一、Kudu概述
1.1 定义
Kudu 是一个针对 Apache Hadoop 平台而开发的列式存储管理器。
1.2 基础架构
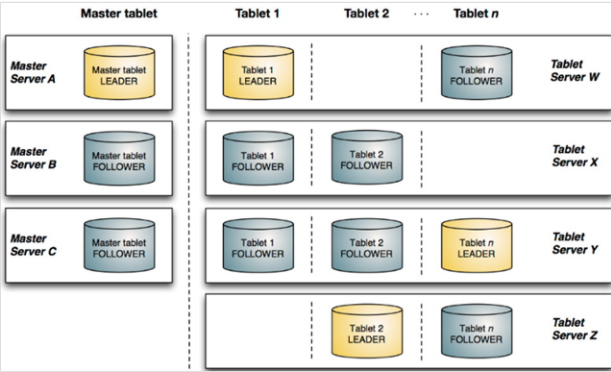
Kudu也采用了Master-Slave形式的中心节点架构,管理节点被称作Kudu Master,数据节点被称作Tablet Server(可对比理解HBase中的RegionServer角色)。一个表的数据,被分割成1个或多个Tablet,Tablet被部署在Tablet Server来提供数据读写服务。
Kudu Master在Kudu集群中,发挥如下的一些作用:
1. 用来存放一些表的Schema信息,且负责处理建表等请求。
2. 跟踪管理集群中的所有的Tablet Server,并且在Tablet Server异常之后协调数据的重部署。
3. 存放Tablet到Tablet Server的部署信息。
Tablet与HBase中的Region大致相似,但存在如下一些明显的区别点:
Tablet包含两种分区策略,一种是基于Hash Partition方式,在这种分区方式下用户数据可较均匀的分布在各个Tablet中,但原来的数据排序特点已被打乱。另外一种是基于Range Partition方式,数据将按照用户数据指定的有序的Primary Key Columns的组合String的顺序进行分区。而HBase中仅仅提供了一种按用户数据RowKey的Range Partition方式。
二、Kudu入门
2.1 配置impala支持kudu
2.1.1 点击impala
2.1.2 点击配置

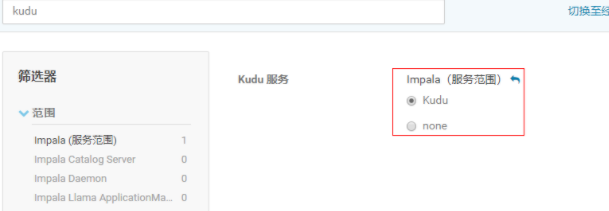
2.1.3 找到Kudu服务,选择Kudu后重启impala
2.2 使用案例
2.2.1 创建表
从 Impala 在 Kudu 中创建一个新表类似于将现有的 Kudu 表映射到 Impala 表,但需要自己指定模式和分区信息。
在 CREATE TABLE 语句中,必须首先列出构成主键的列。此外,主键列隐式标记为 NOT NULL 。
创建新的 Kudu 表时,需要指定一个分配方案。
CREATE TABLE kudu_table(
id INT,
name STRING,
PRIMARY KEY(id)
)
PARTITION BY HASH PARTITIONS 16
STORED AS KUDU;
2.2.2 查询 Impala 中现有的 Kudu 表
通过 Kudu API 或其他集成(如 Apache Spark )创建的表不会在 Impala 中自动显示。要查询它们,必须先在 Impala 中创建外部表以将 Kudu 表映射到 Impala 数据库中:
CREATE EXTERNAL TABLE my_mapping_table
STORED AS KUDU
TBLPROPERTIES (
'kudu.table_name' = 'kudu中的tableName'
);
2.2.3 使用 CREATE TABLE … AS SELECT 语句查询 Impala 中的任何其他表或来创建表。
以下示例将现有表 old_table 中的所有行导入到 Kudu 表 new_table 中。 new_table 中的列的名称和类型将根据 SELECT 语句的结果集中的列确定。
注意,必须另外指定主键和分区。
CREATE TABLE new_table
PRIMARY KEY (id)
PARTITION BY HASH(id) PARTITIONS 8
STORED AS KUDU
AS SELECT * FROM old_table;
2.2.4 不支持 Kudu 表的 Impala 关键字
创建 Kudu 表时不支持以下 Impala 关键字:
- PARTITIONED
- LOCATION
- ROW FORMAT
2.2.5 将数据插入 Kudu 表
Impala 允许使用 SQL 语句将数据插入 Kudu表 。
插入单个值:
INSERT INTO table_name VALUES (1001, "lsl");
插入多个值:
INSERT INTO table_name VALUES (1002, "zk"), (3, "hg");
插入其他表的值:
INSERT INTO table_name select * from other_table;
注意:kudu表的update操作不能更改主键的值,其他与标准SQL语法相同。
三、API操作
3.1 添加依赖
首先创建一个maven工程,添加一下依赖
<repositories>
<repository>
<id>cloudera</id>
<url>https://repository.cloudera.com/artifactory/cloudera-repos/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>org.apache.kudu</groupId>
<artifactId>kudu-client</artifactId>
<version>1.6.0-cdh5.14.4</version>
<scope>compile</scope>
</dependency>
</dependencies>
3.2 Kudu工具类增删改查
package com.wljs.kudu.utils;
import org.apache.kudu.ColumnSchema;
