动模糊、遮挡和失焦。 但是,它们都专注于离线设置,而流式感知则考虑了在线处理延迟,需要预测未来的结果。
视频预测。 视频预测任务旨在预测未观察到的未来数据的结果。 当前任务包括未来的语义/实例分割。 对于语义分割,早期的工作 [2,37] 构建了从过去分割到未来分割的映射。 最近的工作 [9, 30, 46, 47] 通过采用可变形卷积、教师学生学习、基于流的预测、基于 LSTM 的方法等转换为预测中间分割特征。例如分割预测,一些方法预测 金字塔特征 [36] 或不同金字塔级别的特征联合 [23, 49]。 上述预测方法没有考虑处理延迟引起的预测失准和环境变化,给实际应用留下了差距。 在本文中,我们专注于更实际的流感知任务。
流式感知。 流式感知任务连贯地考虑延迟和准确性。 [26]首先提出考虑时延的sAP来评估准确性。 面对延迟,非实时检测器会丢失一些帧。 [26] 提出了一种元检测器,通过使用卡尔曼滤波器 [25]、决策理论调度和异步跟踪 [1] 来缓解这个问题。 [16] 列出了几个因素(例如,输入尺度、检测器的可切换性和场景聚合。)并设计了一个强化学习的代理来学习更好的组合以获得更好的权衡。 Fovea [50] 采用基于 KDE 的映射来提高离线性能的上限。 在这项工作中,我们不是寻找更好的权衡或增强基础检测器,而是将流感知简化为实时检测器“预测下一帧”的任务。
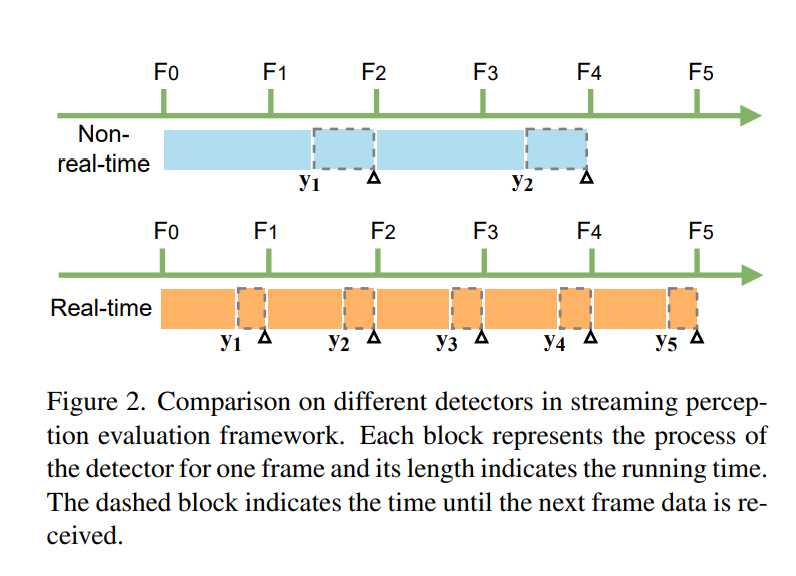
图 2. 流感知评估框架中不同检测器的比较。 每个块代表一帧检测器的过程,其长度表示运行时间。 虚线块表示直到接收到下一帧数据的时间。
3. Methods
3.1. Streaming Perception
流式感知将数据组织为一组传感器观察结果。 为了将模型处理延迟考虑在内,[26] 提出了一种名为流式 AP (sAP) 的新指标,以同时评估时间延迟和检测精度。 如图 2 所示,流式基准测试在连续的时间范围内评估检测结果。 在接收和处理图像帧后,SAP 模拟流之间的时间延迟,并根据实际世界状态的基本事实检查处理后的输出。
对于非实时检测器的示例,帧 F1 的输出 y1 与 F3 的 ground truth 进行匹配和评估,而 F2 的结果被遗漏。 因此对于流式感知的任务,非实时检测器可能会丢失许多图像帧并产生长时间偏移的结果,严重影响离线检测的性能
对于实时检测器(一帧图像的总处理时间小于图像流的时间间隔),流感知的任务变得简单明了。 正如我们在图 2 中看到的,实时检测器通过将下一帧与当前预测匹配的固定模式避免了移位问题。 这种固定的匹配模式不仅消除了丢失的帧,而且还减少了每个匹配的基本事实的时间偏移。
在图 3 中,我们比较了两个检测器 Mask R-CNN [21] 和 YOLOX [13],它们具有多个图像尺度,并研究了流感知和离线设置之间的性能差距。 在低分辨率输入的情况下,两个检测器的性能差距很小,因为它们都是实时运行的。 然而,随着分辨率的提高,Mask R-CNN 的性能下降会随着运行速度变慢而变大。 对于 YOLOX 来说,它的推理速度随着分辨率的增加而保持实时,因此差距没有相应拉大。
3.2. Pipeline
来自实时检测器的固定匹配模式也使我们能够训练一个可学习的模型来挖掘潜在的移动趋势并预测下一个图像帧的对象。 我们的方法包括一个基本的实时检测器、一个离线训练计划、一个在线推理策略,这些将在下面进行描述。
基地探测器。我们选择最近提出的 YOLOX [13] 作为我们的基础检测器。它继承了 YOLO 系列 [41-43] 并将其发扬到具有若干技巧的无锚框架中,例如解耦头 [48、56]、强大的数据增强 [15、58] 和高级标签分配 [12],实现实时检测器中的强大性能。它也是 CVPR 2021 自动驾驶研讨会上 Streaming Perception Challenge 的第一名解决方案 [59]。与 [59] 不同的是,我们移除了一些工程加速技巧,例如 TensorRT,并将输入比例更改为半分辨率 (600 × 960) 以确保没有 TensorRT 的实时速度。我们还丢弃了 [59] 中使用的额外数据集,即 BDD100K [57]、Cityscapes [10] 和 nuScenes [4] 用于预训练。与 [59] 相比,这些缩小的变化肯定会降低检测性能,但它们减轻了执行负担并允许进行广泛的实验。我们相信缩小的变化与我们的工作是正交的,并且可以进一步提高性能
