类似于博文《 paper survey(2019.06.05)——卷积网络feature map的传递与利用》
本博文也是系列论文的阅读笔记(基本都是CVPR和ICCV的论文)。
对于跟本博文相关的论文会展开描述,对于不相关的仅仅列出题目。
目录
《G2DeNet: Global Gaussian Distribution Embedding Network and Its Application to Visual Recognition》
《Is Second-order Information Helpful for Large-scale Visual Recognition?》
《Second-order Attention Network for Single Image Super-Resolution》
《CNN in MRF: Video Object Segmentation via Inference in A CNN-Based Higher-Order Spatio-Temporal MRF》
《CodeSLAM — Learning a Compact, Optimisable Representation for Dense Visual SLAM》
《Towards Scene Understanding: Unsupervised Monocular Depth Estimation with Semantic-aware Representation》
《Weakly-Supervised Discovery of Geometry-Aware Representation for 3D Human Pose Estimation》
《Object Counting and Instance Segmentation with Image-level Supervision》
《PoTion: Pose MoTion Representation for Action Recognition》
《Higher-order Pooling of CNN Features via Kernel Linearization for Action Recognition》
《Covariance Pooling for Facial Expression Recognition》
《Deep Covariance Descriptors for Facial Expression Recognition》
《Second-order Convolutional Neural Networks》
《UniformFace: Learning Deep Equidistributed Representation for Face Recognition》
《Representation Similarity Analysis for Efficient Task taxonomy & Transfer Learning》
《End-to-End Learning of Motion Representation for Video Understanding》
《Self-Supervised Representation Learning by Rotation Feature Decoupling》
《Semantic Video CNNs through Representation Warping》
《Geometry Guided Convolutional Neural Networks for Self-Supervised Video Representation Learning》
《Global Second-order Pooling Convolutional Networks》
《Squeeze-and-Excitation Networks》
《SORT: Second-Order Response Transform for Visual Recognition》
《FASON: First and Second Order Information Fusion Network for Texture Recognition》
《Higher-Order Occurrence Pooling for Bags-of-Words: Visual Concept Detection》
《End-to-End Efficient Representation Learning via Cascading Combinatorial Optimization》
《CNN Driven Sparse Multi-Level B-spline Image Registration》
《A Novel Space-Time Representation on the Positive Semidefinite Cone for Facial Expression Recognition》
《Learning Deep Descriptors with Scale-Aware Triplet Networks》
《Higher-Order Minimum Cost Lifted Multicuts for Motion Segmentation》
《Diversify and Match: A Domain Adaptive Representation Learning Paradigm for Object Detection》
《High-order Tensor Regularization with Application to Attribute Ranking》
《T-Net: Parametrizing Fully Convolutional Nets with a Single High-Order Tensor》
《Performance Guaranteed Network Acceleration via High-Order Residual Quantization》
《Defense against Adversarial Attacks Using High-Level Representation Guided Denoiser》
《A Simple Pooling-Based Design for Real-Time Salient Object Detection》
《Local Log-Euclidean Multivariate Gaussian Descriptor and Its Application to Image Classification》
《Attend and Interact: Higher-Order Object Interactions for Video Understanding》
《Representation Flow for Action Recognition》
《Learning Spatio-Temporal Representation with Local and Global Diffusion》
《RAID-G: Robust Estimation of Approximate Infinite Dimensional Gaussian with Application to Material Recognition》
《Scale-Adaptive Neural Dense Features: Learning via Hierarchical Context Aggregation》
《Deep High-Resolution Representation Learning for Human Pose Estimation》
《Optical Flow Guided Feature: A Fast and Robust Motion Representation for Video Action Recognition》
《Blob Reconstruction Using Unilateral Second Order Gaussian Kernels with Application to High-ISO Long-Exposure Image Denoising》
《Self-supervised Spatio-temporal Representation Learning for Videos by Predicting Motion and Appearance Statistics》
《Building Detail-Sensitive Semantic Segmentation Networks with Polynomial Pooling》
《Uncertainty Guided Multi-Scale Residual Learning-using a Cycle Spinning CNN for Single Image De-Raining》
《Scale-Transferrable Object Detection》
《G2DeNet: Global Gaussian Distribution Embedding Network and Its Application to Visual Recognition》
novel trainable layer of a global Gaussian as an image representation plugged into deep CNNs for end-to-end learning.
The challenge is that the proposed layer involves Gaussian distributions whose space is not a linear space, which makes its forward and
backward propagations be non-intuitive and non-trivial. To tackle this issue, we employ a Gaussian embedding strategy which respects the structures of both Riemannian manifold and smooth group of Gaussians (黎曼流形与高斯光滑群).
To represent images, the probability distributions are widely used as they generally have capability to model abundant statistics of features, producing fixed size representations regardless of varying feature sizes (为了表示图像,概率分布被广泛使用,因为它们通常能够对丰富的特征统计进行建模,生成固定大小的表示,而不管特征大小如何。)
这样的一个思想很好理解。应该就是传统的feature map大小会变化,但是对于统计特征而言,不care大小,所以可能更加好?那么本文就是获取统计特征的。
combining parametric probability distributions modeling into deep CNNs still is an open problem.
use global Gaussians as image representations and propose a global Gaussian embedding layer to combine them in deep CNN architectures. we explicitly take advantage of the geometry of Gaussians (高斯几何) by considering their parameters (i.e., the mean vectors and covariance matrices) rather than using approximated embeddings of distributions in DMMs.
《Is Second-order Information Helpful for Large-scale Visual Recognition?》
By stacking layers of convolution and nonlinearity, convolutional networks (ConvNets) effectively learn from lowlevel to high-level features and discriminative representations.
adequat(充足的) exploration of feature distributions is important for realizing full potentials of ConvNets. However, state-of-theart
works concentrate only on deeper or wider architecture design, while rarely exploring feature statistics higher than first-order.
本文提出采用covariance pooling(接下来会写一篇博客专门介绍这一个结构)

The main challenges involved are robust covariance (协方差) estimation given a small sample of large-dimensional features and usage of the manifold structure of covariance matrices (协方差矩阵的流形结构). To address these challenges, we present a Matrix Power Normalized Covariance (MPNCOV) method.
most ConvNets concentrate only on designing wider or deeper architectures, rarely exploring statistical information higher than first-order.
we perform covariance pooling of the last convolutional features rather than the commonly used first-order pooling, producing covariance matrices as global image representations.
The statistics higher than first-order has been successfully used in both classical and deep learning based classification scenarios.
《Second-order Attention Network for Single Image Super-Resolution》
most of the existing CNN-based SISR methods mainly focus on wider or deeper architecture design, neglecting to explore the feature correlations of intermediate layers, hence hindering the representational power of CNNs.
为此,本文提出a second-order attention network (SAN) for more powerful feature expression and feature correlation learning
a novel trainable second-order channel attention (SOCA) module is developed to adaptively rescale the channel-wise features by using second-order feature statistics for more discriminative representations.
present a non-locally enhanced residual group (NLRG) structure, which not only incorporates (合并) non-local operations to capture long-distance spatial contextual information, but also contains repeated local-source residual attention groups (LSRAG) to learn increasingly abstract feature representations.
contributions:
1、a deep second-order attention network (SAN)
2、propose second-order channel attention (SOCA) mechanism to adaptively rescale features by considering feature statistics higher than first-order. Such SOCA mechanism allows our network to focus on more informative features and enhance discriminative learning ability.
3、non-locally enhanced residual group (NLRG) structure to build a deep network, which further incorporates non-local operations to capture spatial contextual information, and share-source residual group structure to learn deep features. Besides, the share-source residual group structure through sharesource skip connections could allow more abundant information from the LR input to be bypassed and ease the training of the deep network.
(关于non-local可以参考博文《学习笔记之——non-local》)
网络结构如下图所示。SAN mainly consists of four parts: shallow feature extraction, non-locally enhanced residual group (NLRG) based deep feature extraction, upscale module, and reconstruction part.
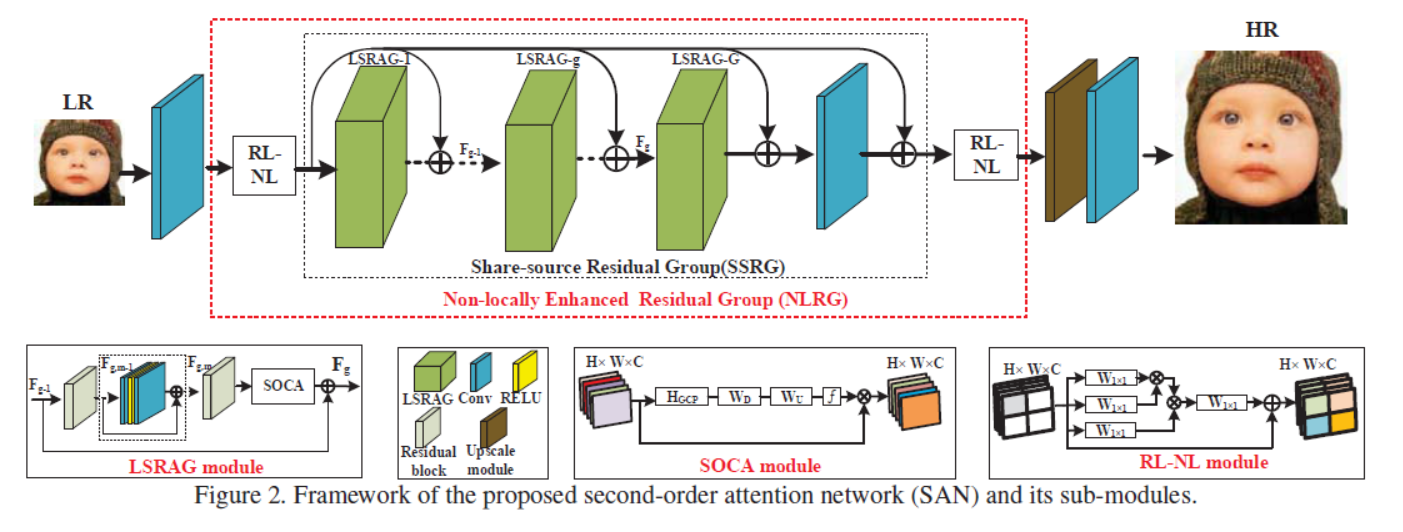
region-level non-local (RL-NL) modules
one share-source residual group (SSRG) structure.
second-order channel attention (SOCA)
local-source residual attention group (LSRAG)
the share-source skip connection (SSC) is introduced in NLRG to not only facilitate the training of our deep network, but also to bypass abundant low-frequency information from LR images
The nonlocal neural network is proposed to capture the computation of long-range dependencies throughout the entire image for high-level tasks.
- global-level non-local operations require unacceptable computational burden, especially when the size of feature is large;
- it is empirically shown that non-local operations at a proper neighborhood size are preferable for low-level tasks (经验表明,对于低层次的任务,在适当的邻域规模下进行非局部操作是可取的。)
Second-order Channel Attention (SOCA)(这个模块才是用了second order特征,所以在此仅仅关注这个模块)
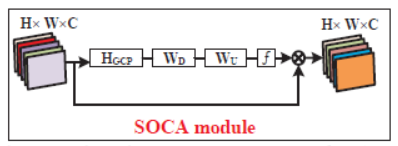
On the other hand, recent works [19, 21] have shown that second-order statistics in deep CNNs are more helpful for more discriminative representations than first-order ones.

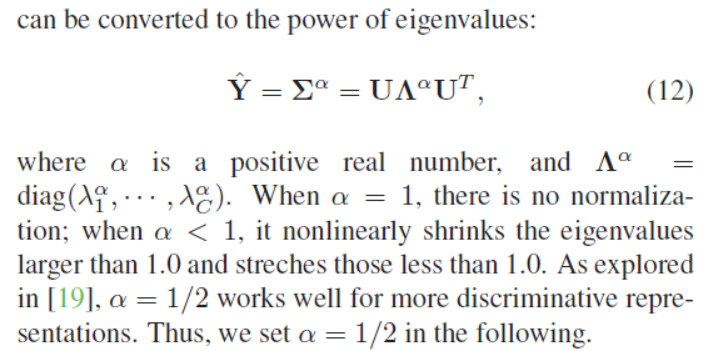
HGCP (·) denotes the global covariance pooling function.Compared with the commonly used first-order pooling (e.g., global average pooling), our global covariance pooling explores the feature distribution and captures the feature statistics higher than first-order for more discriminative representations.

