???? 作者:不吃西红柿
???? 简介:CSDN博客专家????、信息技术智库公号作者✌。简历模板、职场PPT模板、技术难题交流、面试套路尽管【关注】私聊我。
???? 欢迎点赞 ???? 收藏 ⭐留言 ???? 如有错误敬请指正!
热门专栏推荐:
???? 大数据集锦专栏:大数据-硬核学习资料 & 面试真题集锦
???? 数据仓库专栏:数仓发展史、建设方法论、实战经验、面试真题
???? Python专栏:Python相关黑科技:爬虫、算法、小工具
(优质好文持续更新中……)✍
目录
一、kudu介绍
二、基础概念
三、设计架构
四、数据存储结构
五、表设计
六、注意事项
一、kudu介绍
Kudu是Cloudera开源的新型列式存储系统,是Apache Hadoop生态圈的成员之一(incubating),专门为了对快速变化的数据进行快速的分析,填补了以往Hadoop存储层的空缺。
1 功能上的空白
Hadoop生态系统有很多组件,每一个组件有不同的功能。在现实场景中,用户往往需要同时部署很多Hadoop工具来解决同一个问题,这种架构称为混合架构 (hybrid architecture)。比如,用户需要利用Hbase的快速插入、快读random access的特性来导入数据,HBase也允许用户对数据进行修改,HBase对于大量小规模查询也非常迅速。同时,用户使用HDFS/Parquet + Impala/Hive来对超大的数据集进行查询分析,对于这类场景, Parquet这种列式存储文件格式具有极大的优势。
很多公司都成功地部署了HDFS/Parquet + HBase混合架构,然而这种架构较为复杂,而且在维护上也十分困难。首先,用户用Flume或Kafka等数据Ingest工具将数据导入HBase,用户可能在HBase上对数据做一些修改。然后每隔一段时间(每天或每周)将数据从Hbase中导入到Parquet文件,作为一个新的partition放在HDFS上,最后使用Impala等计算引擎进行查询,生成最终报表。
这样一条工具链繁琐而复杂,而且还存在很多问题,比如:
- 如何处理某一过程出现失败
- 从HBase将数据导出到文件,多久的频率比较合适
- 当生成最终报表时,最近的数据并无法体现在最终查询结果上
- 维护集群时,如何保证关键任务不失败
- Parquet是immutable,因此当HBase中删改某些历史数据时,往往需要人工干预进行同步
这时候,用户就希望能够有一种优雅的存储解决方案,来应付不同类型的工作流,并保持高性能的计算能力。Cloudera很早就意识到这个问题,在2012年就开始计划开发Kudu这个存储系统,终于在2015年发布并开源出来。Kudu是对HDFS和HBase功能上的补充,能提供快速的分析和实时计算能力,并且充分利用CPU和I/O资源,支持数据原地修改,支持简单的、可扩展的数据模型
2. 新的硬件设备
RAM的技术发展非常快,它变得越来越便宜,容量也越来越大。Cloudera的客户数据显示,他们的客户所部署的服务器,2012年每个节点仅有32GB RAM,现如今增长到每个节点有128GB或256GB RAM。存储设备上更新也非常快,在很多普通服务器中部署SSD也是屡见不鲜。HBase、HDFS、以及其他的Hadoop工具都在不断自我完善,从而适应硬件上的升级换代。然而,从根本上,HDFS基于03年GFS,HBase基于05年BigTable,在当时系统瓶颈主要取决于底层磁盘速度。当磁盘速度较慢时,CPU利用率不足的根本原因是磁盘速度导致的瓶颈,当磁盘速度提高了之后,CPU利用率提高,这时候CPU往往成为系统的瓶颈。HBase、HDFS由于年代久远,已经很难从基本架构上进行修改,而Kudu是基于全新的设计,因此可以更充分地利用RAM、I/O资源,并优化CPU利用率。我们可以理解为,Kudu相比与以往的系统,CPU使用降低了,I/O的使用提高了,RAM的利用更充分了。
3. 设计初衷
kudu设计的初衷为了解决如下问题:
- 对数据扫描(scan)和随机访问(random access)同时具有高性能,简化用户复杂的混合架构
- 高CPU效率,使用户购买的先进处理器的的花费得到最大回报
- 高IO性能,充分利用先进存储介质
- 支持数据的原地更新,避免额外的数据处理、数据移动
- 支持跨数据中心replication
Kudu的很多特性跟HBase很像,它支持索引键的查询和修改。Cloudera曾经想过基于Hbase进行修改,然而结论是对HBase的改动非常大,Kudu的数据模型和磁盘存储都与Hbase不同。HBase本身成功的适用于大量的其它场景,因此修改HBase很可能吃力不讨好。最后Cloudera决定开发一个全新的存储系统。
