摘要
解决的问题(动机):
跨域⽬标检测⽐⽬标分类更具挑战性,因为图像中存在多个对象,并且每个⽬标在未标记的⽬标域中的位置是未知的。因此,当我们调整不同物体的特征以增强探测器的可迁移性时,前景和背景的特征很容易混淆,这可能会损害探测器的可判别性。此外,以前的⽅法侧重于类别⾃适应,但忽略了⽬标检测的另⼀个重要部分,即边界框回归的⾃适应。
用什么模型或者理论(方法):
为此,我们提出了D-adapt,即解耦⾃适应,以解耦对抗适应和探测器的训练。此外,我们通过引⼊边界框适配器来填补⽬标检测中回归域适应的空⽩。
关键结果(结论):
实验表明,D-adapt在四个跨域⽬标检测任务上实现了最先进的结果,特别是在基准数据集Clipart1k和Comic2k上产⽣了17%和21%的相对改进。
1 引言
目标检测任务因其⼴泛的应⽤⽽引起了极⼤的兴趣。在过去⼏年中,深度神经⽹络的发展提⾼了目标检测器的性能[31; 14; 39]。虽然这些探测器在基准数据集上取得了出⾊的性能[11;29],但现实世界中的目标检测仍然⾯临着视点、物体外观、背景、照明、图像质量等巨⼤差异的挑战。已经观察到这种域偏移会导致性能显着下降[8]。因此,⼀些⼯作使⽤域⾃适应[37]将检测器从具有⾜够训练数据的源域转移到仅提供未标记数据的⽬标域[8; 42]。该技术成功地提⾼了检测器在⽬标域上的性能。然⽽,与目标分类相⽐,目标检测中域适应性的改善仍然相对温和。
固有的挑战来⾃三个⽅⾯。数据挑战:在对抗性训练中适应什么尚不清楚。目标级别的实例特征适配(图 1(a))可能会混淆前景和背景的特征,因为⽣成的建议可能不是真正的目标,并且可能缺少许多真正的目标(参⻅图 5 中的错误分析)。图像⽔平的全局特征适应(图1(b))可能会混淆不同目标的特征,因为每个输⼊的检测图像都有多个物体及其众多组合。像素级中的局部特征适应(图1(c))可以缓解域偏移,当偏移主要是低级时,但是当域在语义级不同时,它将举步维艰。架构挑战:虽然上述适应⽅法⿎励域不变特征,但特征的可判别性在适应过程中可能会恶化[6;5]。然⽽,可判别性对于探测器⾮常重要,因为它需要同时定位和分类物体。虽然⾃我训练[24]不会损害特征的可判别性,但它们会受到确认偏差的影响,特别是当域转移很⼤时。损失挑战:以前的⽅法主要探索类别适应,忽略了回归适应,这对检测性能有困难但很重要。