《CNN in MRF: Video Object Segmentation via Inference in A CNN-Based Higher-Order Spatio-Temporal MRF》
Specifically, for a given object, the probability of a labeling to a set of spatially neighboring pixels can be predicted by a CNN trained for this specific object. As a result, higher-order, richer dependencies among pixels in the set can be implicitly modeled by the CNN.
we instead use a CNN to encode even higher-order spatial potentials over pixels.
contributions
1、novel spatio-temporal Markov Random Field (MRF) model for the video object segmentation problem.
The novelty of the model is that the spatial potentials are encoded by CNNs trained for objects of interest, so higher-order dependencies among pixels can be modeled to enforce the holistic segmentation of object instances(实施对象实例的整体分割).
《CodeSLAM — Learning a Compact, Optimisable Representation for Dense Visual SLAM》
dense representation
《Towards Scene Understanding: Unsupervised Monocular Depth Estimation with Semantic-aware Representation》
本文是关于Monocular depth estimation(单目深度估计)的
Semantic-aware Representation(语义感知表示)
《Weakly-Supervised Discovery of Geometry-Aware Representation for 3D Human Pose Estimation》
geometry-aware 3D representation for the human pose to address this limitation by using multiple views in a simple auto-encoder model at the training stage and only 2D keypoint information as supervision. (3Dfeature的表示)
《Object Counting and Instance Segmentation with Image-level Supervision》
Common object counting in a natural scene is a chal- lenging problem in computer vision with numerous real-world applications.(本文应该是关于目标计数的)
Existing image-level supervised common object counting approaches only predict the global object count and rely on additional instance-level supervision to also determine object locations.
image-level supervised density map estimation for common object counting and demonstrate its effectiveness in image-level supervised instance segmentation.
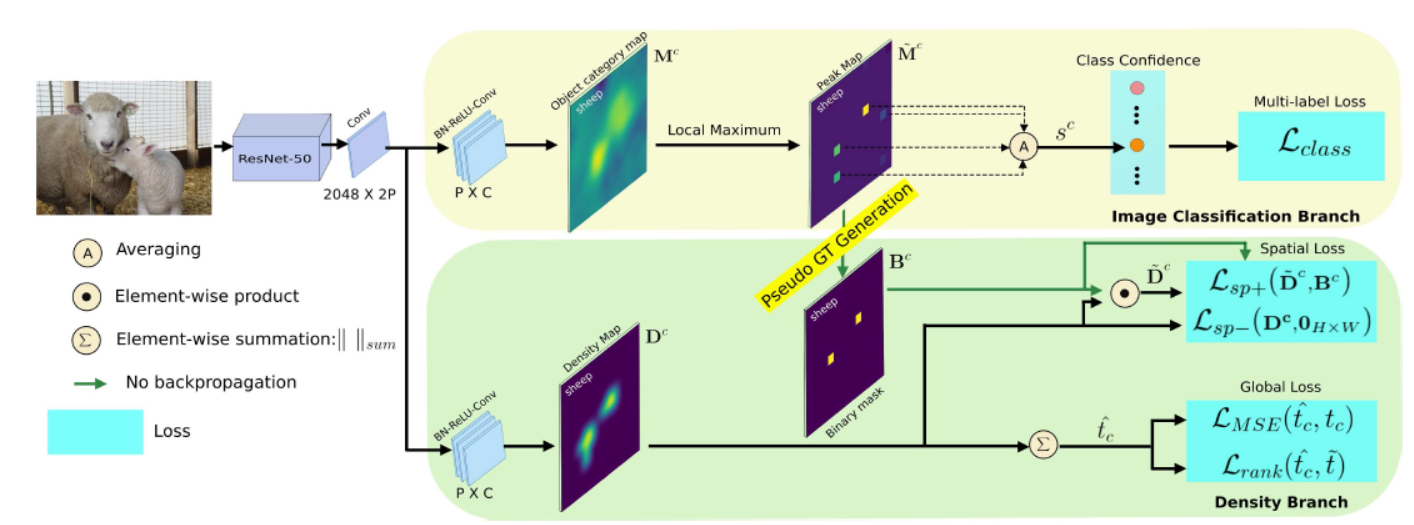
(感觉也是有点类似于noise level map的思想)
《PoTion: Pose MoTion Representation for Action Recognition》
Most state-of-the-art methods for action recognition rely on a two-stream architecture that processes appearance and motion independently.
in this paper,we claim that considering them jointly offers rich information for action recognition.
propose a novel clip-level representation that encodes human pose motion, called PoTion
《Higher-order Pooling of CNN Features via Kernel Linearization for Action Recognition》
Most successful deep learning algorithms for action recognition extend models designed for image-based tasks such as object recognition to video. Such extensions are typically trained for actions on single video frames or very short clips, and then their predictions from sliding-windows over the video sequence are pooled for recognizing the action at the sequence level. Usually this pooling step uses the first-order statistics of frame-level action predictions.(其实类似于sencond order SR的那篇论文,也是说,传统的方法是一阶特征,这里采用高阶特征)
we introduce Higher-order Kernel (HOK) descriptors generated from the late fusion of CNN classifier scores from all the frames in a sequence.
Note that average pooling captures only the first-order correlations between the scores; a higher-order pooling that captures higherorder correlations between the CNN features can be more appropriate, which is the main motivation for the scheme proposed in this paper.
Using higher-order action occurrences in a sequence may be able to capture such pre-cursors, leading to better discrimination of the action, while they may be ignored as noise when using a first-order pooling scheme.(有些信息在一阶的时候可能是噪声,但是在高阶的时候,可以捕获到信息)
《Covariance Pooling for Facial Expression Recognition》
参考博文《学习笔记之——covariance pooling》
《Deep Covariance Descriptors for Facial Expression Recognition》
https://blog.csdn.net/heruili/article/details/90611840
本文利用协方差矩阵对深度卷积神经网络(DCNN)特征进行编码,用于人脸表情识别。协方差矩阵的空间几何是对称正定矩阵的空间几何。通过在SPD流形上使用高斯核对人脸表情进行分类,证明了基于DCNN特征计算的协方差描述符比基于完全连通层和softmax的标准分类更有效
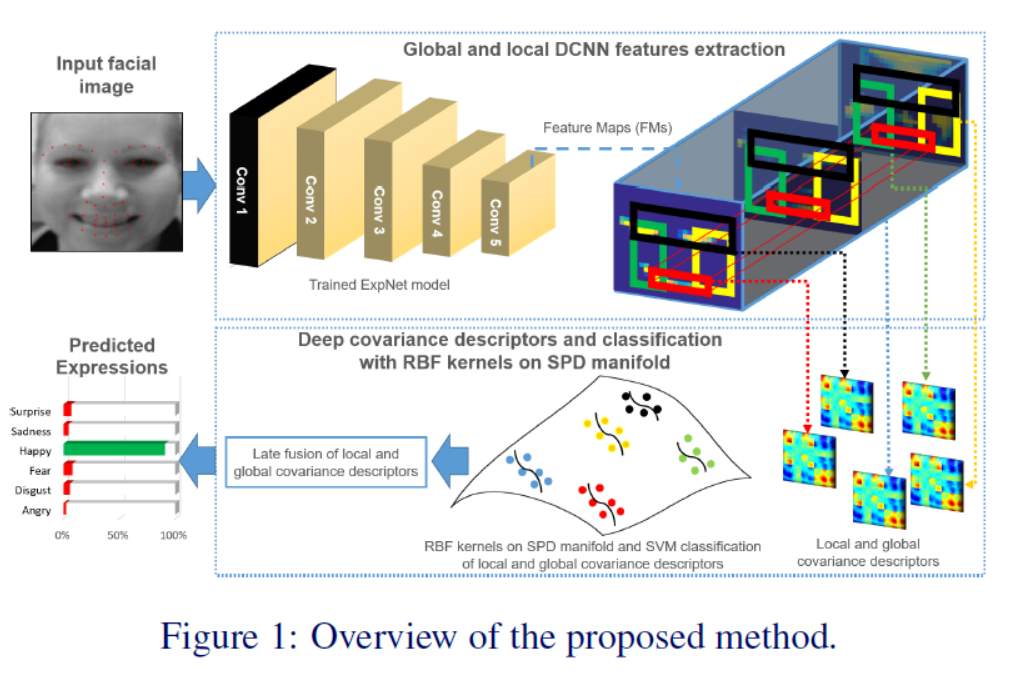
(SPD流型网络)
《Second-order Convolutional Neural Networks》
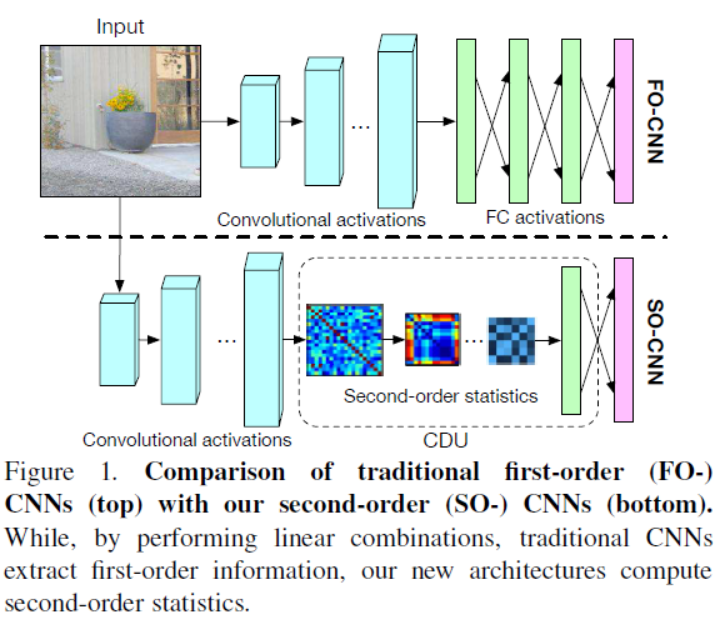
Convolutional Neural Networks (CNNs) have been successfully applied to many computer vision tasks, such as image classification. By performing linear combinations and element-wise nonlinear operations, these networks can be thought of as extracting solely first-order information from an input image.
In the past, however, second-order statistics computed from handcrafted features, e.g., covariances, have proven highly effective in diverse recognition tasks.
To this end, we design a series of new layers that (i) extract a covariance matrix from convolutional activations, (ii) compute a parametric, second-order transformation of a matrix, and (iii) perform a parametric vectorization of a matrix. These operations can be assembled to form a Covariance Descriptor Unit (CDU), which replaces the fully-connected layers of standard CNNs.
However, Region Covariance Descriptors have been mostly confined to exploiting handcrafted features, and have thus been unable to match the performance of deep networks.
In this paper, we introduce a new class of CNN architectures that exploit second-order statistics for visual recognition.
To this end, we develop three new types of layers.
The first one extracts a covariancematrix fromconvolutional activations.
The second one computes a parametric second order transformation of an input matrix, such as a covariancematrix.
Finally, the last one performs a parametric vectorization of an input matrix.
Convolutional Neural Networks (CNNs) have been successfully applied to many computer vision tasks, such as image classification. By performing linear combinations and element-wise nonlinear operations, these networks can be thought of as extracting solely first-order information from an input image. In the past, however, second-order statistics computed from handcrafted features, e.g., covariances, have proven highly effective in diverse recognition tasks.
By computing such linear combinations, even when followed by element-wise nonlinearities and pooling, traditional CNNs can be thought of as extracting only first-order statistics from the input images. In other words, such networks cannot extract second-order statistics, such as covariances. However, second-order statistics play an important role in the human visual recognition process [18]. In fact, these descriptors have been shown to typically outperform first-order features for visual recognition tasks such as material recognition and people re-identification. However, Region Covariance Descriptors have been mostly confined to exploiting handcrafted features, and have thus been unable to match the performance of deep networks.