Kudu的定位是提供”fast analytics on fast data”,也就是在快速更新的数据上进行快速的查询。它定位OLAP和少量的OLTP工作流,如果有大量的random accesses,官方建议还是使用HBase最为合适。
二、基础概念
列式数据存储(Columnar Data Store)
阅读效率(Read Efficiency)
对于分析查询,允许读取单个列或该列的一部分同时忽略其他列
数据压缩(Data Compression)
由于给定的列只包含一种类型的数据,基于模式的压缩比压缩混合数据类型(在基于行的解决案中使用)时更有效几个数量级。结合从列读取数据的效率,压缩允许您在从磁盘读取更少的块时完成查询
Table
table是数据存储在 Kudu 的位置。表具有schema和全局有序的primary key(主键)。table被分成很多段,也就是称为tablets。
Tablet
一个tablet是一张table连续的segment,与其它数据存储引擎或关系型数据库的partition(分区)相似。给定的tablet冗余到多个tablet服务器上,并且在任何给定的时间点,其中一个副本被认为是leader tablet。任何副本都可以对读取进行服务,但是写入时需要在为tablet服务的一组tablet server之间达成一致性。
Tablet Server
一个tablet server存储tablet和为tablet向client提供服务。对于给定的tablet,一个tablet server充当 leader,其他tablet server充当该 tablet 的follower副本。只有leader服务写请求,然而leader或followers为每个服务提供读请求。leader使用Raft Consensus Algorithm来进行选举 。一个tablet server可以服务多个tablet,并且一个 tablet 可以被多个tablet servers服务着。
Master
master保持跟踪所有的tablets,tablet servers,Catalog Table 和其它与集群相关的metadata。在给定的时间点,只能有一个起作用的master(也就是 leader)。如果当前的 leader 消失,则选举出一个新的master,使用 Raft Consensus Algorithm来进行选举。
master还协调客户端的metadata operations(元数据操作)。例如,当创建新表时,客户端内部将请求发送给master。 master将新表的元数据写入catalog table,并协调在tablet server上创建 tablet 的过程。
所有master的数据都存储在一个 tablet 中,可以复制到所有其他候选的 master。
tablet server以设定的间隔向master发出心跳(默认值为每秒一次)。
master是以文件的形式存储在磁盘中,所以说,第一次初始化集群。需要设定好
Raft Consensus Algorithm
Kudu 使用 Raft consensus algorithm 作为确保常规 tablet 和 master 数据的容错性和一致性的手段。通过 Raft,tablet 的多个副本选举出 leader,它负责接受以及复制到 follower 副本的写入。一旦写入的数据在大多数副本中持久化后,就会向客户确认。给定的一组 N 副本(通常为 3 或 5 个)能够接受最多(N - 1)/2 错误的副本的写入。
Catalog Table
catalog table是Kudu 的 metadata(元数据中)的中心位置。它存储有关tables和tablets的信息。该catalog table(目录表)可能不会被直接读取或写入。相反,它只能通过客户端 API中公开的元数据操作访问。catalog table 存储两类元数据。
- Tables
table schemas, locations, and states(表结构,位置和状态)
- Tablets
现有tablet 的列表,每个 tablet 的副本所在哪些tablet server,tablet的当前状态以及开始和结束的keys(键)

三、设计架构
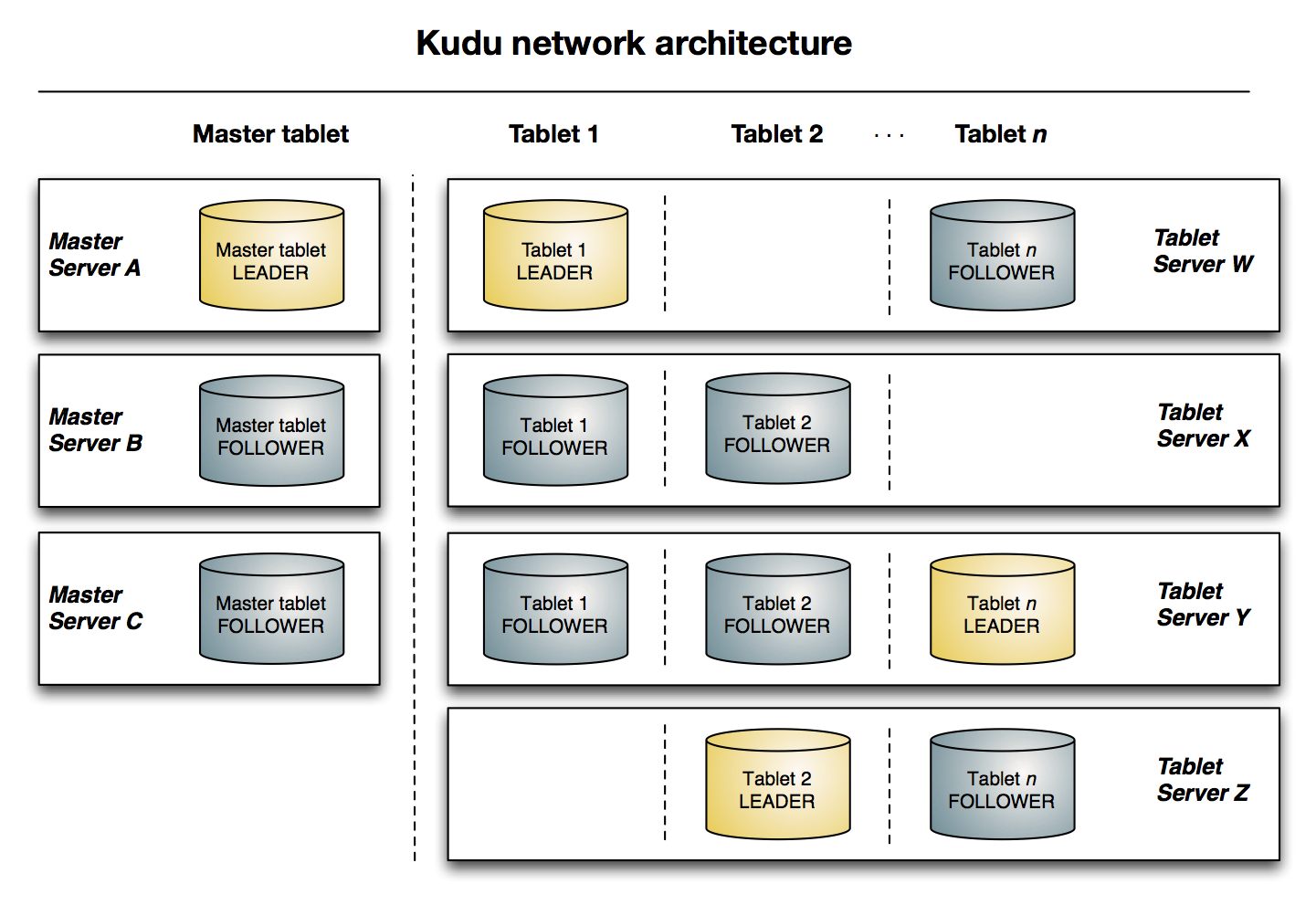
上图显示了一个具有三个 master 和多个tablet server的Kudu集群,每个服务器都支持多个tablet。它说明了如何使用 Raft 共识来允许master和tablet server的leader和follow。此外,tablet server 可以成为某些 tablet 的 leader,也可以是其他 tablet follower。leader以金色显示,而 follower 则显示为蓝色。