为了克服这些挑战,我们提出了⼀个通⽤框架 - D-adapt,即解耦适应。由于直接在探测器的特征上进⾏对抗性对准可能会损害其判别性(架构挑战),因此我们通过引⼊与参数⽆关的类别适配器,将对抗性适应与探测器的训练分离(⻅图1(d))。为了填补在跨域检测(损失挑战)中回归域⾃适应的空⽩,我们引⼊了与检测器和类别适配器分离的另⼀个边界框适配器。为了应对数据挑战,我们建议针对特定的适应任务调整对象级数据分布。这可以通过D-adapt轻松实现,其中不同的适配器可以具有完全不同的输⼊数据分布。例如,在类别⾃适应步骤中,我们⿎励输⼊提案将 IoU1 接近 0 或 1,以更好地满⾜低密度分离假设,⽽在边界框⾃适应步骤中,我们⿎励输⼊提案将 IoU 置于 0.5 和 1 之间,以简化边界框定位任务的优化。
图一:对比不同的技术
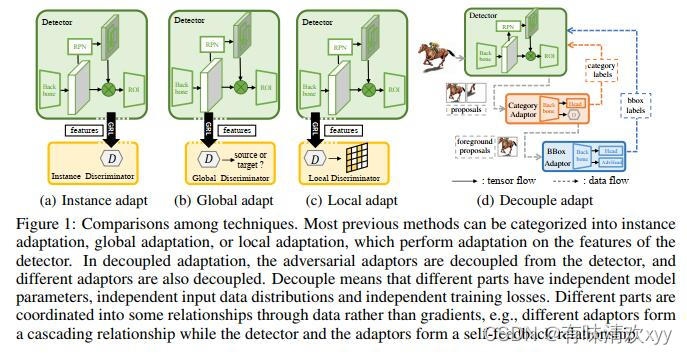
图 1:技术之间的比较。大多数先前的方法可以分为实例适应,全局适应或局部适应,它们对探测器的特征进行适应。在解耦自适应中,对抗性适配器与检测器分离,不同的适配器也分离。解耦意味着不同的部分具有独立的模型参数、独立的输入数据分布和独立的训练损失。不同的部分通过数据而不是梯度协调成一些关系,例如,不同的适配器形成级联关系,而检测器和适配器形成自我反馈关系。
这项⼯作的贡献总结为三重。(1)引⼊D-adapt框架进⾏跨域目标检测,⼀般为两级和单级检测器。(2)提出了⼀种有效的⽅法来适应边界框定位任务,该⽅法被现有⽅法所忽略,但对于实现卓越的最终性能⾄关重要。(3)我们进⾏了扩展实验,并验证了我们的⽅法在四个⽬标检测任务上实现了最先进的性能,并且在Clipart1k和Comic2k上产⽣了17%和21%的相对改进。
2 相关工作
通⽤域适应用于分类。提出域适应以克服跨域的分布转移。在分类设置中,⼤多数域适应⽅法都基于矩匹配或对抗适应。矩匹配⽅法 [49;34] 通过最⼩化特征空间中的分布差异来对⻬分布。与⽣成对抗⽹络[15]具有相同的精神,对抗性适应[12; 35]引⼊了域鉴别器来区分源和⽬标,然后⿎励特征提取器欺骗鉴别器并学习域不变特征。但是,将这些⽅法直接应⽤于对象检测会产⽣不令⼈满意的效果。困难在于,目标识别的图像通常包含多个对象,因此图像的特征可能具有复杂的多模态结构[19; 56; 5],使得图像级特征对⻬有问题[56; 19]。
通⽤域适应用于回归。⼤多数为分类设计的域适应⽅法在回归任务上效果不佳,因为回归空间是连续的,没有明确的决策边界[21]。提出了⼀些特定的回归算法,包括不⼀定权重[53]或学习不变表示[38;36]。RSD [7]定义了学习可转移表示的⼏何距离,⽽视差差异[55]提出了回归问题中分布距离的上限。然⽽,以前的⽅法主要在简单任务上进⾏测试,⽽本⽂则将域适应扩展到⽬标定位任务。