In this paper, we introduce a new class of CNN architectures that exploit second-order statistics for visual recognition.
To this end, we develop three new types of layers.
The first one extracts a covariance matrix from convolutional activations (从卷积输出中提取协方差矩阵).
The second one computes a parametric second order transformation of an input matrix(计算输入矩阵的的参数二阶变换), such as a covariance matrix.
Finally, the last one performs a parametric vectorization of an input matrix(对输入矩阵执行参数化矢量化).
These different types of layers can be stacked into a Covariance Descriptor Unit (CDU)
an SO-CNN consists of a series of convolutions, followed by new second-order layers of different types, ending in a mapping to vector space, which then lets us predict a class label probability via a fully-connected layer and a softmax. 关键部分在CDU模块,所以论文也只着重讨论CDU模块。
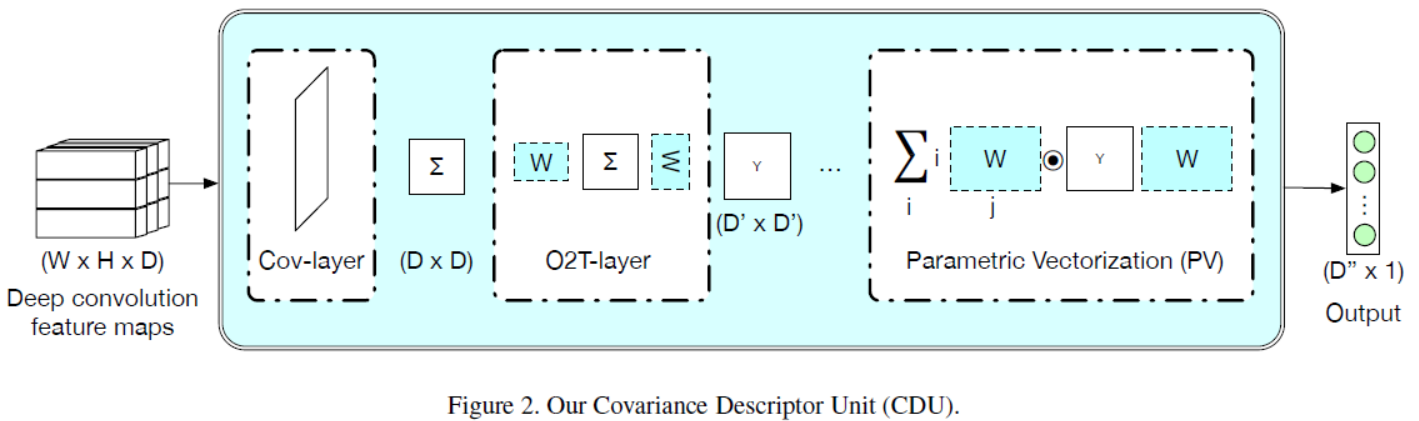
如下图所示。we introduce three such new layer types:
1、Cov layers, which compute a covariance matrix from convolutional activations;
2、O2T layers, which compute a parametric second-order transformation of an input matrix;
3、and PV layers, which perform a parametric mapping to vector space of an input matrix.(最终这个layer的输出是用于分类任务的)
Below, we discuss these different layer types in more detail.
Cov layers
a Cov layer computes a covariance matrix. In particular, this type of layers typically follows a convolutional layer, and thus acts on convolutional activations (在卷积层输出的特征上处理).

![]() 就是编码二阶统计信息。it completely discards the first-order ones, which may nonetheless bring valuable information(它完全抛弃了一阶的,尽管如此,这可能会带来有价值的信息).
就是编码二阶统计信息。it completely discards the first-order ones, which may nonetheless bring valuable information(它完全抛弃了一阶的,尽管如此,这可能会带来有价值的信息).
对于high-level问题,这样的特征确实可能可以带来对feature的进一步抽象,但是对于low-level问题,可能这样的特征会导致一阶特征的丢失。意思就是,确实不可以否认高阶特征带来更好的性能,但是一阶特征也是可以拥有好的信息,所以是否可以通过类似于fishnet的思路,保留多阶特征,并进行不同阶特征之间的refine,然后进行多阶特征的融合?
To keep the first order information, we propose to define the output of our Cov layer as
O2T layers
The Cov layer described above is non-parametric(非参数). As a consequence, it may decrease the network capacity compared to the traditional way of exploiting the convolutional activations by passing them through a parametric fully-connected layer, and thus yield a less expressive model despite its use of second-order information (尽管使用了二阶信息,但仍然会产生一个不那么具有表现力的模型). To overcome this, we introduce a parametric second-order transformation layer, which not only increases the model capacity via additional parameters, but also allows us to handle large convolutional feature maps

PV Layer.
Since our ultimate goal is classification, we eventually need to map our second-order, matrix-based representation to a vector form, which can in turn be mapped to a class probability estimate via a fully-connected layer with a softmax activation.
《UniformFace: Learning Deep Equidistributed Representation for Face Recognition》
propose a new supervision objective named uniform loss to learn deep equidistributed (深均匀分布的) representations for face recognition.
《Representation Similarity Analysis for Efficient Task taxonomy & Transfer Learning》
这篇论文讲Transfer learning的
uses Rep-resentation Similarity Analysis (RSA), which is commonly used to find a correlation between neuronal responses from brain data and models. With RSA we obtain a similarity score among tasks by computing correlations between models trained on different tasks.
《End-to-End Learning of Motion Representation for Video Understanding》
we propose TVNet, a novel end-to-end trainable neural network, to learn optical-flow-like features from data.
《Self-Supervised Representation Learning by Rotation Feature Decoupling》
Rotation Feature Decoupling(旋转特征解耦)
We introduce a self-supervised learning method that focuses on beneficial properties of representation and their abilities in generalizing to real-world tasks. The method incorporates(包括) rotation invariance (旋转不变性) into the feature learning framework, one of many good and well-studied properties of visual representation, which is rarely appreciated or exploited by previous deep convolutional neural network based self-supervised representation learning methods.
Specifically, our model learns a split representation (分割表示法) that contains both rotation (旋转) related and unrelated parts
《Semantic Video CNNs through Representation Warping》
Warping翘曲
The main design principle is to use optical flow of adjacent frames for warping internal network representations across time. A key insight of this work is that fast optical flow methods can be combined with many different CNN architectures for improved performance and end-to-end training.
《Geometry Guided Convolutional Neural Networks for Self-Supervised Video Representation Learning》
《Global Second-order Pooling Convolutional Networks》
In this paper, we propose a novel network model introducing GSoP across from lower to higher layers for exploiting holistic (全面的) image information throughout a network.
we perform GSoP to obtain a covariance matrix,
As the primary goal of the ConvNets is to characterize complex boundaries of thousands of classes in a high-dimensional space, it is critical to learn higher-order representations for enhancing non-linear modeling capability. Recently, Global Second-order Pooling (GSoP), plugged at the end of networks, has attracted increasing attentions, achieving much better performance than classical, first-order networks in a variety of vision tasks. However, how to effectively introduce higher-order representation in earlier layers for improving non-linear capability of Conv Nets is still an open problem.(就说高阶特征在网络的最后的时候的作用已经很明显了,但是高阶特征在网络前面层的作用却还没得到分析)
make full use of the second-order statistics of the holistic image throughout a network
Given color images as inputs, the ConvNets can learn progressively the low-level, mid-level and high-level features, finally producing global image representations connected to softmax layer for classification. To better characterize complex
boundaries of thousands of classes in a very high dimensional space, one possible solution is to learn higher order representations for enhancing nonlinear modeling capability of ConvNets.
Recently, modeling of higher-order statistics for more discriminative image representations has attracted great interests in deep ConvNets. The global second-order pooling(GSoP), producing covariance matrices as image representations, has achieved state-of-the-art results in a variety of vision tasks such as object recognition, fine grained visual categorization, object detection and video classification (应该这部分可以问院里的小伙伴怎么实现GSoP).
we introduce GSoP across from lower to higher layers of deep ConvNets, aiming to learn more discriminative representations by exploiting the second-order statistics of holistic image throughout a deep ConvNet.
Given a 3D tensor outputted by some previous convolutional layer, we first perform GSoP to model pairwise channel correlations of the holistic tensor(建立整体张量的成对通道相关模型。). We then accomplish embedding (嵌入) of the resulting covariance matrix by convolutions and non-linear activations, which is finally used for scaling the 3D tensor along channel dimension.
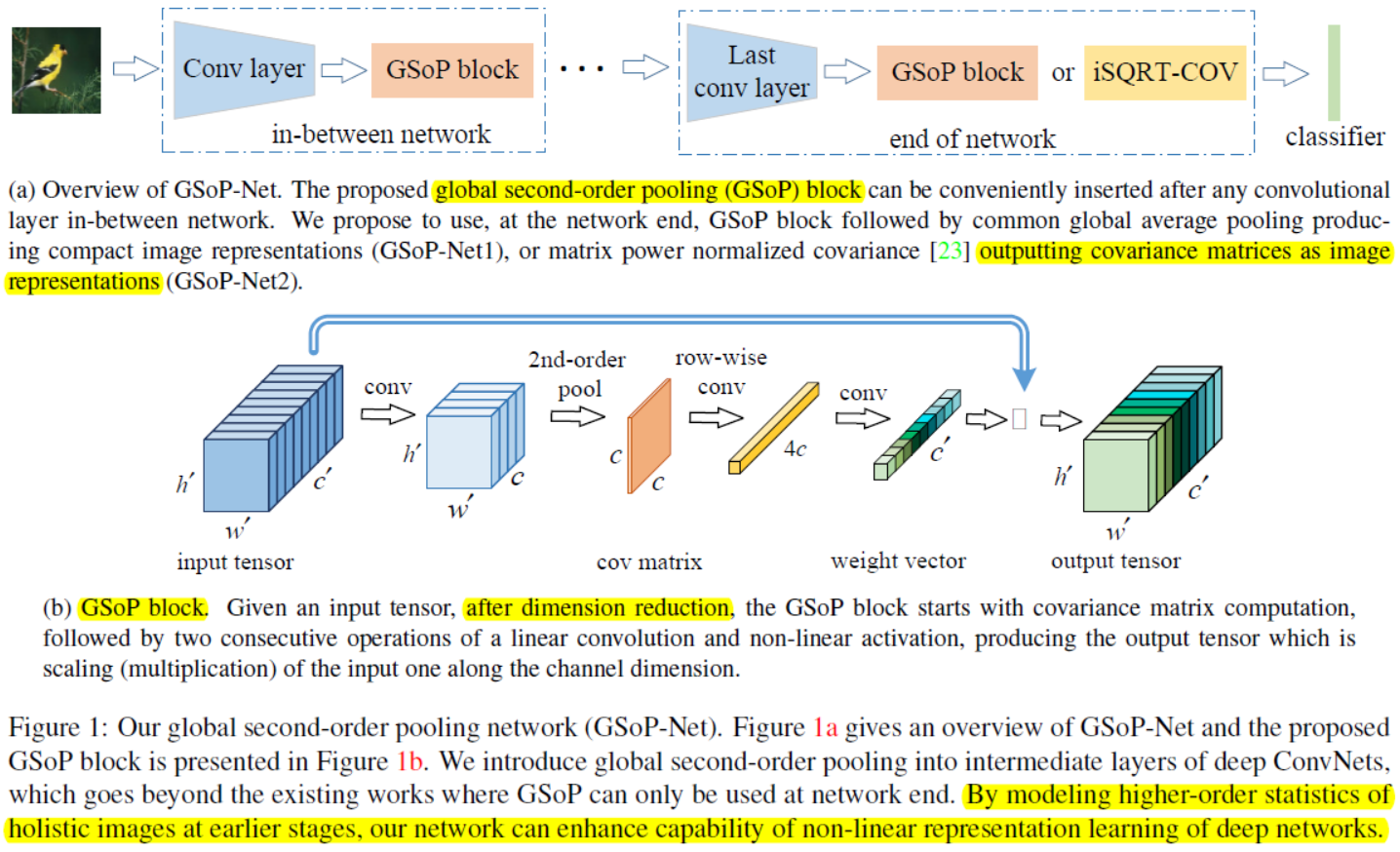
Contributions:
1、Distinct from the existing methods which can only exploit second-order statistics at network end, we are among the first who introduce this modeling into intermediate layers for making use of holistic (全面的) image information in earlier stages of deep ConvNets. By modeling the correlations of the holistic tensor (通过对整体张量的相关性建模), the proposed blocks can capture long range statistical dependency, making full use of the contextual information in the image.