import org.apache.kudu.Schema;
import org.apache.kudu.Type;
import org.apache.kudu.client.*;
import java.util.ArrayList;
import java.util.List;
/**
* @program: kudu
* @description: Kudu工具类
* @author: lsl
* @create: 2019-12-30 16:41
**/
public class KuduUtils {
/**
* @Description:创建表
* @Param: [client, tableName]
* @return: void
* @Author: lsl
* @Date: 2019/12/30
*/
public static void createTable(KuduClient client, String tableName) {
List<ColumnSchema> columns = new ArrayList<>();
//在添加列时可以指定每一列的压缩格式
columns.add(new ColumnSchema.ColumnSchemaBuilder("id", Type.STRING).key(true).compressionAlgorithm(ColumnSchema.CompressionAlgorithm.SNAPPY).build());
Schema schema = new Schema(columns);
CreateTableOptions createTableOptions = new CreateTableOptions();
List<String> hashKeys = new ArrayList<>();
hashKeys.add("id");
int numBuckets = 8;
createTableOptions.addHashPartitions(hashKeys, numBuckets);
try {
if(!client.tableExists(tableName)) {
client.createTable(tableName, schema, createTableOptions);
}
System.out.println("成功创建Kudu表:" + tableName);
} catch (KuduException e) {
e.printStackTrace();
}
}
/**
* @Description:删除表
* @Param: [client, tableName]
* @return: void
* @Author: lsl
* @Date: 2019/12/30
*/
public static void dropTable(KuduClient client, String tableName) {
try {
client.deleteTable(tableName);
} catch (KuduException e) {
e.printStackTrace();
}
}
/**
* @Description:列出Kudu下所有的表
* @Param: [client]
* @return: void
* @Author: lsl
* @Date: 2019/12/30
*/
public static void tableList(KuduClient client) {
try {
ListTablesResponse listTablesResponse = client.getTablesList();
List<String> tblist = listTablesResponse.getTablesList();
for(String tableName : tblist) {
System.out.println(tableName);
}
} catch (KuduException e) {
e.printStackTrace();
}
}
/**
* @Description:向指定的Kudu表中插入数据
* @Param: [client, tableName, numRows]
* @return: void
* @Author: lsl
* @Date: 2019/12/30
*/
public static void insert(KuduClient client, String tableName, String key,String value ) {
KuduSession kuduSession = null;
try {
KuduTable kuduTable = client.openTable(tableName);
kuduSession = client.newSession();
//采取Flush方式 手动刷新
kuduSession.setFlushMode(SessionConfiguration.FlushMode.MANUAL_FLUSH);
kuduSession.setMutationBufferSpace(3000);
Insert insert = kuduTable.newInsert();
insert.getRow().addString("key",key);
insert.getRow().addString("value",value);
kuduSession.flush();