训练。 我们在图 4 中可视化了我们的总训练管道。我们将最后一个、当前帧和下一个 gt 框构建为三元组(Ft-1,Ft,Gt+1)进行训练。 这种设计的主要原因是简单直接:为了预测物体的未来位置,不可避免地要知道每个物体的运动状态。 因此,我们将两个相邻的帧(Ft-1,Ft)作为输入,并训练模型直接预测下一帧的检测结果,由 Ft+1 的基本事实监督。 基于输入和监督的三元组,我们将训练数据集重建为 {(Ft−1, Ft, Gt+1)}nt=1,其中 nt 是总样本数。 不包括每个视频流的第一帧和最后一帧。 有了这个重建的数据集,我们可以保持随机洗牌策略进行训练,并像往常一样通过分布式 GPU 训练提高效率。
为了更好地捕捉两个输入帧之间的移动趋势,我们提出了一个双流感知模块(DFP)和一个趋势感知损失(TAL),在下一小节中介绍,以融合两帧的 FPN 特征图和 自适应地捕捉每个对象的移动趋势。
我们还研究了另一个间接任务,它并行预测当前 gt 框 Gt 和从 Gt 到 Gt+1 的对象变换的偏移量。 然而,根据下一节(第 4.2 节)中描述的一些消融实验,我们发现预测额外的偏移量总是属于次优任务。 一个原因是两个相邻帧之间的变换偏移值很小,涉及一些数值不稳定的噪声。 它也有一些不好的情况,即有时无法访问相应对象的标签(新对象出现或当前对象在下一帧中消失)。
推理。 所提出的模型以两个图像帧作为输入,与原始检测器相比,带来了近两倍的计算成本和时间消耗。 如图 5 所示,为了消除困境,我们使用一个特征缓冲区来存储前一帧 Ft-1 的所有 FPN 特征图。 在推理时,我们的模型仅提取当前图像帧的特征,然后从缓冲区中聚合历史特征。 使用这种策略,我们的模型几乎以与基本检测器相同的速度运行。 对于流的开始帧 F0,我们将 FPN 特征图复制为伪历史缓冲区来预测结果。 这种重复实际上意味着“不动”状态,静态结果与F1不一致。 幸运的是,对性能的影响很小,因为这种情况很少见。
3.3. Dual-Flow Perception Module (DFP)
给定当前帧 Ft 和历史帧 Ft-1 的 FPN 特征图,我们假设该特征应该具有两个关键信息,用于预测下一帧。 一是运动趋势,捕捉运动状态,估计运动幅度。 另一个是检测器对相应对象进行定位和分类的基本语义信息
因此,我们设计了一个双流感知(DFP)模块,用动态流和静态流对预期特征进行编码,如图 4 所示。动态流融合了两个相邻帧的 FPN 特征来学习运动信息。它首先使用共享权重 1×1 卷积层,然后使用 batchnorm 和 SiLU [40] 将两个 FPN 特征的通道数减少到一半。然后,它简单地连接这两个减少的特征来生成动态特征。我们研究了其他几种融合操作,如基于挤压和激励网络 [22] 的加法、非局部块 [52]、STN [24],其中串联显示出最佳的效率和性能(参见表 1c) .至于静态流,我们通过残差连接合理地添加了当前帧的原始特征。在后面的实验中,我们发现静态流不仅为检测提供了基本信息,而且还提高了在行驶车辆不同移动速度下的预测鲁棒性。
3.4. Trend-Aware Loss (TAL)
我们注意到流感知中的一个重要事实,其中每个对象在一帧内的移动速度是完全不同的。 变化趋势来自多个方面:它们自身的不同大小和移动状态、遮挡或不同的拓扑距离。
受观察的启发,我们引入了趋势感知损失(TAL),它根据每个对象的移动趋势采用自适应权重。 通常,我们更关注快速移动的物体,因为它们更难以预测未来状态。 为了定量测量移动速度,我们为每个对象引入了一个趋势因子。 我们计算Ft+1和Ft的ground truth box之间的IoU(Intersection over Union)矩阵,然后对Ft的维度进行max运算,得到两帧之间对应对象的匹配IoU。 这个匹配的IoU值小意味着物体移动速度快,反之亦然。 如果一个新对象出现在 Ft+1 中,则没有与之匹配的框,并且其匹配的 IoU 比平时小得多。 我们设置一个阈值 τ 来处理这种情况,并将 Ft+1 中每个对象的最终趋势因子 ωi 公式化为:
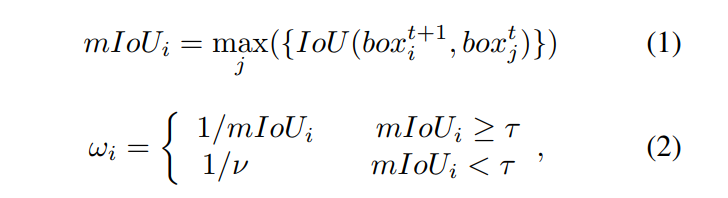
其中 maxj 表示 Ft 中框之间的最大操作,ν 是新来对象的恒定权重。 我们将 ν 设置为 1.4(大于 1)以根据超参数网格搜索减少注意力。
请注意,简单地将权重应用于每个对象的损失将改变总损失的大小。 这可能会扰乱正负样本丢失之间的平衡并降低检测性能。 受 [54, 55] 的启发,我们将 ωi 归一化为 ω^i,以保持总损失的总和不变:
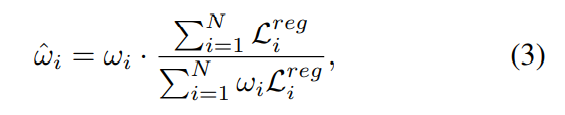
其中 L^{reg}_{i} 表示对象 i 的回归损失。 接下来,我们用 ω^i 重新加权每个对象的回归损失,总损失表示为:
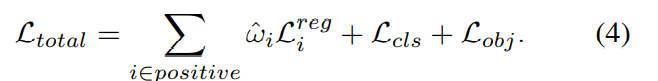
4. Experiments
4.1. Settings
数据集。 我们在视频自动驾驶数据集 Argoverse-HD [5, 26](高帧率检测)上进行了实验,其中包含来自美国两个城市的不同城市户外场景。 它具有多个传感器和高帧率传感器数据 (30 FPS)。 在[26]之后,我们只使用中心RGB相机和[26]提供的检测注释。 我们还遵循 [26] 中的 train/val 拆分,其中验证集包含 24 个视频,总共 15k 帧。
评估指标。 我们使用 SAP [26](流感知挑战工具包 [45])来评估所有实验。 SAP 是流感知的指标。 它同时考虑延迟和准确性。 与 MS COCO 度量标准 [29] 类似,它评估从 0.5 到 0.95 的 IoU(Intersection over-Union)阈值的平均 mAP 以及小型、中型和大型对象的 AP、APm、APl。
实施细节。 如果没有指定,我们使用 YOLOX-L [13] 作为我们的默认检测器。 我们所有的实验都是从 COCO 预训练模型微调 15 个 epoch。 我们在 8 个 GTX 2080ti GPU 上将批量大小设置为 32。 我们使用随机梯度下降(SGD)进行训练。 我们采用 0.001×BatchSize/64(线性缩放 [19])的学习率和 1 个 epoch 的预热策略的余弦调度。 权重衰减为 0.0005,SGD 动量为 0.9。 图像的基本输入大小为 600×960,而长边均匀范围从 800 到 1120,步幅为 16。 我们不使用任何数据增强(例如 Mo saic [18]、Mixup [58]、水平翻转等),因为馈送的相邻帧需要对齐。 对于推理,我们将输入大小保持在 600×960,并在 Tesla V100 GPU 上测量处理时间。
4.2. Ablations for Pipeline
We conduct ablation studies for the pipeline design on three crucial components: the task of prediction, the feature used for fusion, and the operation of fusion. We employ a basic YOLOX-L detector as the baseline for all experiments and keep the other two components unchanged when ablating one. In particular, all entries work in real-time (30 FPS) so that the comparison is fair.