2、We design a simple yet effective GSoP block, which is highly modular with low memory and computational complexity. The GSoP block, which is able to capture global second-order statistics along channel dimension or position dimension, can be conveniently plugged into existing network architectures, further improving their performance with small overhead.
Global average pooling plugged at the end of network, which summarizes the first-order statistics (i.e., mean vector) as image representations, has been widely used in most deep ConvNets such as ResNet, Inception and DenseNet. For the first time, SE-Net [15] introduced GAvP in-between network for making use of holistic image context at earlier stages, reporting significant improvement over its network-end counterparts. The SE-Net consists of two modules: a squeeze module accomplishing global average pooling followed by convolution and non-linear activations for capturing channel dependency, and an excitation module scaling channel for data recalibration (一种用于数据再校准的激励模块定标通道).
The global second order pooling, plugged at network end and trainable in an end-to-end manner, has received great interests, achieving significant performance improvement. In [5], the first-order information is combined with the second-order one which achieves consistent improvements over the standard bilinear networks on texture recognition.
In all the aforementioned works, second-order models are only exploited at the end of deep networks.
Quadratic Transformation Network(二次变换网络).
The conventional network depends heavily on linear convolution operations. Several researchers take a step further to explore higher order transformation for enhancing non-linear modeling capability of deep networks. The second-order Response Transform (SORT) [37] develops a two-branch network module to combine responses of two convolutional blocks and multiplication (乘法) of the responses. They perform elementwise square root for normalizing the second-order term. Zoumpourlis et al. [43] introduce Volterra kernel-based convolutions, which can model first-, second- or higher-order interactions of data, serving as approximations of non-linear functionals.
All the works above are concerned with non-linear filters, applied only to local neighborhood, just like linear convolution. In contrast, our GSoP networks collect the second order statistics of the holistic image for enhancing nonlinear capability of deep network.
By introducing this block in intermediate layers, we can model high-order statistics of the holistic image at early stages, having ability to enhance non-linear modeling capability of deep ConvNets.
With GSoP blocks in-between network and at the end of network, we can use GSoP block as well which is followed by the common global average pooling, producing the mean vector as compact image representation, which we call GSoPNet1. Alternatively, at the end of network, we can adopt matrix power normalized covariance matrices as image representations, called GSoP-Net2, which is more discriminative yet is high-dimensional.( 更具辨别力的是高维度的。)
The block consists of two modules, i.e., squeeze module and excitation module. The squeeze module aims to model the second order statistics along the channel dimension of the input tensor (挤压模块的目的是沿着输入张量的信道维数对二阶统计量进行建模)
The resulting covariance matrix has clear physical meaning, i.e., its ith row indicates statistical dependency of channel i with all channels.(第i行表示信道I与所有信道的统计依赖性。)
As the quadratic operations (二次运算) involved change the order of data, we perform row-wise normalization (行标准化) for the covariance matrix, respecting the inherent structural information(尊重固有的结构信息)
In the excitation module, prior to channel scaling, we perform two consecutive operations (连续两次操作) of convolution plus non-linear activation for covariance matrix embedding(在激励模块中,在信道缩放之前,我们对协方差矩阵嵌入进行了卷积加非线性激活的两个连续操作。)
To maintain the structural information, we perform row-wise convolution for the covariance matrix by regarding each row as a group in group convolution. Then we perform the second convolution and this time we use the sigmoid function as a nonlinear activation, outputting a c×1 weight vector. We finally multiply each channel of input tensor by the corresponding element in the weight vector. Individual channels are thus emphasized or suppressed in a soft manner in terms of the weights
channel-wise GSoP. global second-order pooling along channel dimension(沿着channel维度的二阶全局池化), extend it to spatial position, called position-wise GSoP, capturing pairwise feature correlations of the holistic tensor (整体张量) for position-wise feature scaling.
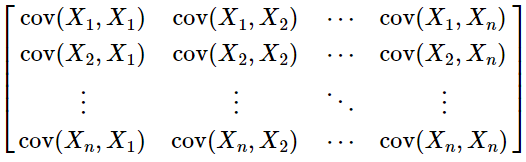
In classical deep ConvNets, restricted by limited receptive field size, the convolution operations can only process a local neighborhood of 3D tensor.如下图所示The data at distant position cannot interact。
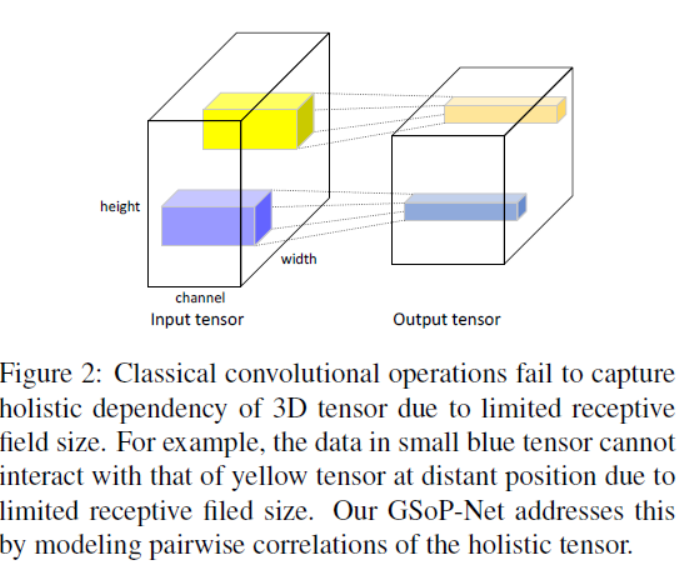
The long-range dependencies can only be captured by larger receptive fields produced by deep stacking of convolutional operations. This leads to several downsides such as optimization difficulty and modeling difficulty of multi-hop dependency。(这导致了多跳依赖的优化困难和建模困难等缺点。)
By computing all pairwise feature correlations (or inner product), the non-local operation can capture dependency of features at distant positions.(通过计算所有的成对特征相关性(或内积),非局部操作可以捕获远处特征的依赖性。)As a result, the non-local operation can excite significant features, which is consistent with self-attention machinery(能够激发显著的特征,这与自我关注机制是一致的。)Our position-wise GSoP multiplies each feature with one weight, which encodes nonlinear correlations of this feature with features at all positions. (我们的定位GSOP将每个特征乘以一个权重,该权重编码该特征与所有位置特征的非线性相关性。)As such, our position-wise GSoP can also model long-range dependency of features, functioning as a kind of spatial self-attention.
《Squeeze-and-Excitation Networks》
Squeeze-and-Excitation Networks(SENet)是由自动驾驶公司Momenta在2017年公布的一种全新的图像识别结构,它通过对特征通道间的相关性进行建模,把重要的特征进行强化来提升准确率。
已经有很多工作在空间维度上来提升网络的性能。那么很自然想到,网络是否可以从其他层面来考虑去提升性能,比如考虑特征通道之间的关系?我们的工作就是基于这一点并提出了 Squeeze-and-Excitation Networks(简称 SENet)。在我们提出的结构中,Squeeze 和 Excitation 是两个非常关键的操作,所以我们以此来命名。我们的动机是希望显式地建模特征通道之间的相互依赖关系。另外,我们并不打算引入一个新的空间维度来进行特征通道间的融合,而是采用了一种全新的「特征重标定」策略。具体来说,就是通过学习的方式来自动获取到每个特征通道的重要程度,然后依照这个重要程度去提升有用的特征并抑制对当前任务用处不大的特征。
参考资料:
https://blog.csdn.net/yuzhijiedingzhe/article/details/78124752
https://www.cnblogs.com/bonelee/p/9030092.html
https://www.jianshu.com/p/59fdc448a33f
https://blog.csdn.net/u014380165/article/details/78006626
论文链接:https://arxiv.org/abs/1709.01507
代码地址:https://github.com/hujie-frank/SENet
PyTorch代码地址:https://github.com/miraclewkf/SENet-PyTorch
Sequeeze-and-Excitation(SE) block并不是一个完整的网络结构,而是一个子结构,可以嵌到其他分类或检测模型中。SENet的核心思想在于通过网络根据loss去学习特征权重,使得有效的feature map权重大,无效或效果小的feature map权重小的方式训练模型达到更好的结果。
Figure1表示一个SE block。主要包含Squeeze和Excitation两部分,接下来结合公式来讲解Figure1。
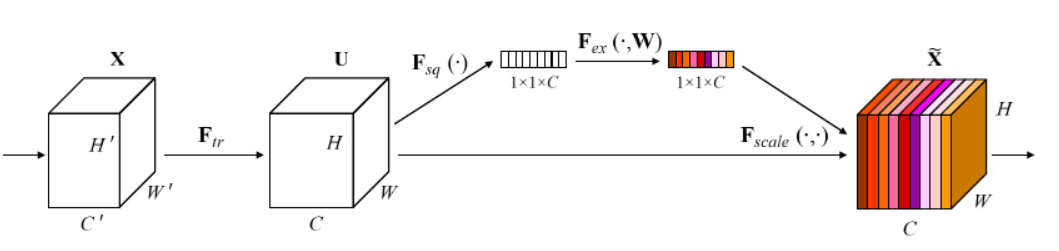
首先Ftr这一步是转换操作(严格讲并不属于SENet,而是属于原网络,可以看后面SENet和Inception及ResNet网络的结合),在文中就是一个标准的卷积操作而已,输入输出的定义如下表示。
![]()
那么这个Ftr的公式就是下面的公式1(卷积操作,vc表示第c个卷积核,xs表示第s个输入)
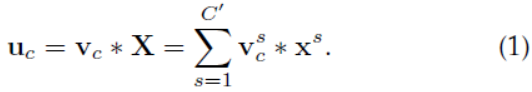
Ftr得到的U就是Figure1中的左边第二个三维矩阵,也叫tensor,或者叫C个大小为H*W的feature map。而uc表示U中第c个二维矩阵,下标c表示channel。
接下来就是Squeeze操作,公式非常简单,就是一个global average pooling:
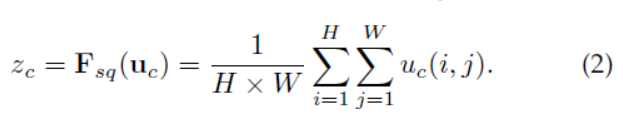
因此公式2就将HWC的输入转换成11C的输出,对应Figure1中的Fsq操作。为什么会有这一步呢?这一步的结果相当于表明该层C个feature map的数值分布情况,或者叫全局信息。
再接下来就是Excitation操作,如公式3。直接看最后一个等号,前面squeeze得到的结果是z,这里先用W1乘以z,就是一个全连接层操作,W1的维度是C/r * C,这个r是一个缩放参数,在文中取的是16,这个参数的目的是为了减少channel个数从而降低计算量。又因为z的维度是11C,所以W1z的结果就是11C/r;然后再经过一个ReLU层,输出的维度不变;然后再和W2相乘,和W2相乘也是一个全连接层的过程,W2的维度是C*C/r,因此输出的维度就是11C;最后再经过sigmoid函数,得到s。![]()
也就是说最后得到的这个s的维度是11C,C表示channel数目。这个s其实是本文的核心,它是用来刻画tensor U中C个feature map的权重。而且这个权重是通过前面这些全连接层和非线性层学习得到的,因此可以end-to-end训练。这两个全连接层的作用就是融合各通道的feature map信息,因为前面的squeeze都是在某个channel的feature map里面操作。
为什么要加全连接层呢?这是为了利用通道间的相关性来训练出真正的scale。一次mini-batch个样本的squeeze输出并不代表通道真实要调整的scale值,真实的scale要基于全部数据集来训练得出,而不是基于单个batch,所以后面要加个全连接层来进行训练。
在得到s之后,就可以对原来的tensor U操作了,就是下面的公式4。也很简单,就是channel-wise multiplication,什么意思呢?uc是一个二维矩阵,sc是一个数,也就是权重,因此相当于把uc矩阵中的每个值都乘以sc。对应Figure1中的Fscale。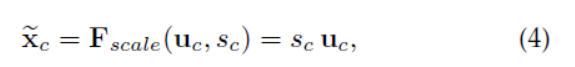
《SORT: Second-Order Response Transform for Visual Recognition》
In this paper, we reveal the importance and benefits of introducing second-order operations into deep neural networks.
propose a novel approach named Second-Order Response Transform (SORT), which appends element-wise product transform to the linear sum of a two-branch network module.