kuduSession.apply(insert);
} catch (KuduException e) {
e.printStackTrace();
}finally {
try {
kuduSession.close();
} catch (KuduException e) {
e.printStackTrace();
}
}
}
/**
* @Description:删除表中的信息
* @Param: [client, tableName, key]
* @return: void
* @Author: lsl
* @Date: 2019/12/30
*/
public static void delete(KuduClient client, String tableName, String key) {
KuduSession kuduSession = null;
try {
KuduTable kuduTable = client.openTable(tableName);
kuduSession = client.newSession();
Delete delete = kuduTable.newDelete();
delete.getRow().addString("key",key);
kuduSession.flush();
kuduSession.apply(delete);
} catch (KuduException e) {
e.printStackTrace();
}finally {
try {
kuduSession.close();
} catch (KuduException e) {
e.printStackTrace();
}
}
}
/**
* @Description:修改表中的信息
* @Param: [client, tableName, key]
* @return: void
* @Author: lsl
* @Date: 2019/12/30
*/
public static void update(KuduClient client, String tableName, String key, String value) {
KuduSession kuduSession = null;
try {
KuduTable kuduTable = client.openTable(tableName);
kuduSession = client.newSession();
Update update = kuduTable.newUpdate();
update.getRow().addString("key",key);
update.getRow().addString("value",value);
kuduSession.flush();
kuduSession.apply(update);
} catch (KuduException e) {
e.printStackTrace();
}finally {
try {
kuduSession.close();
} catch (KuduException e) {
e.printStackTrace();
}
}
}
/**
* @Description:查看Kudu表中数据
* @Param: [client, tableName]
* @return: void
* @Author: lsl
* @Date: 2019/12/30
*/
public static void scanerTable(KuduClient client, String tableName) {
try {
KuduTable kuduTable = client.openTable(tableName);
KuduScanner kuduScanner = client.newScannerBuilder(kuduTable).build();
while(kuduScanner.hasMoreRows()) {
RowResultIterator rowResultIterator =kuduScanner.nextRows();
while (rowResultIterator.hasNext()) {
RowResult rowResult = rowResultIterator.next();
System.out.println(rowResult.getString("key"));
System.out.println(rowResult.getString("value"));
}
}
kuduScanner.close();
} catch (KuduException e) {
e.printStackTrace();
}
}
}
3.3 测试
package com.wljs.kudu.start;
import com.wljs.kudu.utils.KuduUtils;
import org.apache.kudu.client.KuduClient;
import org.apache.kudu.client.KuduException;
/**
* @program: kudu
* @description:
* @author: lsl
* @create: 2019-12-30 16:52
**/
public class KuduStart {
public static void main(String[] args) {
//master地址