⽤于目标检测的领域适应。DA-Faster [8] 在图像级和实例级执⾏特征对⻬。SWDA [42]提出局部特征的强对⻬⽐全局特征的强对⻬更有效。通过更多地关注前景像素来感知对⻬。HTCN [5] 按层次结构校准特征图表达的迁移能⼒。[57]提出提取前景区域,并采⽤粗细特征适应性。ATF [18]引⼊了⼀种⾮对称三向⽅法,以解释域之间标记统计信息的差异。CRDA [52] 和 MCAR [56] 使⽤多标签分类作为辅助任务来规范特征。然⽽,尽管在⼤多数上述⽅法中输出域不变特征以欺骗域鉴别器的辅助任务可以提⾼可迁移性,但它也损害了检测器的可判别性。相反,我们将对抗性适应与检测器的训练分离,因此适配器可以专注于域之间的迁移,并且检测器可以专注于提⾼可判别性,同时享受适配器带来的可迁移性。
使⽤伪标签进⾏⾃我训练。伪标签[28]利⽤模型本身对未标记的数据进⾏标记,⼴泛⽤于⾃我训练。为了⽣成可靠的伪标签,时间集成[27] 为每个样本保持指数移动平均预测,⽽均值教师[48] 在不同的训练迭代中平均模型权重以获得教师模型。深度互学[54]在彼此的监督下训练⼀批学⽣模型。FixMatch [46] 使⽤模型对弱增强图像的预测为强增强图像⽣成伪标签。⽆偏教师[33]将师⽣范式引⼊半监督目标检测(SS-OD)。最近的⼯作[20;23;24]利⽤跨域目标检测中的⾃我训练,并将最可靠的预测作为伪标签。MTOR [3]使⽤平均教师框架,UMT [10]在⾃我培训中采⽤蒸馏和CycleGAN[58]。然⽽,⾃我训练存在确认偏差的问题[1;4]:学⽣的表现将受到教师的表现的限制。虽然伪标签也⽤于我们提出的D-adapt,但它们是由具有独⽴参数和与检测器不同任务的适配器⽣成的,从⽽减轻了⾃我训练中过于紧密的关系的确认偏差。
3 提出的方法-D-adapt
3.1 D-adapt 框架
为了应对第1节中提到的架构挑战,我们提出了D-adapt框架,该框架有三个步骤:(1)将原始的跨域检测问题解耦为⼏个⼦问题(2)设计适配器以解决每个⼦问题(3)协调不同适配器与检测器之间的关系。
由于⾃适应可能会损害探测器的可判别性,因此我们通过引⼊与参数⽆关的类别适配器,将类别适应与探测器的训练分离(⻅图1(d))。对抗性适应仅在类别适配器的特征上执⾏,因此不会损害探测器定位物体目标的能⼒。为了填补⽬标检测中回归域适应的空⽩,我们需要对边界框回归进⾏适应。然⽽,图 6(c) 中的特征可视化显示,同时包含类别和位置信息的特征没有明显的聚类结构,对抗性对⻬可能会损害其可判别性。此外,常⻅的类别⾃适应⽅法对回归任务也⽆效[21],因此我们将类别适应和边界框适应解耦,以避免它们相互⼲扰。第3.2节和第3.3节将详细介绍类别适配器和边界框适配器的设计。在本节中,我们将假设已经获得了这两个适配器。