A direct advantage of SORT is to facilitate cross-branch response propagation, so that each branch can update its weights based on the current status of the other branch.
SORT augments (增加了) the family of transform operations and increases the nonlinearity of the network, making it possible to learn flexible functions to fit the complicated distribution of feature space.
The core idea of SORT is to append a dyadic second-order operation, say elementwise product, to the original linear sum of two-branch vectors.
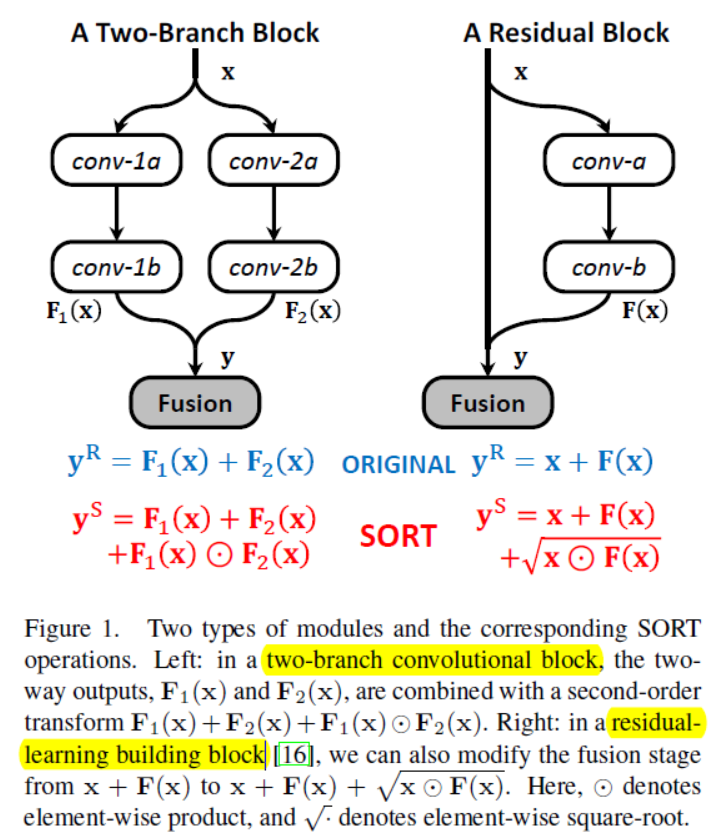
two-fold benefits. First, SORT facilitates cross-branch information propagation, which rewards consistent responses in forward-propagation, and enables each branch to update its weights based on the current status of the other branch in back-propagation. Second, the nonlinearity of the module becomes stronger, which allows the network to fit more complicated feature distribution.
这个是一个非常简单的思路
《FASON: First and Second Order Information Fusion Network for Texture Recognition》
Recently, deep convolutional neural networks (CNNs) have been used to learn discriminative texture representations. One of the most successful approaches is Bilinear CNN model [30,31] (They model the second order statistics of convolutional features within a deep network with a bilinear pooling layer that enables end-to-end training and achieved state-of-the-art performance on benchmark datasets.) that explicitly captures the second order statistics within deep features. However, these networks cut off the first order information flow in the deep network and make gradient back-propagation difficult. The first order information is also known to be essential for back-propagation based training. Hence, previous deep bilinear models neglect the potential of first order statistics in convolutional features and make training difficult.
combines second order information flow and first order information flow.
We first extend the bilinear network to combine first order information into the learning process by designing a leaking shortcut which enables the first order statistics to pass through and combine with bilinear features.
Contributions
1、We design a deep fusion architecture that effectively combines second order information (calculated from a bilinear model) and first order information (preserved through our leaking shortcut) in an end-to-end deep network.
2、We extend our fusion architecture to take advantage of the multiple features from different convolution layers.
The diagonal entries of the output bilinear matrix represent the variances within each feature channel, while the off-diagonal entries represent the correlations between different feature channels.
First and second order fusion with multiple levels of convolutional features
Now we introduce our core building block of the first order and second order information fusion. Although bilinear models exploit second order information from deep features well, they often suffer from the problem of vanishing gradients (消失梯度) when gradient flow back-propagates through them, which makes it difficult to learn such models in an end-to-end training process. Therefore, recent work usually places the bilinear layer after the last convolutional layer to minimize this problem.
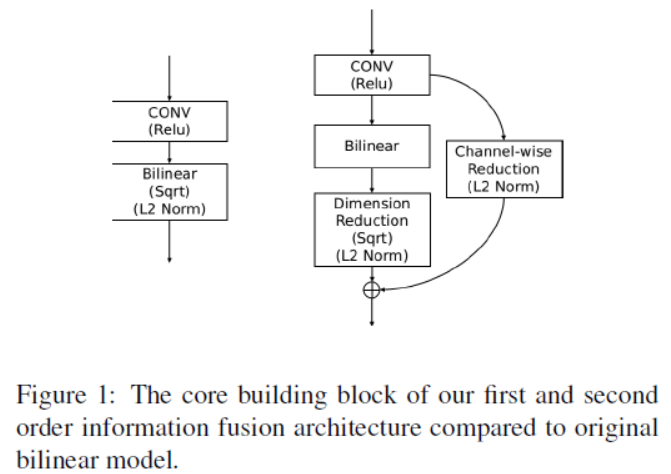
we design a shortcut connection that passes through the first order information and combines with the second order information generated from the bilinear layer, as shown in Figure 1. Assuming we generate the deep feature F from the previous convolutional layer, instead of using the bilinear feature B(F) directly, we combine it with a leaking function M(F) that encodes first order information.
多个特征的融合
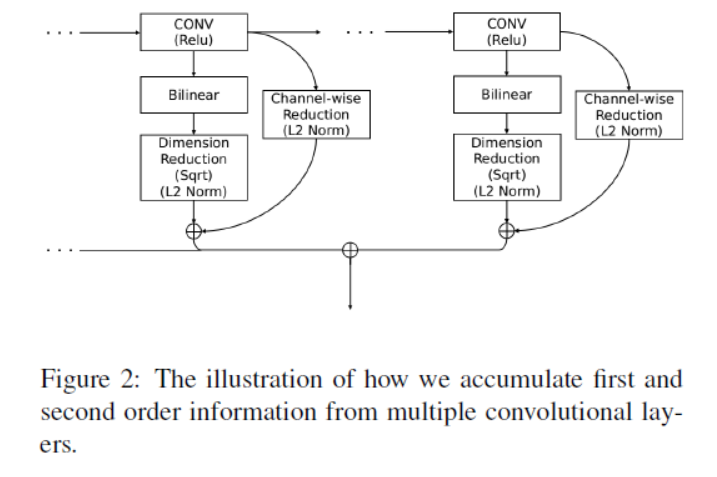
《Higher-Order Occurrence Pooling for Bags-of-Words: Visual Concept Detection》
This paper investigates higher-order pooling that aggregates over co-occurrences of visual words(视觉词的共现)We derive Bag-of-Words with Higher-order Occurrence Pooling based on linearisation of Minor Polynomial Kernel and extend this model to work with various pooling operators. This approach is then effectively used for fusion of various descriptor types. Moreover, we introduce Higher order Occurrence Pooling performed directly on local image descriptors as well as a novel pooling operator that reduces the correlation in the image signatures.
Contributions
1、We propose Higher-order Occurrence Pooling that aggregates (合计) co-occurrences (共同事件) rather than occurrences of visual words in mid-level features, which leads to more discriminative representation.
《End-to-End Efficient Representation Learning via Cascading Combinatorial Optimization》
(级联组合优化)
《CNN Driven Sparse Multi-Level B-spline Image Registration》
Traditional single-grid (单网格) and pyramidal B-spline parameterizations (金字塔B样条参数化) used in deformable (可变形的) image registration (注册) require users to specify control point spacing configurations capable of accurately capturing both global and complex local deformations(变形).
《A Novel Space-Time Representation on the Positive Semidefinite Cone for Facial Expression Recognition》
In this paper, we study the problem of facial expression recognition using a novel space-time geometric representation(时空几何表示).
We describe the temporal evolution (时间演化) of facial landmarks as parametrized trajectories(参数化轨道) on the Riemannian manifold of positive semidefinite matrices of fixed-rank(固定秩的半定矩阵).
《Learning Deep Descriptors with Scale-Aware Triplet Networks》
Research on learning suitable feature descriptors for Computer Vision has recently shifted (转移) to deep learning where the biggest challenge lies with the formulation of appropriate loss functions, especially since the descriptors to be learned are not known at training time. While approaches such as Siamese and triplet losses have been applied with success, it is still not well understood what makes a good loss function. In this spirit, this work demonstrates that many commonly used losses suffer from a range of problems. Based on this analysis, we introduce mixed-context losses and scale-aware sampling, two methods that when combined enable networks to learn consistently scaled descriptors for the first time.
《Higher-Order Minimum Cost Lifted Multicuts for Motion Segmentation》
最低成本提升多功能
In fact, the Euclidean difference between two local motion descriptors such as optical flow vectors or point trajectories(轨道), measures how well the behavior of the two entities can be described by a single translational motion model.
for any three points, one can estimate how well their motion can be described by one Euclidean transformation.(貌似这篇论文更加适合于做video的)
Edges that describe such motion differences are thus at least of order three. Affine motion differences can be described with edges of order four and to assign costs to differences in homographies, the minimum required edge-order is five.
《Diversify and Match: A Domain Adaptive Representation Learning Paradigm for Object Detection》
a novel unsupervised domain adaptation approach (域适应方法) for object detection. Alleviate (缓解) the imperfect translation problem of pixel-level adaptations。
Our approach is composed of two stages, i.e., Domain Diversification (DD,领域多元化) and Multi- domain-invariant Representation Learning (MRL,多域不变表示学习). At the DD stage, we diversify the distribution of the labeled data by generating various distinctive shifted (独特的转变) domains from the source domain. At the MRL stage, we apply adversarial learning with a multi-domain discriminator to encourage feature to be indistinguishable among the domains.
《High-order Tensor Regularization with Application to Attribute Ranking》
属性排序
When learning functions on manifolds (流形), we can improve performance by regularizing with respect to the intrinsic manifold geometry (固有的流形几何) rather than the ambient space (环境空间).
Regularizing this instead allows us to learn non-symmetric and high-order tensors(把它正规化可以让我们学习非对称张量和高阶张量。)
Learning tensors from data has many applications in function learning. Regression, classification, and clustering pose the function as a zeroth-order tensor; vector field learning poses the vector as a first-order tensor; and metric or covariance learning pose the metric as a symmetric second-order tensor. The generalization performance of the learned tensor h depends crucially on how it is regularized (所学习到的tensor的泛化能力由它如何正则化决定的)—how the spatial smoothness (空间平滑度) of h is enforced(强制执行). In many problems, data lie on low-dimensional manifolds (在大部分问题中,数据都是处于低维度的流行中)for which it helps to regularize h with respect to the intrinsic geometry (内在几何学) of the data generating manifold M:to enforce smoothness along M rather than in the ambient(周围的) (Euclidean) space on which M is embedded(嵌入的).
《T-Net: Parametrizing Fully Convolutional Nets with a Single High-Order Tensor》
In this paper, we propose to fully parametrize Convolutional Neural Networks (CNNs) with a single high order, low-rank tensor. We propose to jointly capture the full structure of a neural network by parametrizing it with a single high-order tensor, the modes of which represent each of the architectural design parameters of the network (e.g. number of convolutional blocks, depth, number of stacks, input features, etc). This parametrization allows to regularize the whole network and drastically reduce the number of parameters
For a wide range of challenging tasks, including recognition, detection, semantic segmentation and human pose estimation, the state-of-the-art is currently attained with Convolutional Neural Networks (CNNs). There is evidence that a key feature behind the success of these methods is over-parametrization (过参数化), which helps find good local minima (极小值). However, at the same time, over-parametrization leads to a great amount of redundancy (冗余), and from a statistical perspective(统计视角), it might hinder generalization (妨碍泛化) because it excessively increases the number of parameters. Furthermore, models with an excessive number of parameters have increased storage and computation requirements, rendering them problematic for deployment on devices with limited computational resources.