四、数据存储结构
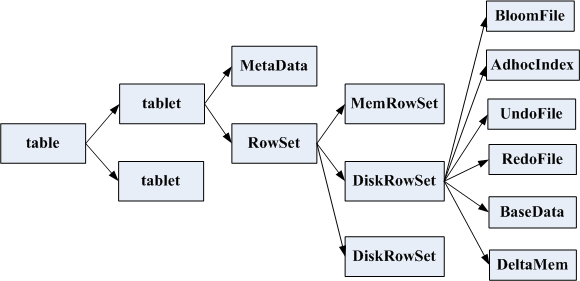
一张表会分成若干个tablet,每个tablet包括MetaData元信息及若干个RowSet,RowSet包含一个MemRowSet及若干个DiskRowSet,DiskRowSet中包含一个BloomFile、Ad_hoc Index、BaseData、DeltaMem及若干个RedoFile和UndoFile(UndoFile一般情况下只有一个)。
-
MemRowSet用于新数据insert及已在MemRowSet中的数据的更新,一个MemRowSet写满后会将数据刷到磁盘形成若干个DiskRowSet。
-
DiskRowSet用于老数据的mutation,后台定期对DiskRowSet做compaction,以删除没用的数据及合并历史数据,减少查询过程中的IO开销。
-
BloomFile根据一个DiskRowSet中的key生成一个bloom filter,用于快速模糊定位某个key是否在DiskRowSet中存在。
-
Ad_hoc Index是主键的索引,用于定位key在DiskRowSet中的具体哪个偏移位置。
-
BaseData是MemRowSet flush下来的数据,按列存储,按主键有序。
-
UndoFile是基于BaseData之前时间的历史数据,通过在BaseData上apply UndoFile中的记录,可以获得历史数据。
-
RedoFile是基于BaseData之后时间的mutation记录,通过在BaseData上apply RedoFile中的记录,可获得较新的数据。
-
DeltaMem用于DiskRowSet中数据的mutation,先写到内存中,写满后flush到磁盘形成RedoFile。
-
1. MemRowSet
MemRowSet的数据组织sss是一颗B+Tree,结构如下:
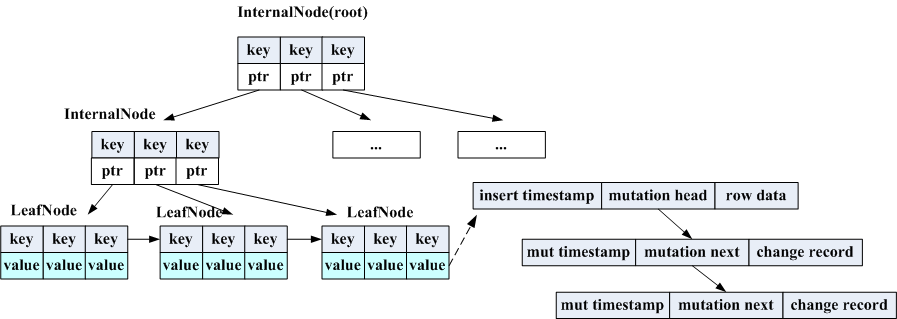
这颗B+树实现的比较简单,因为它没有update跟delete操作,kudu在MemRowSet中中数据的mutation采用类似append log方式,在base数据上有个mutation指针,所有的后续mutation操作都挂在这个指针上了。
虽然只有插入,但是也会出现节点满时需要做split,同时可能有读操作也在同步进行,kudu使用AtomicVersion(原子变量+位移)实现了一个锁。树的度跟cpu的CACHELINE_SIZE有关,是为了让一个节点仅读取一次cpu cache。
树的检索是先找到key所在的LeafNode,然后在LeafNode内部进行二分查找,LeafNode间有指针进行串联,为了方便scan,扫整个MemRowSet一般通过一个空串的key找到第一个LeafNode,然后依次读数据。
2. DiskRowSet
这部分是kudu存储部分最复杂的东西,分为两个部分来讲,DiskRowSet间的组织,DiskRowSet内数据组织,先看DiskRowSet间怎么组织的。
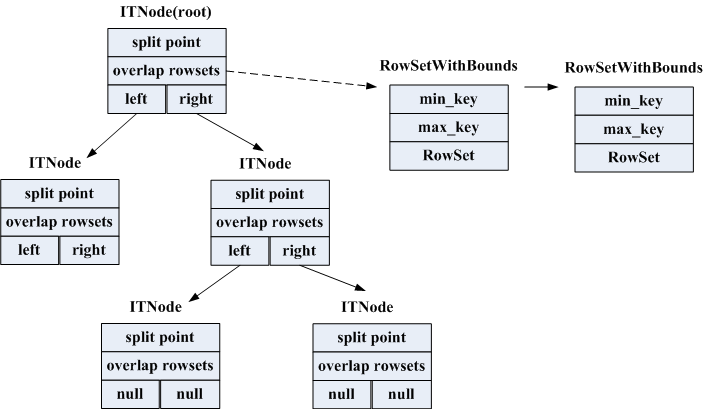
2.1 DiskRowSet间组织
一个tablet随这数据的不断写入会包含很多个DiskRowSet,每个DiskRowSet上有min_key、max_key标明key的范围,如果要查找一个key在哪个DiskRowSet上依次遍历每个DiskRowSet效率是很低的,这种情况线段树这种数据结构是很适合做range索引的,将所有的DiskRowSet形成一颗线段树,结构如下:
其实就是一个二叉平衡树,每次从所有range(最小的min_key跟最大的max_key)的中间key做split,将range跨域左右子树的DiskRowSet(即split point落在DiskRowSet的min_key与max_key之间)放到overlap rowsets中去。这颗树实现的也很简单,因为它只做查询用,生成后就不会变动,若遇到MemRowSet flush或DiskRowSet Merge Compaction就直接重新生成一颗新树。
这个树主要用于在读或写的时候定位某个或若干个key在哪些DiskRowSet的range范围内,只能通过DiskRowSet的min_key/max_key做一层模糊过滤,是否正在存在需要做进一步检查。
2.2 DiskRowSet内数据组织
一个DiskRowSet大体数据组织上面概述中已介绍过,其中DeltaMem跟MemRowSet在内存中的组织方式是一样的,都是B+Tree,而在磁盘上的存储都是放在CFile中的,下面我们看看CFile的文件格式:
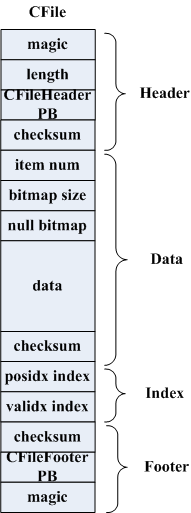
CFile包含Header、Data、Index、Footer几块,其中Data部分起始部分是为空值的条目建立的bitmap,仅针对可为null的column,对于主键是没有这个的,bitmap就是以那些值为null的RowId建立起来的位图,这样Data中就不用存这些空值。data部分不同的column类型文件会有不同的编码方式:
| Column Type | Encoding | default |
|---|---|---|
| int8,int16,int32 | plain,bitshuffle,run length | bitshuffle |
| int64,unixtime_micros | plain,bitshuffle,run length | bitshuffle |
| float,double,decimal | plain,bitshuffle | bitshuffle |
| bool | plain,run length | run length |
| string,binary | plain,prex,dictionary | dictionary |
对于ad_hoc文件使用的是prefix,delta file使用的是plain,bloomfile使用的是plain。每种BlockBuilder在处理一定量数据后就会append到Data中。
Index有两种,posidx_index是根据RowId找到在Data中的偏移,validx index是根据key的值找到在Data中的偏移,validx只针对只有一个column为key的情况,这个时候DiskRowSet没有Ad_hoc索引,使用validex来代替。这两个index内部实现是一个B-Tree,index不一定是连续的,在达到一定长度后就会刷盘,而内部可以区分是中间节点还是叶子节点及其孩子节点的位置。
Footer是记录了CFile的元信息,包括posidx_index、validx_index两棵树根节点所在位置,数据条目、编码、压缩方式等。
下面看看DiskRowSet数据在磁盘上的分布:
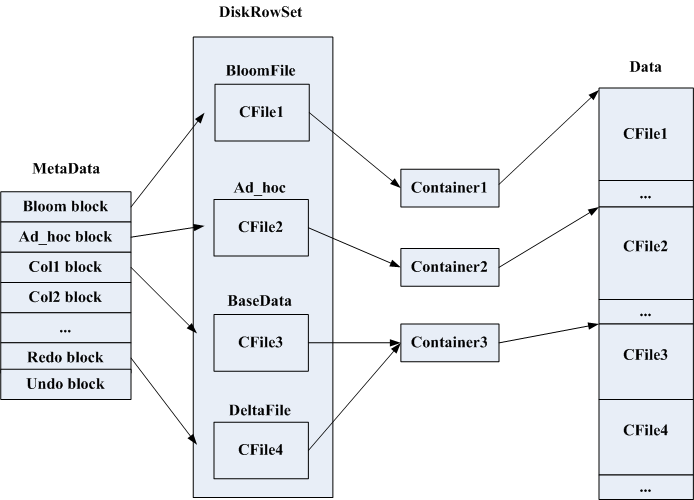
在磁盘上每个DiskRowSet有若干个.metadata及.data文件,metadata文件记录的是DiskRowSet的元信息,主要包括哪些block及block在data中的位置,上图为block与DiskRowSet中各部分的映射关系,在写磁盘是通过container来写,每个container可以写很大一块连续的磁盘空间,用于给某个CFile写数据,当一个CFile写完后会将container归还给BlockManager,这时container就可以用于下个CFile写数据了,当BlockManager中没有container可用时会新建一个container给新来的CFile使用。
对于新建block先看看有无container可用,若没有目前默认是在所有配置中的data_dir中随机选取一个dir中建一个新的metadata及data文件。先写data,block落盘后再写metadata。
五、表设计
kudu的表具有类似于传统RDBMS中的表的数据结构。schema设计对于实现Kudu的最佳性能和操作稳定性至关重要。
业务场景的多变,对于table来说并不存在一种最好的schema设计。
大部分情况下,创建kudu的表需要考虑三个问题:
- 列的设计(column design)
- 主键设计(primary key design)
- 分区设计(partitioning design)
比较好的Schema设计应该满足一下要求:
- 数据的分布和存储的方式满足:读取和写入操作都可以均匀的分散到tablet servers上(受分区影响)
- tablet将以均匀,可预测的速度增长,并且tablet server的负载将随着时间的推移保持稳定(受分区影响最大)
- 扫描将读取完成查询所需的最少数据量。(这主要受主键设计的影响,但分区也通过分区修剪发挥作用)
1. 列设计
一个kudu表由一列或多列构成,每列都需要指定一个类型。非主键的列允许为空。
kudu支持的类型包括:
- boolean
- 8-bit signed integer
- 16-bit signed integer
- 32-bit signed integer
- 64-bit signed integer
- unixtime_micros (64-bit microseconds since the Unix epoch)unix时间戳