为了协调不同任务的适应,我们在适配器之间保持级联关系。在级联结构中,后级适配器可以利⽤前⼀个适配器获得的信息来更好地适应,例如在边界框适配步骤中,类别适配器会选择前景候选框,以⽅便边界框适配器的训练。与多任务相⽐学习关系,我们需要仔细平衡不同适应损失的权重,级联关系⼤⼤降低了超参数选择的难度,因为每个适应器只有⼀个适应损失。由于适配器是专⻔为跨域任务设计的,因此它们在⽬标域上的预测可以⽤作检测器的伪标签。另⼀⽅⾯,探测器⽣成候选框训练适配器,更⾼质量的候选框可以提⾼适应性能(详⻅表5)。这使得探测器和适配器之间的⾃反馈关系成为可能。
为了很好地初始化这个⾃反馈循环,我们⾸先使⽤Ldets在源域上预训练检测器Gdet。使⽤预先训练的Gdet,我们可以推导出两个新的数据分布,源的 候选框分布 Ds 和⽬标候选框分布Dt。每个提案都由图像x的裁剪、其对应的边界框bdet、预测类别ydet和类置信度cdet组成。我们可以⽤⼀个基本事实边界框和类别标签来注释每个源域提案xs∈ ,类似地,在FastRCNN[13]中标注每个RoI,并使⽤这些标签来训练适配器。反过来,对于每个⽬标提案 x∈ ,适配器将提供类别伪标签 和框伪标签 来训练 RoI 头,
其中 Ifg 是指示它是否为前景类别的函数。请注意,回归损失仅针对前景锚点进⾏校正。在通过优化等式2获得更好的检测器后,我们可以⽣成更⾼质量的建议,从⽽更好地类别适应和边界框适应。此过程可以多次迭代,详细的优化过程在算法1 中进⾏了总结。
算法一

请注意,我们的D-adapt框架不会在推理阶段引⼊任何计算开销,因为适配器独⽴于检测器,并且可以在检测过程中移除。此外,D-adapt不依赖于特定的探测器,因此探测器可以被SSD [32],RetinaNet[30]或其他探测器取代。
3.2 类别自适应
D-adapt将类别适应性与探测器的训练分离,以避免损害其判别性⽆法正常⼯作。类别调整的⽬标是使⽤标记的源域候选框 (xs,ys) ∈Dprops来获得未标记的⽬标域候选框的相对准确的分类 yclst ∈ Dpropt。虽然可以采⽤通⽤的域⾃适应⽅法,如DANN[12],但这个任务有其⾃身的数据挑战 - 输⼊数据分布不能很好地满⾜低密度分离假设,即提案和前景实例的交并⽐可能是0和1之间的任何值(⻅图2(a)),这将阻碍域适应[21]。回想⼀下,在标准⽬标检测中,IoU 介于 0.3 和 0.7 之间的建议将被删除,以离散化输⼊空间并简化分类优化。然⽽,它很难⽤于领域适应问题,因为我们⽆法获得⽬标候选框的基本事实IoU。
图二:类别自适应
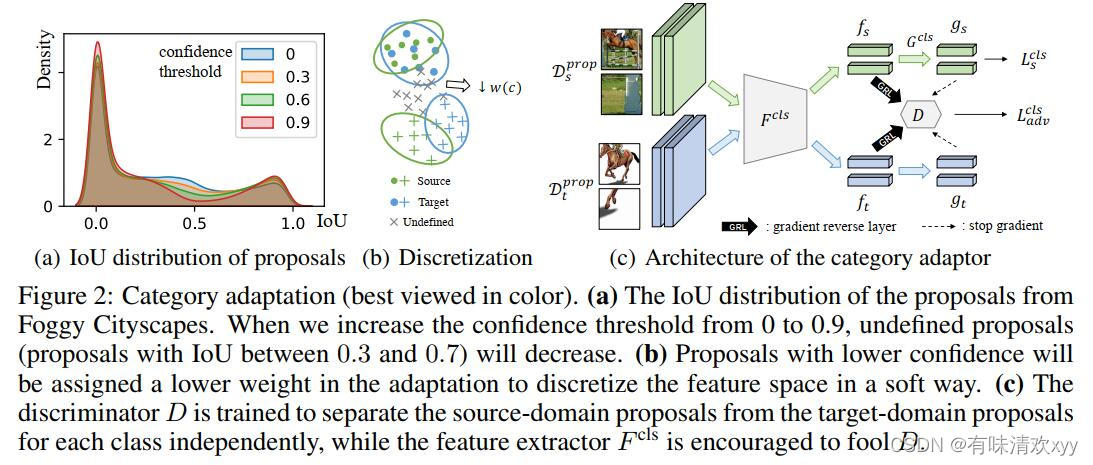