Prediction task. We compare the two types of prediction tasks mentioned in Sec. 3.2. As shown in Tab. 1a, indirectly predicting current bounding boxes with corresponding offsets gets even worse performance than the baseline. In contrast, directly forecasting future results achieves significant improvement (+3.0 AP). This demonstrates the supremacy of directly predicting the results of the next frame.
Fusion feature. Fusing the previous and current information is important for the streaming task. For a general detector, we can choose three different patterns of features to fuse: input, backbone, and FPN pattern respectively. Technically, the input pattern directly concatenates two adjacent frames together and adjusts the input channel of the first layer. The backbone and FPN pattern adopt a 1 × 1 convolution followed by batch normalization and SiLU to reduce half channels for each frame and then concatenate them together. As shown in Tab. 1b. The results of the input and
backbone pattern decrease the performance by 0.9 and 0.7 AP. By contrast, the FPN pattern significantly boosts 3.0 AP, turning into the best choice. These results indicate that the fusing FPN feature may get a better trade-off between capturing the motion and detecting the objects.
Fusion operation. We also explore the fusion operation for FPN features. We seek several regular operators (i.e., element-wise add and concatenation) and advanced ones (i.e., spatial transformer network [24] (STN)1 and non-local network [52] (NL)2 . Tab. 1c shows the performance among these operations. We can see that the element-wise add operation drops performance by 0.4 AP while other ones achieve similar gains. We suppose that adding element-wise values may break down the relative information between two frames and fail to learn trending information. And among effective operations, concatenation is prominent because of its light parameters and high inference speed.