- single-precision (32-bit) IEEE-754 floating-point number 单精度
- double-precision (64-bit) IEEE-754 floating-point number 双精度
- decimal
- UTF-8 encoded string (up to 64KB uncompressed)
- binary (up to 64KB uncompressed)
Kudu利用强类型列和柱状磁盘存储格式来提供高效的编码和序列化。要充分利用这些优势,应该为列指定一个合适的类型,而不是为了让表看起来结构化而强行让数据使用string or binary columns 。
除了编码之外,Kudu还允许在每列的基础上指定压缩方式。
==注意==
与Hbase不同,kudu没有提供一个version或者timestamp列来追踪行数据的变化。如果需要version或者timestamp,schema设计将包含一个明确的version或timestamp列。
1.1 十进制类型(Decimal Type)
十进制类型是一种数字数据类型,具有固定的比例和精度,适用于财务和其他算术计算,其中float和double的不精确表示和舍入行为使这些类型不切实际。十进制类型对于大于int64的整数和在主键中具有小数值的情况也很有用。
十进制类型是一种参数化类型,它拥有精度(Precision )和缩放(Scale )类型属性。
精度(Precision )
表示列可以表示的总位数,无论小数点的位置如何。此值必须介于1和38之间,并且没有默认值。
案例:
精度为4的能表示的最大整数为9999,或用两位小数表示最高的99.99,还可以表示相应的负值,而不会对精度进行任何更改。例如,-9999到9999的范围仍然只需要4的精度。
缩放(Scale )
表示小数的位数。该值必须介于0和精度之间。scale为0会产生整数值,没有小数部分。如果精度和比例相等,则所有数字都在小数点后面。
案例:
精度和小数等于3的小数可以表示介于-0.999和0.999之间的值。
性能考虑
Kudu将每个值存储在尽可能少的字节中,具体取决于为十进制列指定的精度。因此,为方便起见,不建议尽可能使用最高精度。
这样做可能会对性能、内存和存储产生负面影响。
不同精度的数据在内存占用的空间大小:
- Decimal values with precision of 9 or less are stored in 4 bytes. 9位以下的Decimal值存储需要4bytes空间
- Decimal values with precision of 10 through 18 are stored in 8 bytes. 10-18位的Decimal值存储需要8bytes空间
- Decimal values with precision greater than 18 are stored in 16 bytes. 大于18为的Decimal值存储需要16bytes空间
列的(precision)精度和(scale)缩放不能被修改表的语句更改。
1.2 列编码(Column Encoding)
kudu表中的每一列都会使用基于列的类型的编码。列的类型和编码的关系如下:
| Column Type | Encoding | default |
|---|---|---|
| int8,int16,int32 | plain,bitshuffle,run length | bitshuffle |
| int64,unixtime_micros | plain,bitshuffle,run length | bitshuffle |
| float,double,decimal | plain,bitshuffle | bitshuffle |
| bool | plain,run length | run length |
| string,binary | plain,prex,dictionary | dictionary |
下面对各个编码方式进行介绍:
- Plain Encoding
数据按照其原有的格式进行存储。比如:int32的值保存为固定大小为32字节的整数(fixed-size 32-bit little-endian integers)
- Bitshuffle Encoding
重新排列一个值的块,先存储每个值的最高有效位,然后是每个值的第二个最高有效位,依此类推。最后,结果是LZ4压缩。
Bitshuffle编码是具有许多重复值的列的理想选择,或者当按主键排序时会按少量更改的值。bitshuffle 项目对性能和用例有很好的描述。
- Run Length Encoding