为了克服数据挑战,我们使⽤每个候选框的置信度以柔和的⽅式离散化输⼊空间,即当候选框具有⾼置信度的cdet作为前景或背景时,它在适应训练中应具有更⾼的权重w(cdet),反之亦然(⻅图2(b))。这将减少既不是前景也不是背景的候选框的参与,并且在概率意义上提⾼输⼊空间的离散性。我们也重采样背景候选框并增加他们到进⼀步增加离散性。优化判别器D的⽬标表示为
其中特征表示 f = Fcls(x) 和类别预测 g =Gcls(f) 都馈送到域鉴别器 D 中(参⻅图 2(c))。这将⿎励以有条件的⽅式对⻬的特征[35],从⽽避免⼤多数⽬标候选框与源域上的主导类别保持⼀致。特征提取器 F cls 的⽬标是在源域上分离不同的类别,并学习域不变特征来欺骗鉴别器,
其中LCE是交叉熵损失,λ是平衡源域风险和域对抗损失的权重。经过获得的适应的分类器之后,我们可以对于每个候选框 生成类别伪标签 。
3.3 边界框自适应
D-adapt将边界框适应与类别适应分离,以避免它们与其他类别的⼲扰。框适配的⽬的是利⽤标记的源域前景候选框 来获得未标记的⽬标域候选框 的边界框标签 。由于⽬标域提案的基本事实标签是未知的,因此我们使⽤在类别适应步骤中获得的预测,即 。
在 RCNN [14] 之后,我们采⽤特定于类的边界框回归量,该回归函数预测每个 K 前景类的边界框回归偏移量 ,按 k 索引。在源域上,我们为每个候选框提供了基本实数类别和边界框标签,因此我们使⽤平滑 L1 损失来训练回归器,
其中 是回归预测, 是基实数类别,v表示由 计算出的基实边界框偏移量。但是,由于域移位,很难在⽬标域上获得 ⼀个令⼈满意的回归器。
为了应对这⼀损失挑战,我们提出了⼀种基于最新域适应理论的IoU视差差异⽅法[55]。如图 3(a) 所示,我们引⼊了⼀个对抗性回归器Greg⽬标域主回归器最⼤最⼩化差异。我们采⽤通⽤的交并⽐(GIoU) [41] ⽽不是 smoothL1 来定义两个边界框之间的差值,因为GIoU 总是在 0 和 1 之间有界,⽽ smoothL1 是⽆界的,在最⼤化期间会导致数值爆炸。对抗回归器的优化⽬标为
图三:边界框自适应
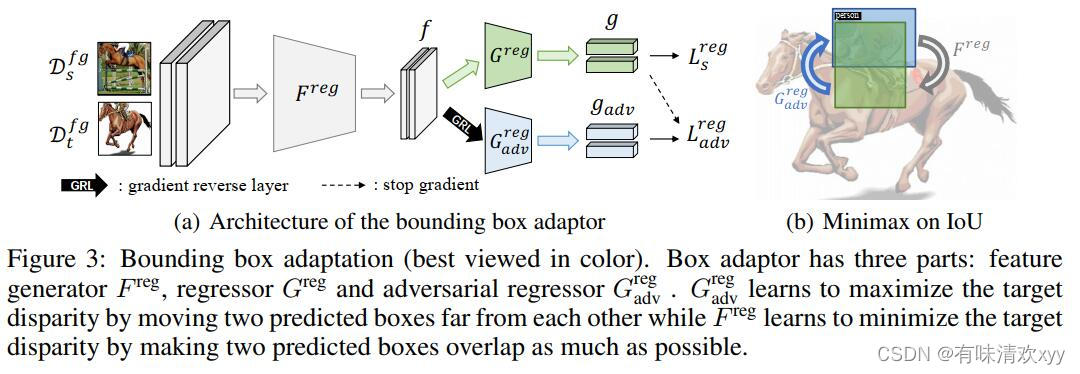
图 3:边界框⾃适应(最好以彩⾊查看)。Box适配器有三个部分:特征⽣成器Freg,回归器Greg和对抗回归器Greg。Greg通过移动两个预测框彼此相距较远来学习最⼤化⽬标差异,⽽Freg则通过使两个预测框尽可能重叠来最⼩化⽬标差异。
请注意,源域上的 GIoU损失仅在与地⾯真实类别ygts对应的框中定义,⽽在⽬标域上仅在与预测类别yclst关联的框中定义。等式6指导对抗回归器在源域上正确预测,同时在⽬标域上犯尽可能多的错误(图3(b))。然后,⿎励特征提取器Freg输出域不变特征以避免这种情况,
其中η是源⻛险和对抗性损失之间的权衡。在获得适配的回归器之后,我们可以为每个候选框 ⽣成框伪标签 。