String masteraddr = "hadoop01,hadoop02,hadoop03";
//创建kudu的数据库链接
KuduClient client = new KuduClient.KuduClientBuilder(masteraddr).build();
//KuduUtils.createTable(client,"kudu_table");
//KuduUtils.tableList(client);
//KuduUtils.dropTable(client,"kudu_table");
//KuduUtils.insert(client,"simple","C","3");
//KuduUtils.delete(client,"simple","C");
//KuduUtils.update(client,"simple","B","4");
//KuduUtils.scanerTable(client,"simple");
}
}
3.4 核心类总结
Client:
- KuduClient
对AsyncKuduClient的封装,具有同步、线程安全性。 - AsyncKuduClient
线程安全的客户端类,完全异步操作。该类应该只实例化一次。同时访问很多表。如果操纵多个不同集群才需 要实例化多次。不会阻塞操作,可以关联回调函数用于操作完成时。
Schema
表示表结构,主要是column的集合。该类提供了一些工具方法用于查询操作。
ColumnSchema
表示一column,使用builder构建。
CreateTableOptions
Builder模式类,用于创建表。
KuduTable
表示集群上的一张表。含有当前表结构信息,隶属于特定AsyncKuduClient。
Session
- AsyncKuduSession
隶属于特定KuduClient,代表一个环境,所有写操作都会在该环境中进行。在一个session,可以对多个操作 进行累计按批处理方式进行,可以获得较好的性能。每个session都可以设置超时、优先级以及跟踪id等信息。 session和KuduClient是独立的,主要是在多线程环境下,不同线程需要并发执行事务,事务的边界是基于每 个session的BeginTransaction和commit之间的过程。 来自于不同session的写操作不会组织到一个RPC请求batch中,意味着延迟敏感的客户端(低延迟)和面向吞 吐量的客户端(高延迟)使用同一KuduClient,每个Session中可以设置特定的超时和优先级。 - KuduSession
对AsyncKuduSession同步封装,以阻塞的,不是线程安全的。
PartialRow
表示一行的部分列。
KuduScanner
扫描对象,用户条件查询。
四、Schema设计
创建Kudu表时,涉及到列设计、主键设计和分区设计。对于传统的非分布式关系型数据库来讲,只有分区是新概 念。而对于kudu最佳性能和操作的稳定性来讲,schema的设计至关重要,并且没有哪一种schema能够适用所有的表
4.1 如何判断好的Schema
好的schema应该具备以下条件:
- 数据的读写均匀分布到每个tablet server,这一点主要受到分区的影响。
- tablet能够以稳定、可预测的速率增加,加载的数据保证全天候可用,这主要受到分区的影响。
- 扫描时读取最少的数据量,这一点主要受主键设计的影响,但分区也会起到重要作用。
- 好的shema设计依赖于数据特征、对数据操作什么以及集群的拓扑结构。Schema设计对于kudu集群性能最大化来说是最重要的事情。
4.2 Column设计
4.2.1 数据类型
Kudu表包含多个列,每个列都有类型,非主键列可以为null。支持的列类型有:
布尔
- 8位有符号整数
- 16位有符号整数
- 32位有符号整数
- 64位有符号整数
- unixtime_micros(Unix时代以来的64位微秒)
- 单精度(32位)IEEE-754浮点数
- 双精度(64位)IEEE-754浮点数
- 十进制(详见十进制类型)
- UTF-8编码字符串(最多64KB未压缩)
- 二进制(最多64KB未压缩)
Kudu利用强类型列和列式磁盘存储格式来提供高效的编码和序列化。为了充分利用这些功能,应将列指定为适当的类型,而不是使用字符串或二进制列来模拟“无模式”表。除了编码之外,Kudu还允许在每列的基础上指定压缩。
4.2.2 Decimal类型
该类型是具有固定标度和精度适合于金融等算术运算,float与double的不精确表示和舍入行为比较不切实际。该 decimal类型对于大于int64的整数和主键中具有小数值的情况也很有用。
4.3 列编码
可以根据列的类型进行编码。
| 列类型 | 编码 | 默认 |
|---|---|---|
| int8, int16, int32 | plain, bitshuffle, run length | bitshuffle |
| int64, unixtime_micros | plain, bitshuffle, run length | bitshuffle |
| float, double, decimal | plain, bitshuffle | bitshuffle |
| bool | plain, run length | run length |
| string, binary | plain, prefix, dictionary | dictionary |