There is a significant amount of recent work on using tensors to reduce the redundancy and improve the efficiency of CNNs, mostly focusing on re-parametrizing individual layers.
we propose to parametrize the network with a single high-order tensor, each dimension of which represents a different architectural design parameter of the network. For the case of Fully Convolutional Networks (FCNs) with an encoder-decoder structure considered herein (see also Fig. 1), each dimension of the 8−dimensional tensor represents a different architectural design parameter of the network such as the number of (stacked) FCNs used, the depth of each network, the number of input and output features for each convolutional block and the spatial dimensions of each of the convolutional kernels. By modelling the whole FCN with a single tensor, our approach allows for learning correlations between the different tensor dimensions and hence to fully capture the structure of the network.
《Performance Guaranteed Network Acceleration via High-Order Residual Quantization》
通过高阶剩余量化实现性能保证的网络加速
Input binarization (二值化) has shown to be an effective way for network acceleration. However, previous binarization scheme could be regarded as simple pixel-wise thresholding operations (i.e., order-one approximation) and suffers a big accuracy loss. In this paper, we propose a high order binarization scheme, which achieves more accurate approximation while still possesses the advantage of binary operation.
Methods to accelerate learning and evaluation of deep network could be roughly divided into three groups. The simplest method is to perform network pruning (网络修剪) (i.e., by rounding off near-zero connections) and re-train the pruned network structure. To achieve more structural compression rate, structural sparsity approximation techniques are later developed to morph (变形) larger sub-Networks into shallow ones
(这篇工作应该是做网络加速、网络压缩这块的)
《Defense against Adversarial Attacks Using High-Level Representation Guided Denoiser》
防御对抗性攻击
Neural networks are vulnerable to adversarial examples, which poses a threat to their application in security sensitive systems. We propose high-level representation guided denoiser (HGD) as a defense for image classification.
We propose high-level representation guided denoiser (HGD) as a defense for image classification. Standard denoiser suffers from the error amplification effect (误差放大效应), in which small residual adversarial noise is progressively amplified (逐渐放大) and leads to wrong classifications.
《A Simple Pooling-Based Design for Real-Time Salient Object Detection》
because of the pyramid-like structural characteristics of CNNs, shallower stages usually have larger spatial sizes and keep rich, detailed low-level information while deeper stages contain more high-level semantic knowledge and are better at locating the exact places of salient objects.
construct enriched feature maps
Despite the good performance achieved by this type of approaches, there is still a large room for improving it.
First, in the U-shape structure, high-level semantic information is progressively transmitted to shallower layers, and hence the location information captured by deeper layers may be gradually diluted (逐渐被稀释) at the same time.
Second, the receptive field size of a CNN is not proportional to its layer depth (与其层深度不成比例). Existing methods solve the above mentioned problems by introducing attention mechanisms into U-shape structures, refining feature maps in a recurrent way, combining multi-scale feature information, or add extra constraints to saliency maps (显着性图) like the boundary loss term.
In this paper, different from the methods mentioned above, we investigate how to solve these problems by expanding the role of the pooling techniques in U-shape based architectures. In general, our model consists of two primary modules on the base of the feature pyramid networks (FPNs): a global guidance module (GGM, 全球指导模块) and a feature aggregation module (FAM, 特征聚合模块).
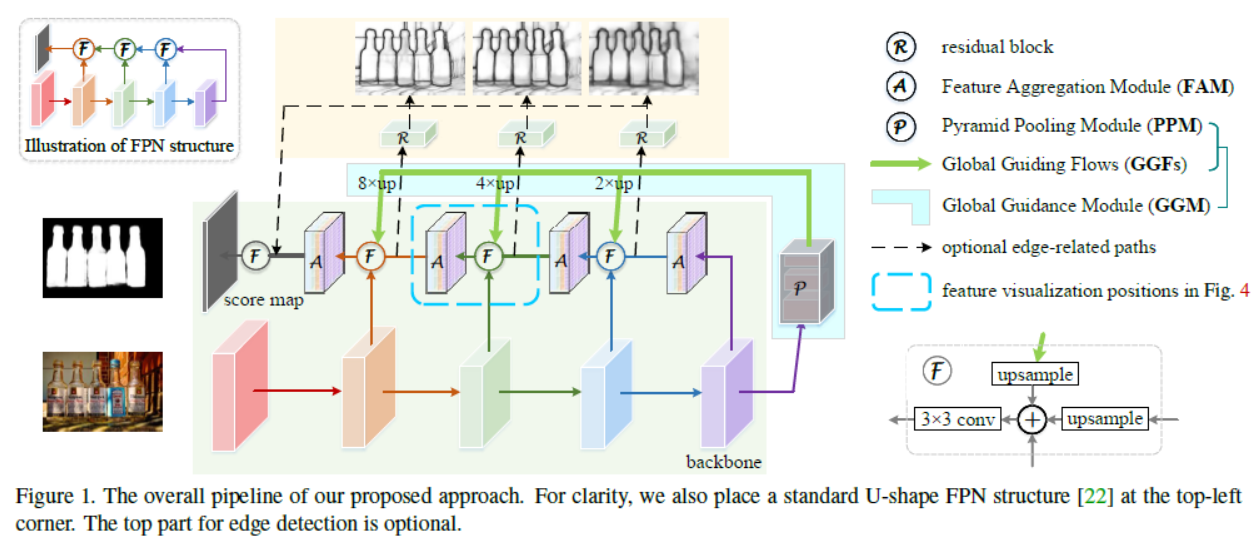
design various pooling-based modules to assist (辅助) in improving the performance for salient object detection.
high-level semantic (语义) features are helpful for discovering the specific locations of salient objects. At the meantime, low- and midlevel features are also essential for improving the features extracted from deep layers from coarse level to fine level (粗级到精细级别).
introduce a global guidance module (GGM) which is built upon the top of the bottom-up pathway(自下而上的途径。). By aggregating (聚集) the high-level information extracted by GGM with into feature maps at each feature level, our goal is to explicitly notice (明确注意) the layers at different feature levels where salient objects are. After the guidance information from GGM is merged with the features at different levels, we further introduce a feature aggregation module (FAM) to ensure that feature maps at different scales can be merged seamlessly (无缝合并)
Global Guidance Module
FPNs provide a classic architecture for combining multilevel features from the classification backbone. However, because the top-down pathway is built upon the bottom-up backbone, one of the problems to this type of U-shape architectures is that the high-level features will be gradually diluted (逐渐被稀释) when they are transmitted to lower layers. the empirical receptive fields of CNNs are much smaller than the ones in theory especially for deeper layers, so the receptive fields of the whole networks are not large enough to capture the global information of the input images. The immediate effect on this is that only parts of the salient objects can be discovered (如下图所示)

Regarding the lack of high-level semantic information for fine-level feature maps in the top-down pathway, we introduce a global guidance module which contains a modified version of pyramid pooling module (PPM) and a series of global guiding flows (GGFs) to explicitly make feature maps at each level be aware of the locations of the salient objects.
the PPM in our GGM consists of four sub-branches to capture the context information of the input images. The first and last sub-branches are respectively an identity mapping layer and a global average pooling layer. For the two middle sub-branches, we adopt the adaptive average pooling layer1 to ensure the output feature
maps of them are with spatial sizes 3×3 and 5×5, respectively. Given the PPM, what we need to do now is how to guarantee that the guidance information produced by PPM can be reasonably fused with the feature maps at different levels in the top-down pathway.
Feature Aggregation Module
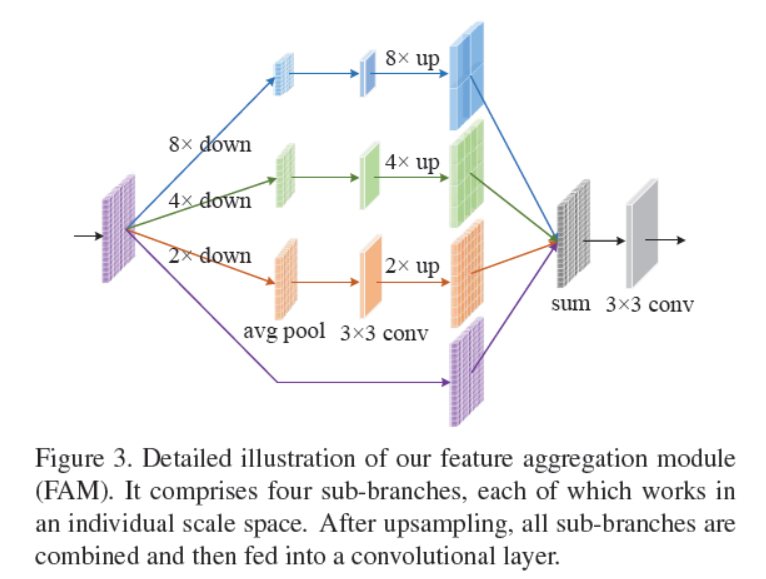
《Local Log-Euclidean Multivariate Gaussian Descriptor and Its Application to Image Classification》
《Attend and Interact: Higher-Order Object Interactions for Video Understanding》
we propose to efficiently learn higher-order interactions (互动) between arbitrary subgroups of objects for fine-grained video understanding.
Fine-grained higher-order object interactions (细粒度的高阶对象交互)
Traditional pairwise object interactions only consider how each object interacts with another object. We instead model inter-relationships between arbitrary (随意) subgroups of objects, the members of which are determined by a learned attention mechanism, as illustrated in Figure 2.
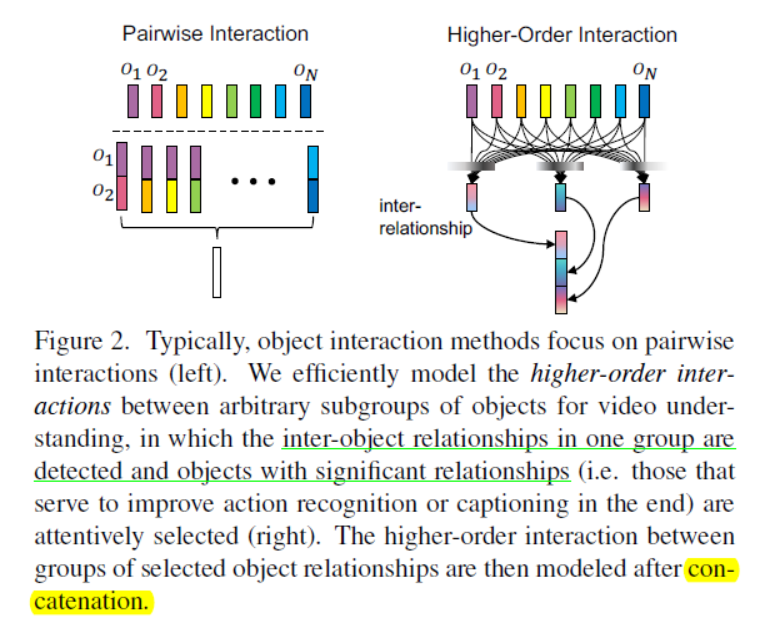
Each object representation can be directly obtained from an RPN and further encoded into an object feature.