4 实验
4.1 数据集
使⽤以下六个⽬标检测数据集:Pascal VOC[11],Clipart [20],Comic [20],Sim10k[22],Cityscapes [9]和FoggyCityscapes[43]。Pascal VOC 包含 20 类常⻅的真实世界对象和 16, 551 张图像。Clipart 包含 1000张图像,与 PascalVOC 共享 20 个类别。Comic2k 包含 1000 张训练图像和 1000 张测试图像,与 PascalVOC 共享 6 个类别。Sim10k 有 10, 000 张图像,包含 58, 701个汽⻋类别的边界框,由游戏引擎 GrandTheft Auto 渲染。Cityscapes 和FoggyCityscapes 都有2975 张训练图像和500 张验证图像,其中包含 8 个对象类别。在[42]之后,我们评估了不同⽅法在以下四个领域适应任务上的域适应性能,VOC到剪贴画,VOC到Comic2k,Sim10k到Cityscapes,Cityscapes到FoggyCityscapes,并报告阈值为0.5的平均精度(mAP)。
4.2 实现细节
第 1 阶段:源域预训练。在基本实验中,采⽤以ResNet-101 [16]或VGG-16[45]为⻣⼲的Faster-RCNN[40],并在源域上预训练,学习率为0.005,进⾏12k迭代。
第2阶段:类别适应。类别适配器具有与探测器相同的主⼲,但具有简单的分类头。它使⽤ SGD 优化器训练 10k 次迭代,初始学习率为 0.01,动量为 0.9,每个域的批⼤⼩为 32。鉴别器D是DANN [12]之后的三层全连接⽹络。对于所有实验,λ 保持为 1。当 c > 0.5时,w(c) 为 1,当 0.3 <c ≤ 0.5 时为 5 × (c −0.3),否则为 0。
第3阶段:边界框适应。边界框适配器具有与检测器相同的主⼲,但具有简单的回归头(双层卷积⽹络)。训练超参数(学习速率、批⼤⼩等)与类别适配器的训练参数相同。对于所有实验,η保持在 0.1。
第 4 阶段:⽬标域伪标签训练。检测器在⽬标域上进⾏4k迭代训练,初始学习率为2.5×10-4,并呈指数降低到2.5×10-5。适配器和检测器以 T = 3 次迭代的替代⽅式进⾏训练。我们使⽤ 1080Ti GPU 对公共数据集执⾏所有实验。代码将在 https:// github.com/thuml/Transfer-Learning-Library 处提供。
4.3 与最先进的方法对比