- Plain encoding
数据以其自然格式存储。例如,int32值存储为固定大小的32位little-endian整数。 - Bitshuffle
编码重新排列一个值块以存储每个值的最高有效位,然后是第二个最高有效位,依此类推。最后,结果进行LZ4压缩。 如果值重复的比较多,或者按主键排序时值的变化很小,Bitshuffle编码是一个不错的选择。 - run length 运行长度编码
对连续的重复值采用压缩存储,主要是通过只存储值和个数。该编码对按主键排序时具有许多连续重复值的列有效。 - dictionary 字典编码
创建一个字典存放所有的值,每个列值使用索引进行编码存储。如果值的个数较少,这种方式比较有效。反之则 Kudu将透明地回退到该行集的纯编码。这在flush期间进行评估计算。 - prefix 前缀编码
在连续的列值中对公共前缀进行压缩。对于有公共前缀的值或主键的第一列或许有效,因为tablet中的行是通过对 主键排序存储的。
4.4 列压缩
Kudu允许列使用压缩LZ4、Snappy或zlib压缩编解码器。默认情况下,不进行压缩。如果减少存储空间比原始扫描性能更重要,请考虑使用压缩。
每个数据集的压缩方式都不同,但一般来说LZ4是性能最佳的编解码器,而zlib空间压缩比较大。Bitshuffle编码的列自动使用LZ4压缩,因此不建议在此编码之上应用其他的压缩。
4.5 主键设计
每个Kudu表必须声明由一列或多列组成的主键。与RDBMS主键一样,Kudu主键强制执行唯一性约束。尝试插入 具有与现有行相同的主键值的行将导致重复键错误。主键列必须是非可空的,并且不可以是boolean,float或double类型。 表创建指定主键后,就不能更改。 与RDBMS不同,Kudu不提供列的自增,因此应用程序必须提供完整的主键。 删除和更新时必须指定完整主键。Kudu本身不支持范围删除或更新。即都是通过主键完成操作。 主键值无法修改。但是,可以删除后重新插入。
4.5.1 主键索引
与许多传统的关系数据库一样,Kudu的主键是聚簇索引(B+树)。tablet中的所有行都按主键排序的。 扫描Kudu行时,在主键列上使用相等或范围过滤可以有效地查找行。
4.5.2 回填插入
这里考虑主键是时间戳或主键的第一列是时间戳的情况。每次插入,kudu都会主键索引存储区域中查找主键看主 键是否存在,如果存在,就返回主键重复错误。如果以数据产生的时间作为主键存储,则热点数据就比较少,执行 存在性检查时就会比较快,在内存中就可以命中,不需要走磁盘。
如果是离线的历史数据,每次插入都可能会预冷(主键无法在内存中定位),就会访问磁盘,有时甚至是多个磁 盘。正常情况下,kudu可以达到每秒几百万次插入,但是如果是回填数据的话,每秒只能维持几千的插入量。
回填数据的性能优化:
- 使主键更易压缩 。
- 使用固态盘 。
- 改变主键结构,使回填主键位于连续的范围中。
4.6 分区设计
kudu中的表被分成很多tablet分布在多个tserver上。每一行属于一个tablet。行划分到哪个tablet由分区决定,分区是在表创建期间设置的。写入频繁时,考虑将写入动作平衡到所有tablet之间能够有效降低单个tablet的压力,对于小范围扫描操作比较多 的情况,如果所扫描的数据都为一个tablet上则可以提高性能。 kudu没有默认分区,建表时,kudu不提供默认的分区策略。建议读写都较重的table可以设置和tserver服务器数量相同的分区数。kudu提供两种类型的分区:范围分区和哈希分区。表可以有多级分区,组合使用范围和哈希或者多个哈希组合使用。
4.6.1 范围分区
Kudu允许在运行时动态添加和删除范围分区,而不会影响其他分区的可用性。删除分区将删除属于该分区的服务器以及其中包含的数据。后续插入到已删除的分区中将失败。可以添加新分区,但它们不得与任何现有范围分区重叠。Kudu允许在单个事务更改表操作中删除和添加任意数量的范围分区。动态添加和删除范围分区对于时间序列特别有用。随着时间的推移,可以添加范围分区以覆盖即将到来的时间范围。例如,存储事件日志的表可以在每个月开始之前添加月份分区,以便保存即将发生的事件。可以删除旧范围分区,以便根据需要有效地删除历史数据。
4.6.2 哈希分区
哈希分区按哈希值将行分配到存储桶中的一个。在单级散列分区表中,每个桶只对应一个tablet。在表创建期间设置桶的数量。通常,主键列用作要散列的列,但与范围分区一样,可以使用主键列的任何子集。 当不需要对表进行有序访问时,散列分区是一种有效的策略。散列分区对于在服务器之间随机写入非常有效,这 有助于缓解热点和不均匀的服务器大小。
4.6.3 多级分区
Kudu允许表在单个表上组合多个级别的分区。零个或多个哈希分区可以与范围分区组合。除了各个分区类型的约束之外,多级分区的唯一附加约束是多级哈希分区不能散列相同的列。 如果使用正确,多级分区可以保留各个分区类型的好处,同时减少每个分区类型的缺点。多级分区表中的服务器总数是每个级别中分区数的乘积。
4.6.4 修剪分区
当通过扫描条件能够完全确定分区的时候,kudu就会自动跳过整个分区的扫描。要确定哈希分区,扫描条件必须 包含每个哈希列的等值判定条件。多级分区表的扫描可以单独利用每一级的分区界定。
最后
以上就是贪玩小馒头最近收集整理的关于Kudu教程一、Kudu概述二、Kudu入门三、API操作四、Schema设计的全部内容,更多相关Kudu教程一、Kudu概述二、Kudu入门三、API操作四、Schema设计内容请搜索靠谱客的其他文章。








发表评论 取消回复