Runs(连续重复值)压缩列的值通过存储值和值的计数。Run Length Encoding对按主键排序时具有许多连续重复值的列有效。
- Dictionary Encoding
构建唯一值的字典,并将每个列值编码为字典中的对应索引,字典编码对于基数较低的列有效。
如果由于唯一值的数量太大而无法压缩给定行集的列值,则Kudu将透明地回退到该行集的Plain Encoding。 这在冲洗期间(flush)进行评估
- Prefix Encoding
公共前缀以连续列值压缩。前缀编码对于共享公共前缀的值或主键的第一列可能有效,因为行按片中的主键排序。
1.3 列压缩(Column Compression)
kudu允许使用LZ4,Snappy,Zlib压缩编码器对每列进行压缩。默认,列是没有进行压缩的。如果减少存储空间比原始扫描性能更重要,请考虑使用压缩。
每个数据集的压缩方式都不同,但一般来说LZ4是性能最佳的编解码器,而zlib会压缩到最小的数据大小。Bitshuffle编码的列使用LZ4自动压缩,因此不建议在此编码的基础上应用额外的压缩。
2. 主键设计
kudu的每一个表都必须声明一个由一列或多列组成的主键。与RDBMS主键一样,Kudu主键强制执行唯一性约束。尝试插入具有与现有行相同的主键值的行将返回重复键错误。
主键列不能为空,且不能为boolean,float,或者double类型。表创建的过程中设置之后,主键列就不能变更改。
与传统的RDBMS不一样,kudu没有提供自增的主键列,在应用写入数据过程中,必须提供全部主键列的值。行删除和更新操作还必须指定要更改的行的完整主键。Kudu本身不支持范围删除或更新。插入行后,无法更新列的主键值。 但是,可以删除行并使用更新的值重新插入
2.1 主键索引
与许多传统型数据库一样,kudu的主键是分布式的索引。
存储在一个tablet里面的所有数据都按照主键进行排序。扫描kudu的行数据时候,在主键列上使用相等或范围谓词来有效地查找行。主键索引优化适用于单个tablet上的扫描。全局的优化考虑分区的设计
2.2 Backfill Inserts的注意事项(这部分文档理解还存在一些问题)
本节讨论时间序列用例的主键设计考虑因素,其中主键是时间戳,或者主键的第一列是时间戳。
每当有数据写入kudu表中的时候,kudu都会在primary key index storage 中查找primary key ,以检查primary key 在表中的是否已存在。
如果存在,就会返回一个duplicate key 的错误。
问题场景如下:
当前插入数据从数据源到达时候,只有少量的主键是hot的。因此,这些“检查存在”操作中的每一个都非常快。 它命中内存中的缓存主键存储,不需要转到磁盘。
在从离线数据源加载历史数据(称为“backfill inserts”)的情况下,插入的每一行都可能遇到主键索引的冷区域,该区域不驻留在内存中并且会导致一个或多个HDD磁盘搜索。
在正常情况下,Kudu每秒支持几百万次插入,“backfill inserts”用例可能每秒仅维持几千次插入。
为了缓解backfill inserts的性能问题,考虑下面的几条:
- 使主键更加容易压缩
案例:主键的第一列是32字节的随机ID,缓存十亿的主键则需要最少32gb的内存空间。如果从几天前开始缓存backfill inserts的主键,那么你需要数倍于32gb的内存空间。通过将主键更改为更易于压缩,可以增加主键适合缓存的可能性,从而减少随机磁盘I / O的数量。 - 使用SSD进行存储,因为随机搜索比旋转磁盘快几个数量级。(SSD比普通硬盘快)
- 更改主键结构,使backfill insets写入命中连续的主键范围。
3. 分区设计
分区字段一定是主键集合的子集。为了提升性能,kudu的表被划分为称为tablet的单元,并分布在多个tablet server中。
一行数据总是属于单个tablet。数据分配到tablet的方法是由在创建表的时候指定的分区方式决定的。
选择分区的策略需要理解数据模型、表的主要工作内容:
- 对于大量写入的工作,设计分区以使得写入工作分布到多个tablet上,避免单个tablet过载非常重要
- 对于大量短扫描(short scans)的工作,如果联系远程服务器的开销占主导地位,那么扫描的所有数据都在一个tablet就会提高性能。(短扫描、联系远程服务器的开销占主导地位不太明白)。
kudu不提供默认分区策略。
It is recommended that new tables which are expected to have heavy read and write workloads have at least as many tablets as tablet servers.