不同域之间的适应。我们⾸先使⽤ PascalVOC 数据集作为源域,将 Clipart 作为⽬标域,在不同的域上展示实验。表1表明,我们提出的⽅法在mAP上⽐最先进的⽅法⾼出7.0分。图 4 显示了⽬标域中的⼀些定性结果。我们还与⽆偏教师[33]进⾏了⽐较,后者是半监督目标检测中最先进的⽅法,它从教师模型在⽬标域上⽣成伪标签。由于域偏移较⼤,教师检测模型的预测不可靠,因此效果不佳。相⽐之下,我们的⽅法通过从不同模型(适配器)⽣成伪标签来缓解确认偏差问题。
表一和图四:

表二
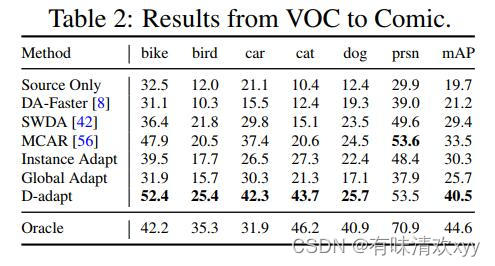
我们还使⽤ Comic2k作为⽬标域,它与Pascal VOC 和许多⼩对象具有⾮常不同的⻛格。如表2所示,图像级和实例级特征适应都将陷⼊可迁移性和可判别性的困境,并且在这个困难的数据集上效果不佳。相⽐之下,我们的⽅法通过将对抗性适应与探测器的训练分离来有效地解决这个问题,并且与最先进的技术相⽐,将mAP提⾼了7.0。
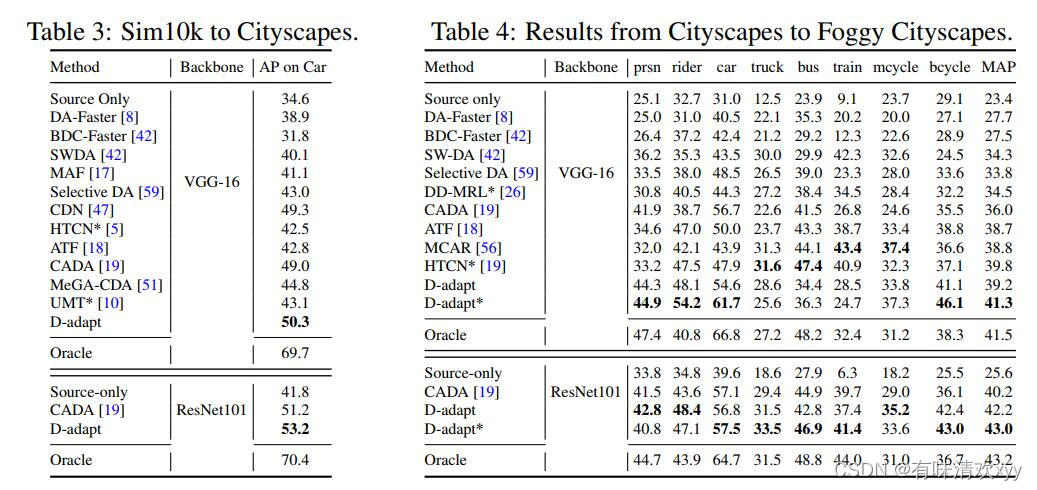
从合成图像到真实图像的⾃适应。我们使⽤ Sim10k 作为源域,使⽤ Cityscapes 作为⽬标域。在[42]之后,我们评估了城市景观的验证拆分,并报告了汽⻋上的mAP。表 3 显示我们的⽅法超越了所有其他⽅法。
相似域之间的自适应。我们在Cityscapes到FoggyCityscapes执行自适应,在表四中报告。注意到两个域之间相对地相似,自适应的性能也接近理想的结果。
表三和表四:
4.4 消融实验
在这⼀部分中,我们将分析探测器和适配器的性能。表示nij是类i预测为类j的提案数,ti是i类的提案总数,N是类(包括背景)的数量,然后我们使⽤
来衡量类别适配器的整体性能。我们使⽤预测边界框和地⾯实况框(即mIoUreg)之间的交集来测量边界框适配器的性能。所有消融均在 VOC →clipart上执⾏,迭代 T 保持1 以进⾏公平⽐较。
表六:
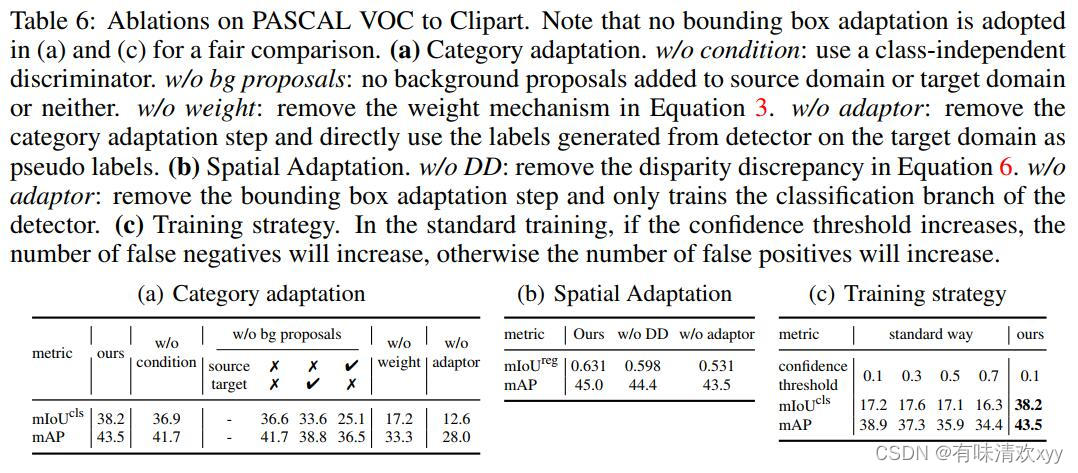
表6:PASCAL VOC到clipart上的消融。请注意,为了进⾏公平的⽐较,(a)和(c)中没有采⽤边界框适应。(a) 类别⾃适应。w/o condition:使⽤与类⽆关的鉴别器。w/o bg 候选框:没有将背景候选框添加到源域或⽬标域,或者两者都不是。w/o weight:去掉等式3中的权重机制。w/oadaptor:删除类别适应步骤,直接将⽬标域上的检测器⽣成的标签⽤作伪标签。(b) 空间⾃适应。w/o DD:消除等式 6 中的视差差异。⽆适配器:移除边界盒适配步骤,只训练探测器的分类分⽀。(c) 训练策略。在标准训练中,如果置信阈值增加,则漏检数将增加,否则误检数将增加。