Recurrent Higher-Order Interaction (HOI)
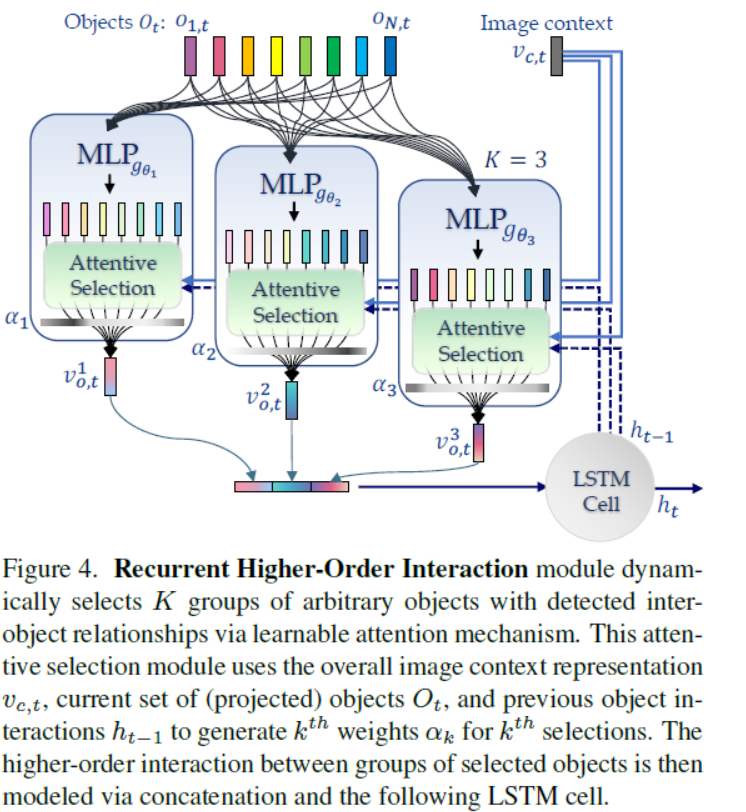
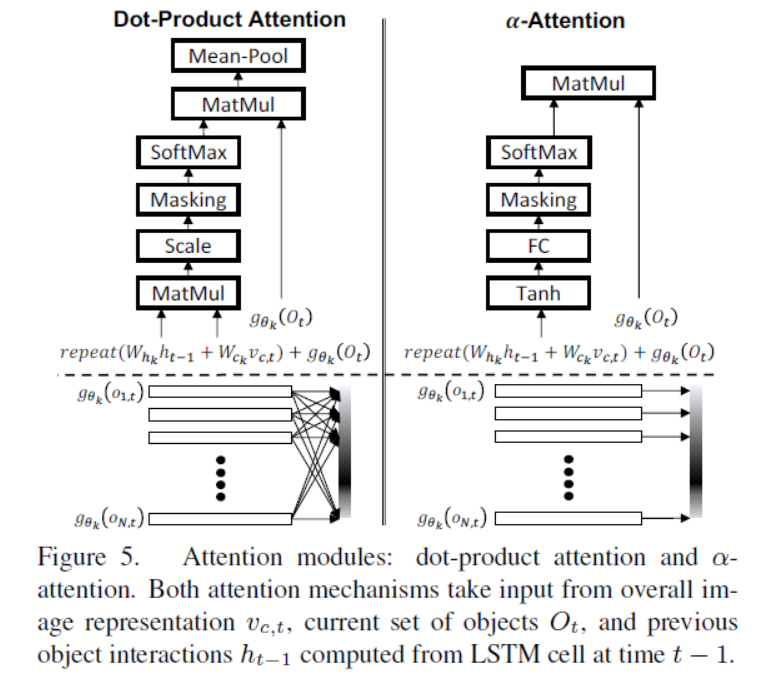
Dot-product attention: In order to model higher order interactions, which models inter-object relationships in each group of selected objects, we use dot-product attention since the attention weights computed for each object is the combination of all objects. (SENet的结构)


《Representation Flow for Action Recognition》
又一篇跟光流有关的论文
《Learning Spatio-Temporal Representation with Local and Global Diffusion》
Convolutional Neural Networks (CNN) have been regarded as a powerful class of models for visual recognition problems. Nevertheless, the convolutional filters in these networks are local operations while ignoring the large-range dependency. Such drawback becomes even worse particularly for video recognition, since video is an information-intensive media with complex temporal variations. In this paper, we present a novel framework to boost the spatio-temporal representation learning by Local and Global Diffusion (LGD,扩散). Specifically, we construct a novel neural network architecture that learns the local and global representations in parallel. The architecture is composed of LGD blocks, where each block updates local and global features by modeling the diffusions between these two representations. Diffusions effectively interact two aspects of information, i.e., localized and holistic, for more powerful way of representation learning. Furthermore, a kernelized classifier (核化分类器,这里融合的方式可以参考之前看过的paper) is introduced to combine the representations from two aspects for video recognition.
Each convolution operation, either 2D or 3D, processes only a local window of neighboring pixels. As window size is normally set to a small value, the holistic view of field cannot be adequately captured. This problem is engineered by performing repeated convolution and pooling operations to capture long-range visual dependencies. In this way, receptive fields can be increased through progressive propagation (渐进传播) of signal responses over local operations.
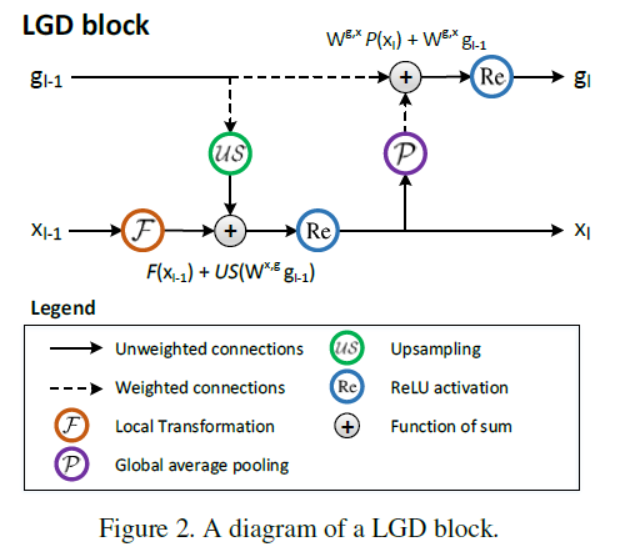
Local and Global Diffusion (LGD) networks – a novel architecture to learn spatio-temporal representations capturing large-range dependencies, as shown in Figure 1.
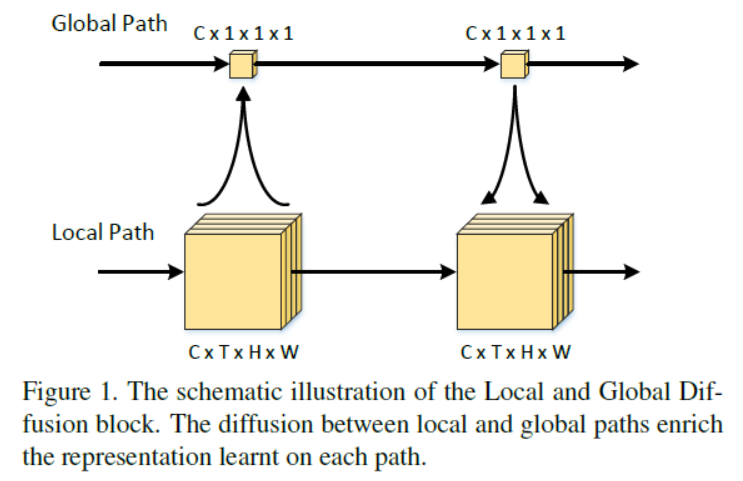
In LGD networks, the feature maps are divided into local and global paths, respectively describing local variation and holistic appearance at each spatio-temporal location. The networks are composed ofseveral staked LGD blocks of each couples with mutually inferring local and global paths. Specifically, the inference takes place by attaching the residual value of global path to the output of local feature map (将全局路径的残差值附加到局部特征映射的输出), while the feature of global path is produced by linear embedding of itself with the global average pooling of local feature map (线性嵌入自身与本地特征图的全局平均汇集).
Furthermore, the final representations from both paths are combined by a novel kernel-based classifier
Local and Global Diffusion Blocks
we propose the novel neural networks that learn the discriminative local representation and global representation in parallel while combining them to synthesize new information. To achieve this, the feature maps in neural networks are splitted into local path and global path. Then, we define a LGD block to model the interaction between two paths as:


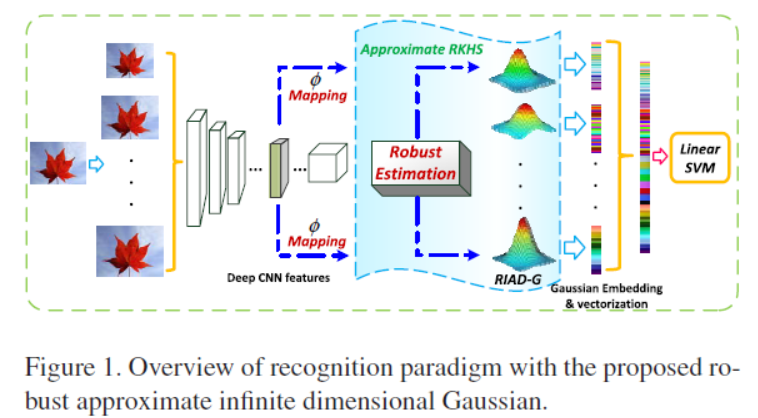
《RAID-G: Robust Estimation of Approximate Infinite Dimensional Gaussian with Application to Material Recognition》
Infinite dimensional covariance descriptors can provide richer and more discriminative information than their low dimensional counterparts.
In this paper, we propose a novel image descriptor, namely, robust approximate infinite dimensional Gaussian (RAID-G, 鲁棒近似无限维高斯).
Recently, the covariance matrices as region image representations have attracted increasingly attentions in a number of computer vision tasks
However, covariance descriptors in the original low-dimensional feature space usually have limited capability in encoding richer and more discriminative information. Meanwhile, dramatic (巨大的) increase of feature dimension brings challenges on the robust estimation of covariance representations.
To address limitations of covariance descriptors in the original low-dimensional feature space, one of recent extensions to covariance representations is infinite (无限的) dimensional covariance descriptors, which usually are significantly superior to the ones constructed (构建) in the original feature space. The underlying (潜在的) idea of infinite dimensional covariance descriptors is to map, through some kernel functions, the original features into some Reproducing Kernel Hilbert Space (RKHS) ℋ in which one constructs (构造) covariance descriptors.
Alternative extension (替代扩展) to covariance representations is to enhance the original features
we construct infinite dimensional Gaussian descriptor by using the convolutional features as well, which are of high dimension (512 or 1536 in our case). As far as we know, previous works on covariance or Gaussian descriptors have never made such an attempt. The reason may be that, for an input image, usually only a very small number of deep CNN features are available, the dimensions (512 or higher) of which are inherently (内在的) much higher than those of the traditional ones, making robust estimation of covariances difficult.
we propose a regularized MLE to robustly estimate high dimensional covariance in the Gaussian setting. The key idea is to impose structural constraint in the original MLE through the von Neumann matrix divergence, which is intimately (密切) connected with exponential distributions (指数分布). Specifically, by encouraging the identity matrix structure in the covariance matrix, we obtain a robust and efficient estimator. This estimator, which we call vN-MLE, has a closed form expression and can significantly improve performance of approximate infinite dimensional Gaussians.
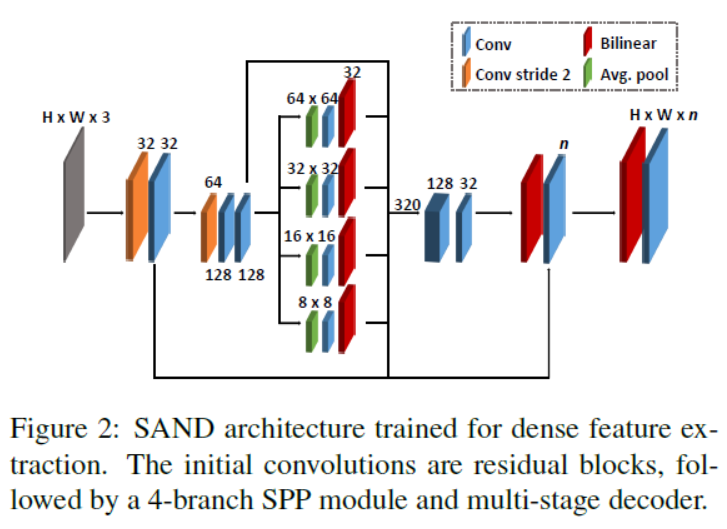
《Scale-Adaptive Neural Dense Features: Learning via Hierarchical Context Aggregation》
a methodology for generic feature learning from sparse image correspondences.