建议预计具有大量读写工作负载的新表至少具有与tablet servers一样多的tablets(如何操作?)
kudu提供了两种分区方式:范围分区和散列分区。表可以多级分区,多级分区集合了范围分区和散列分区,或者多个散列分区
3.1 范围分区
范围分区使用全序的范围分区键对数据行进行分配。(全序是指,集合中的任两个元素之间都可以比较的关系。比如实数中的任两个数都可以比较大小,那么“大小”就是实数集的一个全序关系。)
每个分区都是根据范围分区键分配的连续段。范围分区键必须是主键的子集。
如果表只存在范围分区,不存在散列分区,则每个分区恰好对应一个tablet。
初始化的分区在表创建时期被指定为一组分区边界和拆分点。对于每个边界,都会在表中创建分区对于。每次拆分,都会将分区拆分成两个分区。如果没有指定分区边界,则表将默认一个分区覆盖整个分区键空间。
范围分区必须始终不重叠,拆分行必须位于范围分区内。
kudu允许范围分区在运行时的动态增加和删除,而不会影响其他分区的可用性。
删除分区会同时把属于这个分区的全部tablet,属于这些tablet的所有数据都删除。这样会导致随后对这个分区的写入失败。
新的分区可以在运行时候增加,前提是这个新增加的分区和现存的分区不存在重叠。kudu允许在单个事物更改表的操作中新增或删除任意数量的范围分区。
动态的增加和删除分区对于时间序列的场景特别有用。可以增加新的范围分区以覆盖即将到来的时间范围。
案例:
一个存储时间日志的表可以增加月分区在该月开始之前用于存储该月份的事件日志数据。
有必要的话,可以根据分区去更加有效的删除数据
3.2 散列分区
散列分区是根据hash值把行数据分配到某个buckets里面。如果只是一层hash,则一个bucket对应一个tablet。
buckets的数量是在创建表的时候指定的。
散列分区使用的分区列是主键列,同范围分区,可以使用主键列的任意子集做分区。
散列分区是一种高效的策略,当不需要要有序的访问表的时候。
散列分区对在tablet之间的随机写入非常有效,这样有助于缓解tablet的热点问题和数据分布不均匀的问题。
如何选取散列的列,这样计算的hash值可以保证数据的均匀分配到bucket里面去?
3.3 多级分区
kudu允许在一个表中指定多级分区。零个或多个散列分区级别可以和可选的范围分区级别组合。多级分区与单个分区的区别是增加了约束条件,多级散列分区不能散列相同的列。(存在多级散列分区时候,各个散列分区计算散列值使用的列不能一样)如果使用正确,多级分区可以保留各个分区类型的好处,同时减少每个分区类型的缺点。多级分区表中的tablet总数是每个级别中分区数的乘积。
3.4 分区修剪(Partition Pruning)
当可以确定扫描关键字可以完全过滤分区时,Kudu扫描将自动跳过扫描整个分区。
- 要修剪散列分区,扫描必须在每个散列列上包含等式关键字。
- 要修剪范围分区,扫描必须在范围分区列上包含相等或范围关键字。
- 多级分区表上的扫描可以独立地利用任何级别上的分区修剪。
3.5 分区案例
了说明与为表设计分区的策略相关的因素和权衡,这里讲介绍一些分区方案。
建立一个用于存储计算机标准度量数据的表,表字段如下:
CREATE TABLE metrics (
host STRING NOT NULL,
metric STRING NOT NULL,
time INT64 NOT NULL,
value DOUBLE NOT NULL,
PRIMARY KEY (host, metric, time),
);
3.5.1 范围分区案例
通常对metrics进行范围分区的方式是使用time进行分区,如下图:
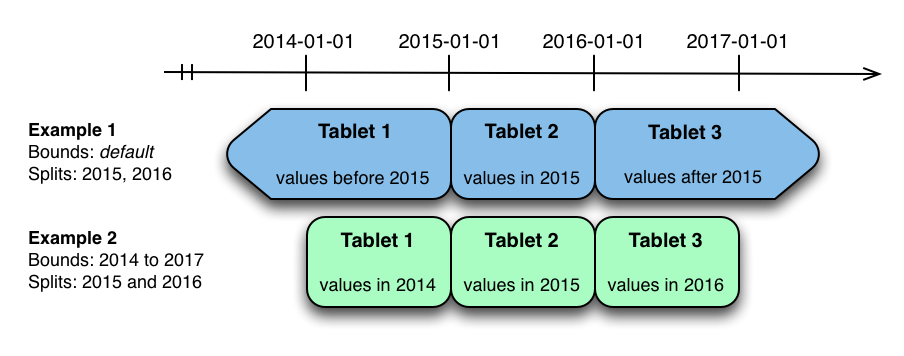
- 案例1:没有边界,用2015101和20160101分割数据,将数据分成了三块
- 案例2:有边界[(2014-01-01), (2017-01-01)],在2015-01-01 and 2016-01-01处分割
案例1和案例2都存在热点问题,数据写入的时候,都会写入同一个分区。
但是案例2比案例1更加灵活,案例1中当写入数据的实际超过20160101时候,全部数据会写入同一个分区,会造成分区过大,单个tablet无法存储。案例2则可以增加分区适应新写入的数据。
3.5.2 散列分区案例
对metrict进行分区的散列分区方法是:根据host和metrict进行分区,如下图:
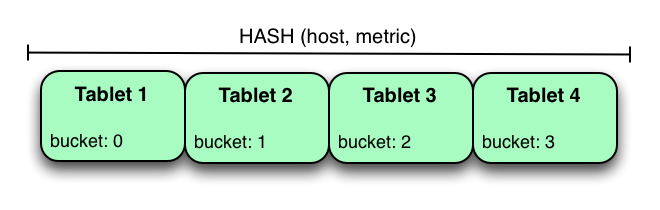
上面的案例中,metrict表按照host,metric散列分区,把数据写入到四个bucket中。与之前的范围分区不同,这个分区策略会把数据均匀地写入到各个tablet里面去。
扫描指定的host和metric可以充分得用到这种分区方式的优点,减少扫描的tablet数量。散列分布需要关注的一个问题是:当越来越多数据写入表中的时候,单个tablet的数据量会越来越大,最终tablet的数据会超过单个tablet server的存储。
3.5.3 范围分区和散列分区对比
| Strategy | Writes | Reads | Tablet Growth |
|---|---|---|---|
| range(time) | ✗ - all writes go to latest partition | ✓ - time-bounded scans can be pruned | ✓ - new tablets can be added for future time periods |
| hash(host, metric) | ✓ - writes are spread evenly among tablets | ✓ - scans on specific hosts and metrics can be pruned | ✗ - tablets could grow too large |
散列分区能最大化系统的吞吐量,范围分区则可以现在tablet无限增长的问题
3.5.4 范围分区和散列分区组合
如下图:
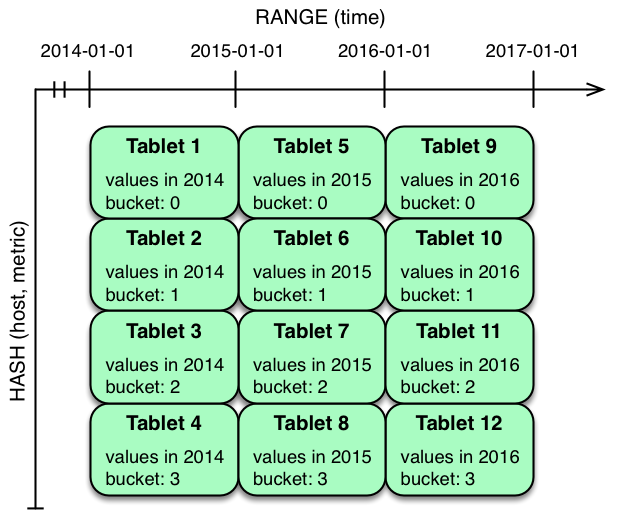
3.5.4 多级散列分区组合
如下图:
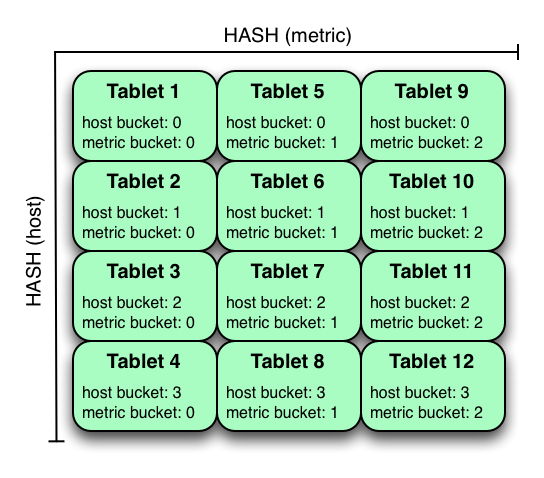
六、注意事项
1. 表模式修改(Schema Alterations)
- 表重命名
- 主键列重命名
- 重命名、增加、删除非主键列的列
- 增加和删除范围分区
可以在单个事物中组合多个修改操作
2. 限制(Known Limitations)
kudu现在有一些限制,可能会影响到你对Schema的设计
-
列的数量:表的列不要超过300,建议使用少一点的列以获取更好的性能
-
单元的大小:在编码或压缩之前,单个单元不得大于64KB。 在Kudu完成内部复合密钥编码之后,构成复合密钥的单元限制为总共16KB。 插入不符合这些限制的行将导致错误返回给客户端。
-
行的大小:虽然单个单元可能高达64KB,而Kudu最多支持300列,但建议单行不要大于几百KB。
-
有效的标识符:表名和列名等标识符必须是有效的UTF-8序列且不超过256个字节。
-
不可变的主键(Immutable Primary Keys):kudu不允许更新一行的主键列
-
不可更改的主键(Non-alterable Primary Key):Kudu不允许在创建表后更改主键列。
-
不可更改的分区(Non-alterable Partitioning):Kudu不允许在创建表后更改表的分区方式,删除和增加范围分区除外
-
不可更改的列类型(Non-alterable Column Types):Kudu不允许修改列的类型
-
分区拆分(Partition Splitting):在表创建之后不能拆分、合并分区
-
如果查询的WHERE子句包括与查询字段进行=,<=,<,>,> =,BETWEEN或IN的比较,则Kudu直接评估条件并仅返回相关结果。这提供了最佳性能,因为Kudu仅将相关结果返回给Impala。对于诸如!=,LIKE或Impala支持的任何其他谓词类型的谓词,Kudu不会直接评估谓词。 相反,它将所有结果返回给Impala,并依赖Impala来评估剩余的谓词并相应地过滤结果。 这可能会导致性能差异,具体取决于评估WHERE子句之前和之后结果集的增量。 在某些情况下,创建和定期更新实体化视图可能是解决这些低效问题的正确解决方案。
文章内容源于官网文档:http://kudu.apache.org/docs/index.html
最后
以上就是雪白招牌最近收集整理的关于❤️爆肝新一代大数据存储宠儿,梳理了2万字 “超硬核” 文章!❤️的全部内容,更多相关❤️爆肝新一代大数据存储宠儿,梳理了2万字内容请搜索靠谱客的其他文章。








发表评论 取消回复