我们对管道设计的三个关键部分:预测任务、用于融合的特征和融合的操作进行了烧蚀研究。我们使用一个基本的YOLOX-L探测器作为所有实验的基线,并在消融其中一个时保持其他两个分量不变。特别是,所有条目都是实时工作的(30 FPS),因此比较是公平的。
预测任务。我们比较了SEC中提到的两种类型的预测任务。3.2.。如选项卡中所示。1a,间接预测具有相应偏移量的当前边界框的性能甚至比基线更差。相比之下,直接预测未来结果的效果显著提高(+3.0AP)。这展示了直接预测下一帧结果的至高无上。
融合功能。融合以前的和当前的信息对于流传输任务是重要的。对于一般的检测器,我们可以选择三种不同的特征模式进行融合:输入模式、主干模式和FPN模式。从技术上讲,输入模式直接将两个相邻的帧连接在一起,并调整第一层的输入通道。主干和FPN模式采用1×1卷积,然后进行批归一化和SIU,以减少每帧的一半信道,然后将它们级联在一起。如选项卡中所示。1B.。输入的结果和。
主干模式会使性能分别降低0.9AP和0.7AP。相比之下,FPN模式显著提升了3.0AP,成为最佳选择。这些结果表明,融合的FPN特征可以在捕获运动和检测目标之间获得更好的折衷。
核聚变手术。本文还对FPN特征的融合操作进行了探讨。我们寻找几种常规算子(即逐元相加和级联)和高级算子(即空间变换网络241和非局部网络522)。制表符。1C显示了这些操作的性能。我们可以看到,基于元素的加法操作使性能降低了0.4AP,而其他操作获得了类似的收益。我们认为,添加基于元素的值可能会破坏两个帧之间的相对信息,从而无法学习趋势信息。而在有效的运算中,级联运算因其参数轻、推理速度快而显得尤为突出。
Comparison with Kalman Filter based forecasting.
我们遵循 [26] 的实现,并在 Tab5 中报告了基于卡尔曼滤波器的预测的高级基线。 对于普通的 sAP (1×),我们的端到端方法仍然比高级基线高 0.5 AP。 此外,当我们用更快的移动(2×)模拟和评估它们时,我们的模型显示出更多的鲁棒性优势(33.3 sAP vs. 31.8 sAP)。 此外,我们的模型带来了更少的额外延迟(0.8 毫秒对 3.1 毫秒取 5 次测试的平均值)。
与最先进的比较。 我们将我们的方法与 Argoverse HD 数据集上的其他最先进的检测器进行比较。 如图 6 所示,与非实时检测器相比,实时方法显示出绝对优势。 我们还报告了 Streaming Perception Challenge 的第一名和第二名的结果。 它们涉及额外的数据集和加速技巧,而我们的方法获得了具有竞争力的性能,甚至在没有任何技巧的情况下超过了第二名的准确性。 一旦我们采用相同的技巧,我们的方法就会大大超过第一名(2.1 sAP)。
5. 结论
本文重点关注考虑处理延迟的流感知任务。 在这个指标下,我们揭示了使用具有未来预测能力的实时检测器进行在线感知的优越性。 我们进一步构建了一个带有双流感知模块和趋势感知损失的实时检测器,缓解了流感知中的时滞问题。 大量实验表明,我们的简单框架实现了最先进的性能。 它还在不同的速度设置上获得了稳健的结果。 我们希望我们简单而有效的设计能够激发未来在这项实际且具有挑战性的感知任务中的努力。
cites
project
最后
以上就是大胆发卡最近收集整理的关于【论文】【CVPR2022】Real-time Object Detection for Streaming Perception1. Introduction2. Related Works3. Methods3.2. Pipeline4. Experiments4.2. Ablations for PipelineComparison with Kalman Filter based forecasting.5. 结论cites的全部内容,更多相关【论文】【CVPR2022】Real-time内容请搜索靠谱客的其他文章。








发表评论 取消回复