对类别的消融适应。表6(a)显示了第3.2节中提到的⼏种具体设计的有效性。其中,权重机制的影响最⼤,表明低密度假设在对抗性适应中的必要性。为了验证这⼀点,我们假设每个提案的基本事实IoU是已知的,然后在训练类别适配器时选择IoU⼤于某个阈值的提案。表5显示,随着前景概率的IoU阈值从0.05提⾼到0.7,类别适配器的精度将从36.1增加到51.4,这表明了低密度分离假设的重要性。
表五:

消融在边界框适应上。表6(b)表明,最⼩化视差差异可提⾼边界框适配器的性能,⽽边界框适应可提⾼检测器在⽬标域中的性能。边界框适应带来的增益是⼀致的,例如当T = 3时,它仍然可以将mAP从47.0提⾼到49.1。
⽤伪标签消融训练策略。在等式2中,仅计算提案所在区域的损失,⽽忽略与提案重叠的锚点区域。在这⾥,我们将此策略与⾃我训练中的常⻅做法进⾏⽐较-以低置信度过滤出边界框,然后标记与这些框重叠的每个提案。虽然这些边界框的类别标签也是从类别适配器⽣成的,但这些⽣成的建议的准确性很低(⻅表6(c))。相⽐之下,我们的策略更加保守,提案上的mIoUcls和探测器的最终mAP都更⾼。
4.5 分析
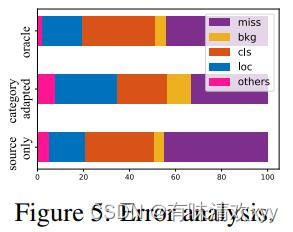
错误分析。图 5 给出了 VOC->clipart上每个模型的误差百分⽐之后的偏差百分⽐。⽬标域中的主要错误来⾃:Miss(被视为背景的基本事实)和Cls(clas-isified不正确)。Loc(分类正确但定位不正确)误差略少,但仍然不能忽视,特别是在类别适应之后,这意味着在目标检测中必须进⾏边界框适应。类别⾃适应可以有效降低Cls误差的⽐例,同时增加Loc误差的⽐例,因此在类别适配器之后级联边界框适配器是合理的。
图五:
超越Faster-RCNN。如表7所示,我们的方法应用单阶段目标检测器RetinaNet,其中提高mAP19.8在VOC->Clipart。
表七

特征可视化。
图六

5 讨论和结论:
我们的⽅法在⼏个基准数据集上取得了相当⼤的改进,⽤于领域适应。在实际部署中,通过使⽤更强的适配器可以进⼀步提⾼检测性能,⽽不会引⼊任何计算开销,因为适配器可以在推理过程中被移除。还可以通过将更多专⻔设计的适配器级联,将 D-adapt 框架扩展到其他检测任务,例如实例分割和关键点检测。我们希望D-adapt对于检测任务的更⼴泛应⽤有⽤。
最后
以上就是彩色秀发最近收集整理的关于【ICLR2022】DECOUPLED ADAPTATION FOR CROSS-DOMAIN OBJECT DETECTION 解耦自适应用于跨域目标检测的全部内容,更多相关【ICLR2022】DECOUPLED内容请搜索靠谱客的其他文章。








发表评论 取消回复