The aim of this work is to provide a high-dimensional feature descriptor for every pixel within an image, capable of describing the context at multiple scales. We achieve this by employing a pixel-wise contrastive loss in a Siamese network architecture. Each branch of the siamese network consists of a series of convolutional residual blocks followed by a Spatial Pooling Pyramid (SPP) module, shown in Figure 2.
The convolution block and base residual blocks serve as the initial feature learning. In order to increase the receptive field, the final two residual blocks employ an atrous convolution with dilations of two and four, respectively.
The SPP module is formed by four parallel branches, each with average pooling scales of 8, 16, 32 and 64, respectively. Each branch produces a 32D output with a resolution of (H/4,W/4). In order to produce the final dense feature map, the resulting block is upsampled in several stages incorporating skip connections and reducing it to the desired number of dimensions, n.

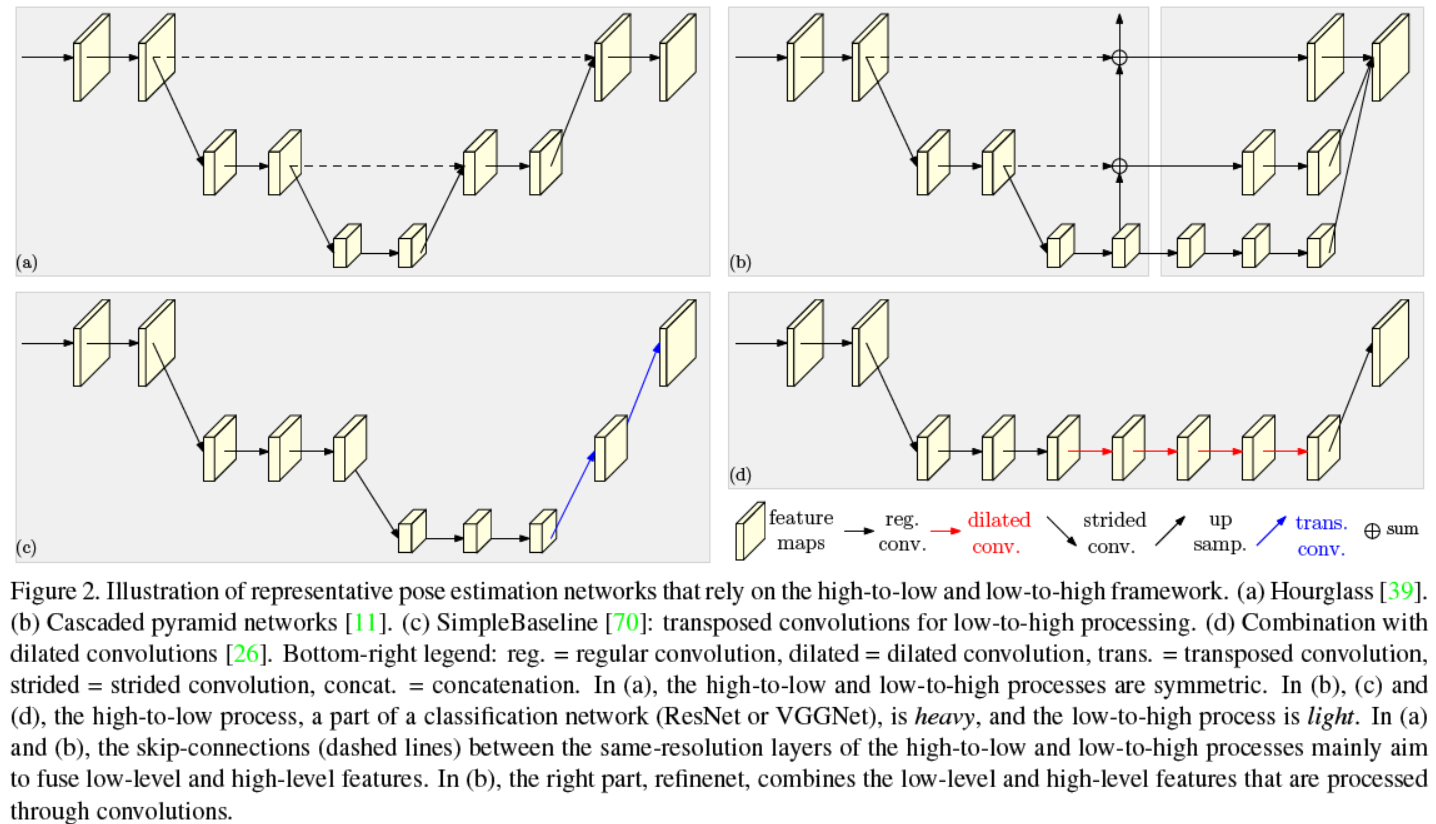
《Deep High-Resolution Representation Learning for Human Pose Estimation》
《Optical Flow Guided Feature: A Fast and Robust Motion Representation for Video Action Recognition》
又一篇光流法的
《Blob Reconstruction Using Unilateral Second Order Gaussian Kernels with Application to High-ISO Long-Exposure Image Denoising》
In this paper, we propose a blob reconstruction method (斑点重建方法) using scale-invariant normalized (尺度不变归一化) unilateral (单边的) second order Gaussian kernels. Unlike other blob detection methods, our method suppresses (抑制) non-blob structures while also identifying blob parameters, i.e., position, prominence (突出) and scale, thereby facilitating blob reconstruction.
《Self-supervised Spatio-temporal Representation Learning for Videos by Predicting Motion and Appearance Statistics》
video 超分的可看
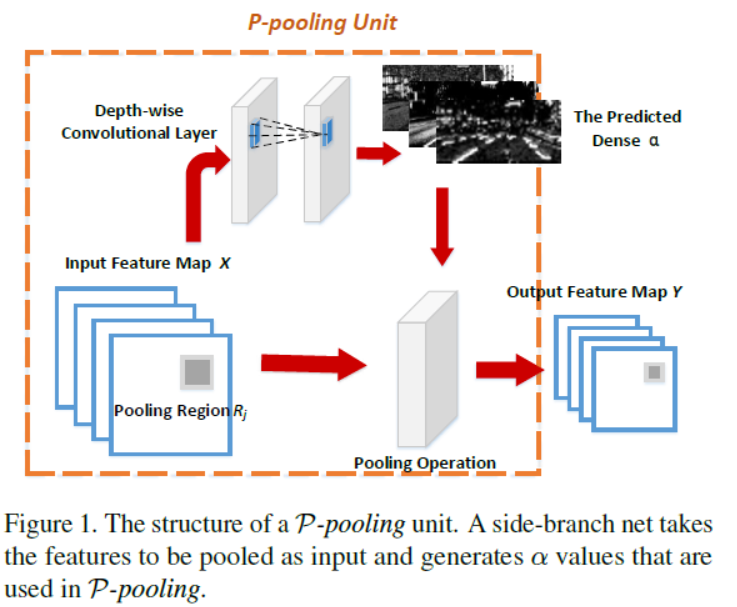
《Building Detail-Sensitive Semantic Segmentation Networks with Polynomial Pooling》
The most common standard poolings are max and average pooling. Max pooling can increase both the invariance to spatial perturbations and the non-linearity of the networks (空间扰动不变性与网络非线性). Average pooling, on the other hand, is sensitive to spatial perturbations, but is a linear function(对空间扰动敏感,但为线性函数。).
In this work, we propose a polynomial pooling (P-pooling) function that finds an intermediate form between max and average pooling to provide an optimally balanced and self-adjusted pooling strategy for semantic segmentation.
《Uncertainty Guided Multi-Scale Residual Learning-using a Cycle Spinning CNN for Single Image De-Raining》
de-raining,看着很有趣
应该也算low-level问题,同时采用了multi scale手段
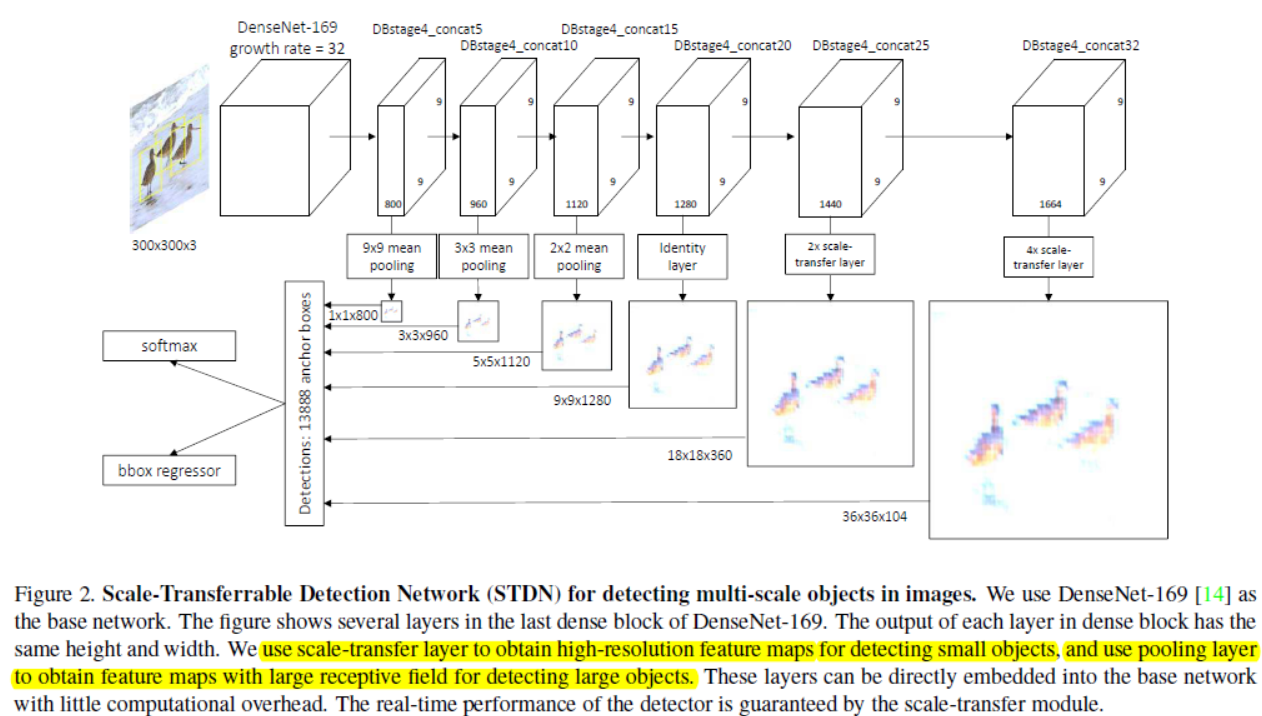
《Scale-Transferrable Object Detection》
the proposed network is equipped with embedded super-resolution layers
in order to improve detection performance, feature pyramids must be carefully constructed, and adding extra layers to build the feature pyramids brings additional computational cost.
In order to obtain high-level semantic multi-scale feature maps, and also without impairing the speed of the detector, we develop a Scale-Transfer Module (STM) and embed this module directly into a DenseNet. The role of DenseNet is to integrate low-level and high-level features within a CNN to get more powerful features. Because of the densely connected network structure, the features of DenseNet are naturally more powerful than the ordinary convolutional features. STM consists of pooling and scaletransfer layers. Pooling layer is used to obtain small scale feature maps, and scale-transfer layer is used to obtain large scale feature maps. Scale-transfer layer is first proposed to do image super-resolution because of its simplicity and
efficiency, and some people also use it to do semantic segmentation. We use this layer to efficiently expand the resolution of the feature map for object detection.
最后
以上就是超帅酒窝最近收集整理的关于paper survey(2019.06.11)——卷积网络高阶特征表示《G2DeNet: Global Gaussian Distribution Embedding Network and Its Application to Visual Recognition》《Is Second-order Information Helpful for Large-scale Visual Recognition?》《Second-order Attention Network for Single的全部内容,更多相关paper内容请搜索靠谱客的其他文章。








发表评论 取消回复